一、Spring Cloud Sleuth介绍
1、分布式服务跟踪必要性
现今互联网环境中,微服务系统越来越庞大、复杂,微服务间的调用关系也越加复杂。往往一个请求,会出发系统后台多个微服务协同工作得到最终结果,那么在复杂的调用网中,任何一个服务出现问题,都会导致整体功能出错。
这时,微服务跟踪工具应运而生,其在整体微服务应用中能跟踪一个请求的整体流程。并提供数据采集,数据传输,数据存储,数据分析,数据可视化功能。微服务跟踪工具捕获的这些跟踪数据,就能构建出整个微服务调用链视图,为调试和监控微服务系统提供帮助。
Spring Cloud Sleuth就是这样的微服务跟踪工具。其特点为:
提供链路追踪:通过Sleuth可以很清楚的看到一次请求经过哪些服务调用,可以方便理清服务间调用关系。
性能分析、数据分析、优化链路:通过Sleuth可以很方便的看出每个采样请求的耗时,分析出哪些服务调用比较耗时,可以为微服务系统的调优提供数据支撑。
可视化视图:可以提供可视化视图,更直观的查看采样数据。
2、基于ELK收集分布式微服务跟踪数据
Sleuth是基于logback实现数据跟踪的。在默认情况下,Sleuth是基于日志向控制台输出跟踪内容。不利于管理,统计,查看,分析。在控制台中输出跟踪内容会严重影响系统性能。如果将跟踪数据记录在logback对应的日志文件中,也有问题:logback是分散的,是集成在每个服务应用中的,那么日志文件也是分散的, 也不利于跟踪信息的查看,管理,分析。
所以Sleuth提供了集中式的跟踪数据存储方案。可以使用ELK来实现logback跟踪信息的收集,存储。实质上是使用logstash来做数据的收集,用ElasticSearch做数据的存储,使用Kibana做数据的视图显示。
使用ELK收集跟踪数据,必须依赖Logback日志工具,也就是必须提供logback.xml配置文件,并且日志级别建议调整为DEBUG。
2.1 结构图
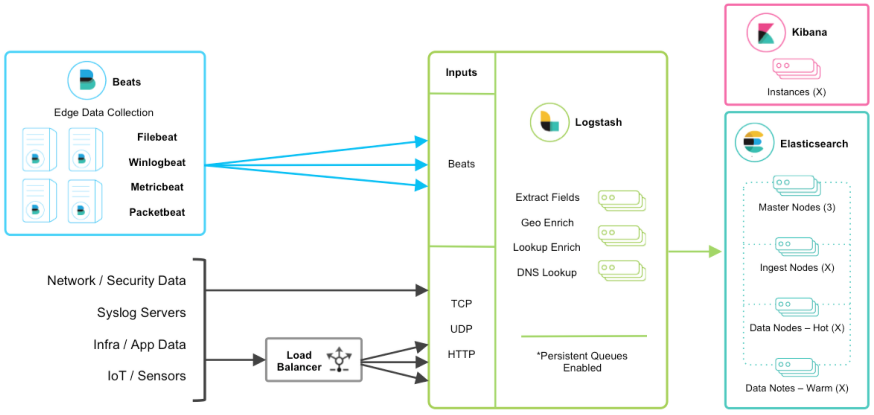
2.2 搭建过程
2.2.1 LogStash配置
连接LogStash容器:
docker exec -it logstash bash
编辑配置文件:
vi /usr/share/logstash/pipeline/logstash.conf
具体内容如下:
| input { tcp { mode => “server” port => 4560 } } filter { } output { elasticsearch { action => “index” #The operation on ES hosts => “192.168.137.128:9200” #ElasticSearch host, can be array. index => “bjsxt_sleuth” #The index to write data to. } } |
|---|
2.2.2 重启Logstash容器
2.2.3 修改微服务应用
2.2.3.1 新增依赖
在需要跟踪微服务信息的应用中增加下述依赖
2.2.3.2 提供logback配置
在需要跟踪微服务信息的应用中增加下述配置,配置文件命名为logback.xml,所在位置是classpath。
<?xml version="1.0" encoding="UTF-8"?><!--该日志将日志级别不同的log信息保存到不同的文件中 --><configuration><include resource="org/springframework/boot/logging/logback/defaults.xml" /><springProperty scope="context" name="springAppName"source="spring.application.name" /><!-- 日志在工程中的输出位置 --><property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}" /><!-- 控制台的日志输出样式 --><property name="CONSOLE_LOG_PATTERN"value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" /><!-- 控制台输出 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>INFO</level></filter><!-- 日志输出编码 --><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><!-- 为logstash输出的JSON格式的Appender --><appender name="logstash"class="net.logstash.logback.appender.LogstashTcpSocketAppender"><destination>192.168.137.128:4560</destination><!-- 日志输出编码 --><encoderclass="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp><timeZone>UTC</timeZone></timestamp><pattern><pattern>{"severity": "%level","service": "${springAppName:-}","trace": "%X{X-B3-TraceId:-}","span": "%X{X-B3-SpanId:-}","exportable": "%X{X-Span-Export:-}","pid": "${PID:-}","thread": "%thread","class": "%logger{40}","rest": "%message"}</pattern></pattern></providers></encoder></appender><!-- 日志输出级别 --><root level="DEBUG"><appender-ref ref="console" /><appender-ref ref="logstash" /></root></configuration>
2.2.3.3 特殊情况
如果项目中有其他与Redis相关的项目,则需要在项目启动类型上增加注解属性,具体如下:
| @SpringBootApplication(exclude = {TraceRedisAutoConfiguration.class}) @EnableFeignClients @EnableDistributedTransaction public class FrontendSearchApplication { public static void main(String[] args) { System.setProperty(“es.set.netty.runtime.available.processors”, “false”); SpringApplication.run(FrontendSearchApplication.class,args); } } |
|---|
原因:Sleuth也可以监听Redis数据库的访问流程。当项目中有和Redis相关的操作启动器时(如spring session),则会因为两个技术相互抢占Redis访问锁,造成死锁逻辑,最终导致访问Redis服务器超时,此时关闭Sleuth自带的Redis数据库自动装配即可解决问题。
上述所有步骤操作完毕后,使用ELK实现跟踪数据收集的案例就改造完毕了,可以启动并观察ElasticSearch中对应索引的内容。
2.3 索引中数据含义
查看跟踪数据的时候,可以根据索引中字段message搜索,主要观察的是包含Trace相关内容的数据,数据格式如下:
| { “@timestamp”:”2018-11-21T14:26:31.264+00:00”, #时间戳 “severity”:”DEBUG”, # 收集的跟踪数据日志级别 “service”:”e-book-user-provider”, # 当前跟踪的服务名称 “trace”:”c82b2d23e6c3245b”, # 一个请求的完整链路唯一标记 “span”:”95b7128dec20f57f”, # 一个请求中某一执行节点的唯一标记 “exportable”:”false”, “pid”:”8144”, # 进程编号 “thread”:”http-nio-9002-exec-8”, # 线程名称 “class”:”o.s.c.sleuth.instrument.web.TraceFilter”, # 记录日志的类名 “rest”: “” # 具体的执行消息 } |
|---|
二、使用Zipkin实现分布式跟踪
1 、ZipKin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
2 、Zipkin执行原理图
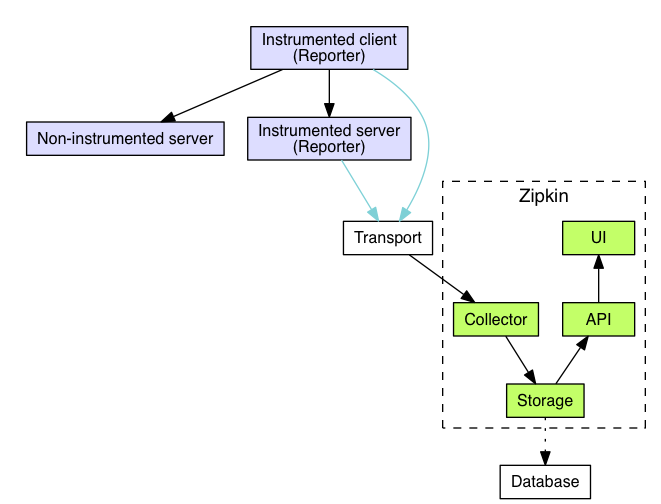
Collector 收集器、Storage 存储、API、UI 用户界面等几部分构成了 Zipkin Server 部分
3 、基于Docker搭建Zipkin
Zipkin2.x版本以后,官方不推荐自定义提供Zipkin服务器。建议使用官方提供的Docker镜像搭建。具体步骤如下:
3.1 下载镜像
3.2 创建容器
docker run -d —name zipkin-server -p 9411:9411 openzipkin/zipkin
zipkin官方提供的镜像默认占用端口9411
3.3 检查容器状态
4 、修改被收集跟踪信息的微服务应用
使用Sleuth采集跟踪数据的服务应用不需要在代码层面做任何改动,Sleuth|zipkin是一个高度封装的应用工具,提供依赖资源和配置信息即可。
在所有需要使用Sleuth|zipkin采集跟踪数据的服务应用统一修改下述内容。
4.1 pom依赖
增加下述依赖:
| <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-rabbit</artifactId> </dependency> |
|---|
4.2 修改配置文件
配置文件增加下述配置。
| spring: rabbitmq:
host: 192.168.137.128
port: 5672
username: bjsxt
password: bjsxt
zipkin:
base-url: http://192.168.137.128:9411/
**sender**:<br /> **type**: _web<br /> _**sleuth**:<br /> **sampler**:<br /> **probability**: 1 |
| —- |
4.3 删除logback配置
如果应用曾经使用logback+ELK收集服务数据,则需要删除logback配置文件。
上述内容修改完毕后,重新启动微服务即可。
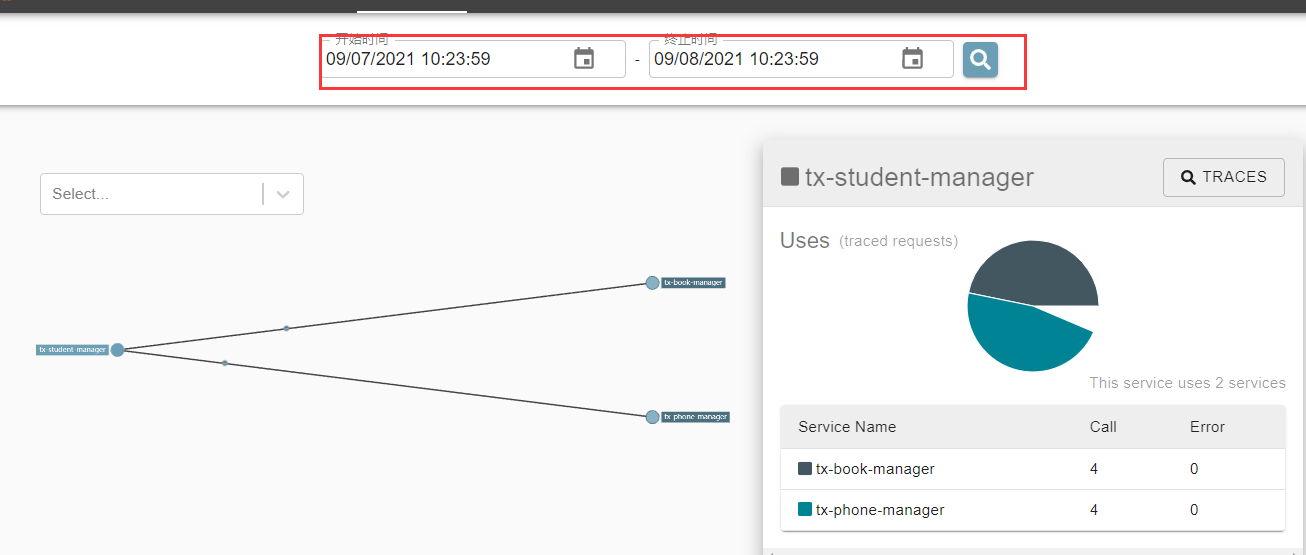
5 、基于Zipkin观察跟踪数据
使用浏览器访问Zipkin服务端应用。地址是:
http://ip:9411/zipkin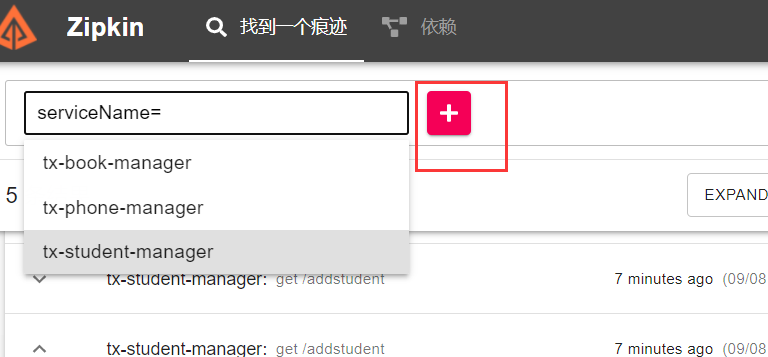

若有收获,就点个赞吧
0 人点赞
