一、 哈希表
1. 哈希表的结构特点
hashtable(散列表)
特点:快
结构:顺序表+链表
主结构:顺序表,在每个顺序表的节点再单独引出一个链表。
2. hashCode和equals作用:
hashCode()计算哈希码,是一个整数,根据哈希码可以计算出在哈希表中的数据的位置。
equals()添加时出现了冲突,需要通过equals进行比较,判断是否相同;查询时也需要使用equals进行比较,判断是否相同。
3. 各种类型的数据获取hashCode的方式:
int取自身,看Integer的源码
double同上,看Double的源码
String 将各个字符串的Acall码值按照权重相加
4. 装填因子
装填因子=表中的记录数/哈希表的长度
如果装填因子越小,表明表中还有很多的空单元,则添加发生冲突的可能性就越小;而装填因子越大,则发生冲突的可能性就越大,在查找所耗费的时间就越多。当装填因子在0.5的时候,Hash性能能够达到最优。
因此,一般情况下,装填因子取经验值0.5
Map集合的基本使用
Map(接口)extends Object
子类: HashMap TreeMap LinkedHashMap
特点:key 是唯一的 Value是可以重复的
常用方法:
put();放入键值对
set();取出键
get();获取键值对
clear();集合清除
remove();元素移除
replace();元素替换操作
containsKey();判断当前集合中是否包含我们指定key 的键值对
containValue();判断当前集合中是否包含我们指定value的键值对
isEmpty();判断当前集合是否为空
| new对象 | 分配了内存空间,值为空,是绝对的空,是一种有值(值 = 空) |
|---|---|
| “” | 分配了内存空间,值为空字符串,是相对的空,是一种有值(值 = 空字串) |
| null | 是未分配内存空间,无值,是一种无值(值不存在) |
size();返回键值对的个数
import java.util.*;public class HashMapTest {public static void main(String[] args) {Map<Integer,String> map=new HashMap<>();Map<Integer,String> map1=new TreeMap<>();Map<Integer,String> map2=new LinkedHashMap<>();map.put(111,"sxt");//存入元素map.put(112,"bjsxt");map.put(113,"sxtbjsxt");String a=map.get(112);//获取键为112的值赋值给aSet<Integer> set=map.keySet();//将map中的key保存到集合set中for (Integer i:set) { //遍历map集合System.out.println(i+"---------"+map.get(i));}System.out.println(set);map.remove(111);//移除map.replace(112,"bjsxtsxtsxt");//替换boolean flag=map.isEmpty();//判断当前集合是否为空boolean flag1=map.containsKey(113); //是否包含指定键boolean flag2=map.containsValue("sxt");int s=map.size();//键值对个数map.clear();//清空集合}}
二、Map
1. HashMap
• JDK1.7及其之前,HashMap底层是一个table数组+链表实现的哈希表存储结构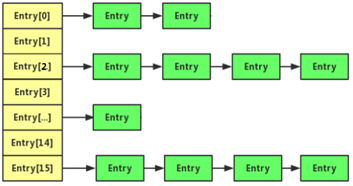
• 链表的每个节点就是一个Entry,其中包括:键key、值value、键的哈希码hash、执行下一个节点的引用next四部分
• 在JDK1.8中有一些变化,当链表的存储数据个数大于等于8的时候,不再采用链表存储,而采用红黑树存储结构。这么做主要是查询的时间复杂度上,链表为O(n),而红黑树一直是O(logn)。如果冲突多,并且超过8长度小于6 会自动转成链表结构,采用红黑树来提高效率
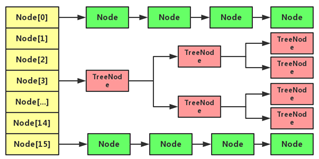
前 1.7 是 Entry 结点,1.8 则是Node 结点,其实相差不大,因为都是实现了 Map.Entry (Map 接口中的 Entry 接口)接口,即,实现了 getKey() , getValue() , equals(Object o )和 hashCode() 等方法;
1.1 HashMap:底层是hash表
- key是唯一的,如果key是重复的,后者就会把前者覆盖
- 允许key是null
- Jdk1.7的时候哈希表采用的是 数组+链表的方式实现的
- Jdk1.8及之后哈希表采用的是 数组+链表+红黑树的方式实现的
1.2 基本用法
```java import java.util.*;
public class HashMapTest {
public static void main(String[] args) {
Map
<a name="HDz6U"></a>#### 1.3 HashMap的底层源码jdk1.7HashMap map=new HashMap();<br />在实例化以后,底层创建了长度是16的一维数组Entry【】table。<br />.........可能已经执行过多次的put......<br />首先,调用key1所在类型的hashcode()计算key1的哈希值,此哈希值经过某种算法计算过以后,得到entry数组中的存放位置。<br />如果此位置上的数据为空,此时的key1-value1添加成功。-----情况1<br />如果此位置上的数据不为空,(意味着此位置上存在一个或者多个数据(以链表形式存在),比较key1和已经存在的一个或者多个数据的hash值):1. 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况21. 如果key1的哈希值已经存在某个数据(key2-value2)的哈希值相同,继续比较;调用key1所在类的equals(key2)。如果equals()返回false:此时key1-value1添加成功。----情况3<br />如果equals()返回true:使用value1替换value2<br />补充:关于情况2和情况3,此时key1-value1和原来的数据以链表的方式存储。<br />在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容到原来容量的2倍,并将原有的数据复制过来。<br />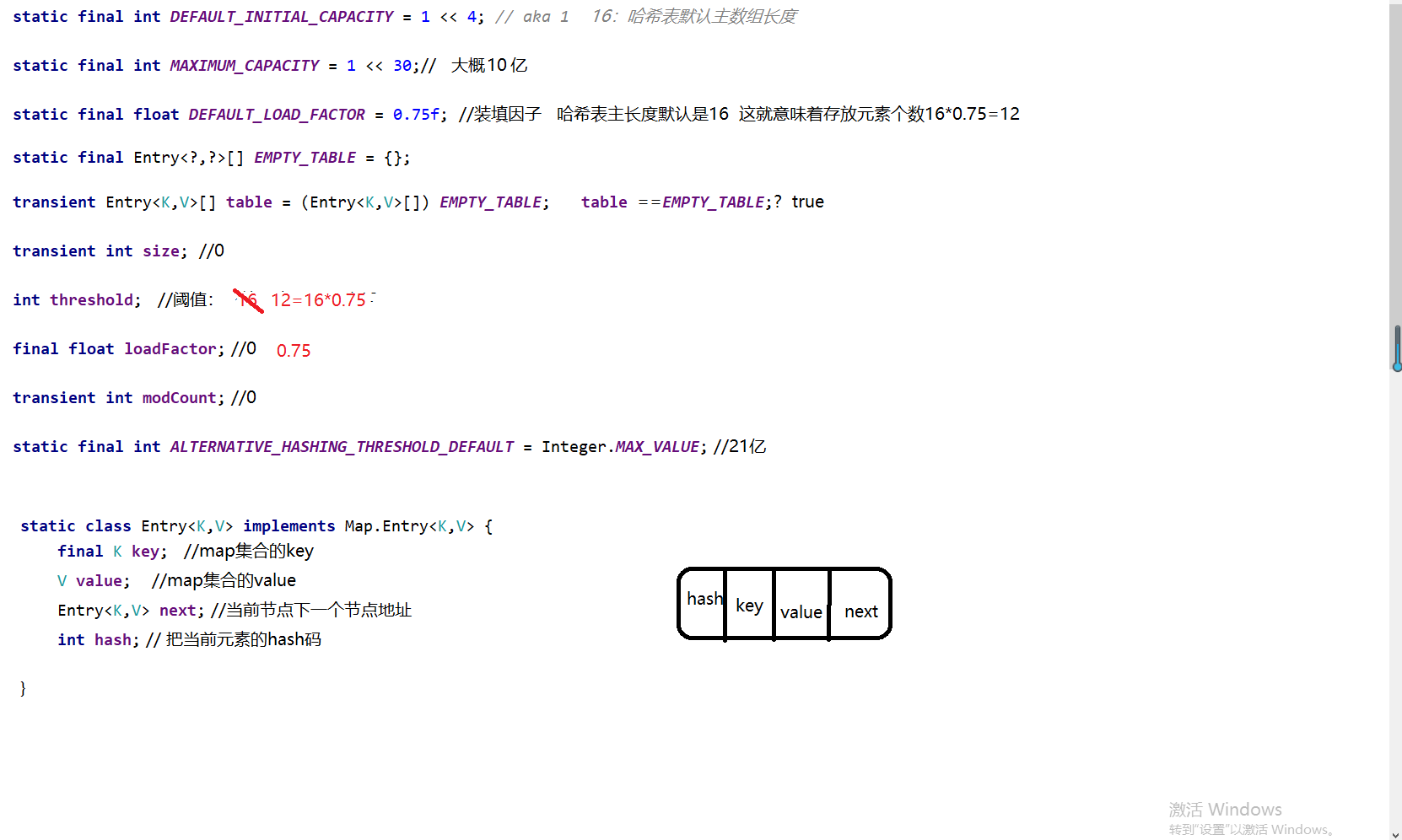<br />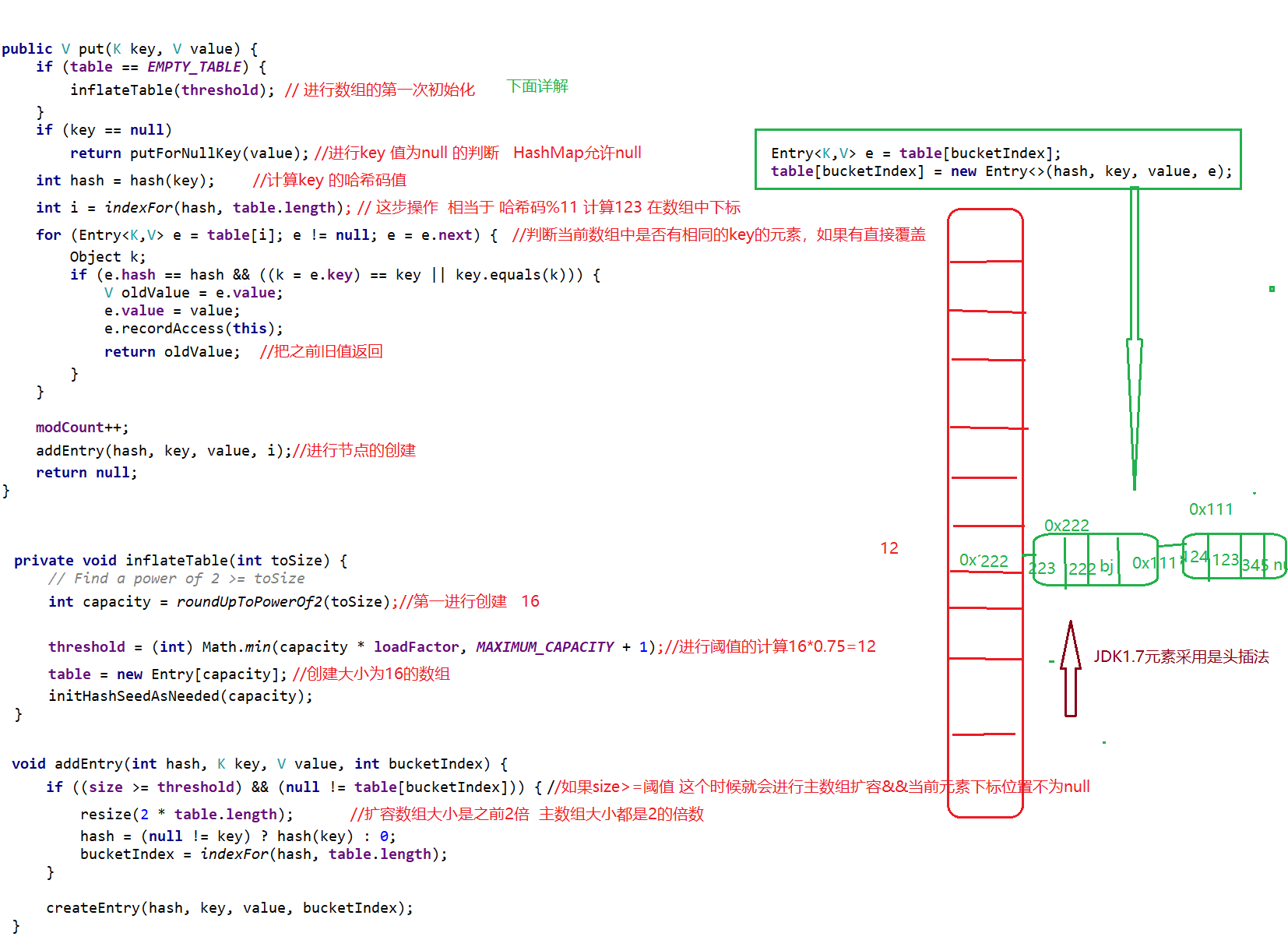<br />面试题A<br /><br />----------------------------------------------------------------------------<a name="l09Qh"></a>#### 1.4 HashMap的底层源码jdk1.8jkd8相较于jdk7在底层实现方面的不同:1. new HashMap();底层没有创建一个长度为16的数组1. jdk8底层的数组是:Node【】,而非Entry【】1. 首次调用put()方法的时候,底层创建长度为16的数组1. jdk7底层结构只有:数组+链表;jdk8中底层结构:数组+链表+红黑树。当数组的某一个索引位置上的元素以链表形式存在的数据个数>8,且当前数组的长度>64时,此时此索引位置上所有数据改为使用红黑树存储。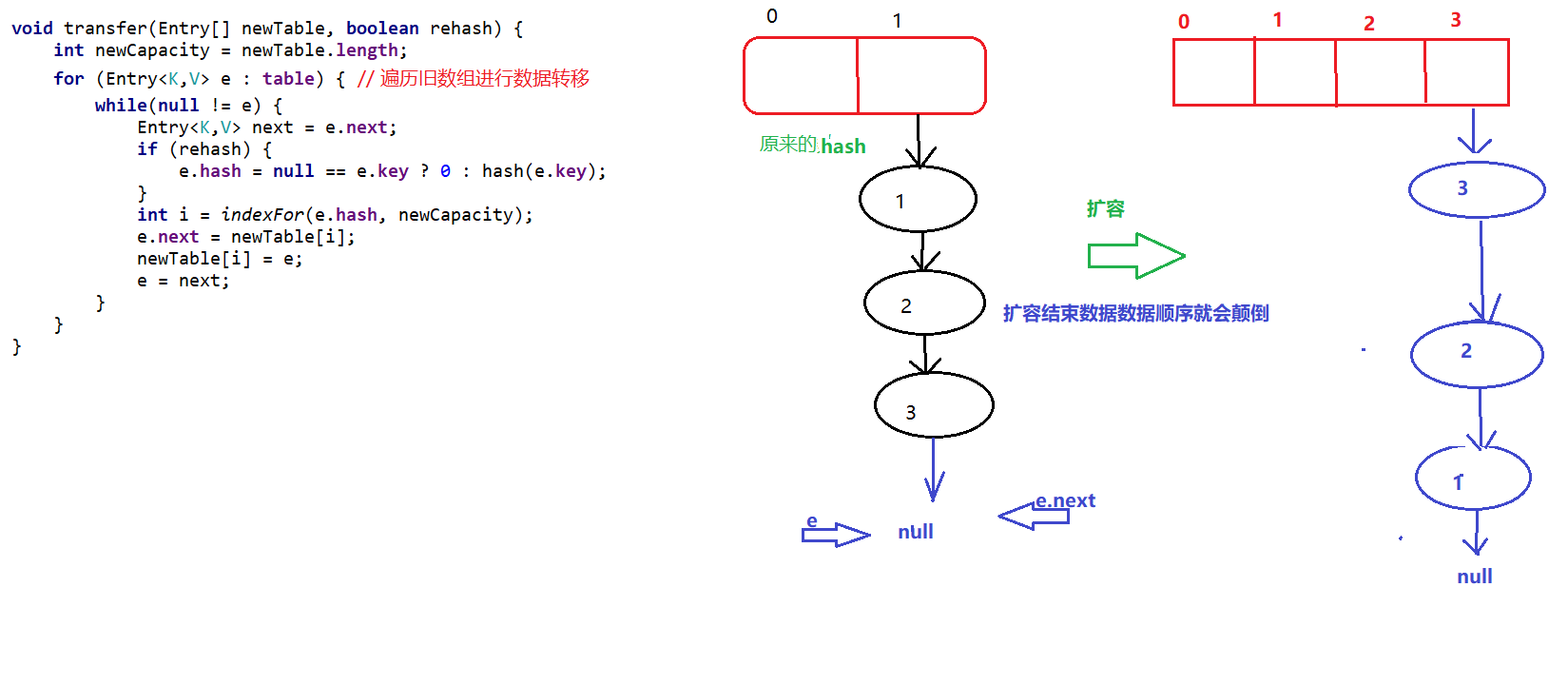<br />-------------------------------------------------------------------------------<br />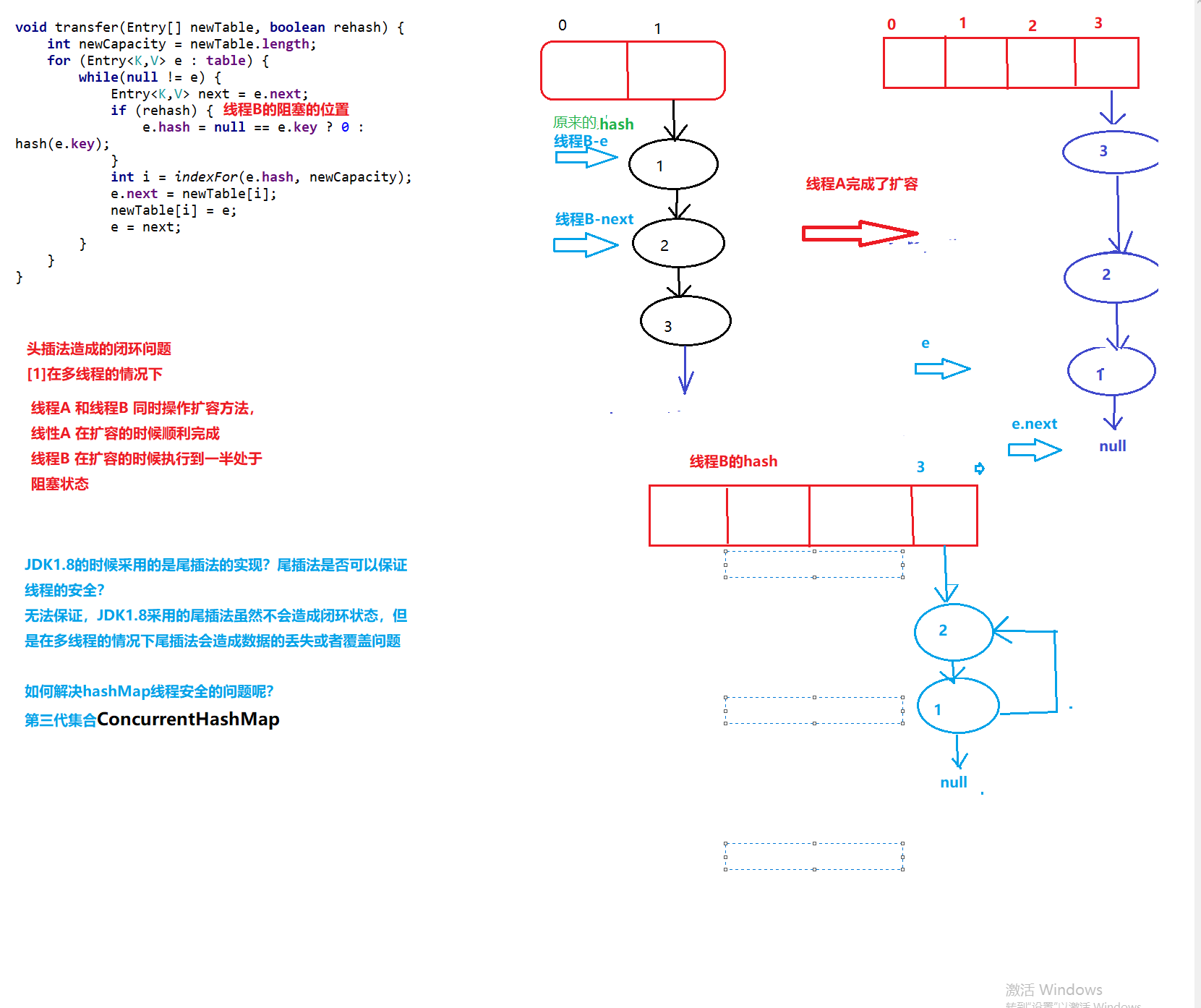<a name="nCxj0"></a>### 2. TreeMap<a name="ouzM1"></a>#### 2.1 基本特征• 基本特征:二叉树、二叉查找树、二叉平衡树、红黑树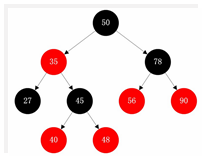 <br />• 每个节点的结构<br />``<br />TreeMap:底层是Tree(红黑树)1. key是唯一的,如果key是重复的,后者就会把前者覆盖1. 不允许key为null红黑树在新增节点过程中比较复杂,复杂归复杂它同样必须要依据上面提到的五点规范<a name="04qMQ"></a>#### 2.2 红黑树的特点[1]每个节点都只能是红色或者黑色。<br />[2]根节点是黑色。<br />[3]每个叶节点(NIL节点,NULL空节点)是黑色的。<br />[4]每个红色节点的两个子节点都是黑色 (****从每个叶子到根的路径上不会有两个连续的红色节点) 。<br />[5]从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。<br /> 由于规则1、2、3基本都会满足,下面我们主要讨论规则4、5。<a name="38euE"></a>#### 2.3 红黑树插入变换假设我们这里有一棵最简单的树,我们规定新增的节点为N、它的父节点为P、P的兄弟节点为U、P的父节点为G。 <br />对于新节点的插入有如下三个关键地方:<br />1、插入新节点总是红色节点。<br />2、如果插入节点的父节点是黑色,能维持性质 。<br />3、如果插入节点的父节点是红色,破坏了性质。<br />故插入算法就是通过重新着色或旋转,来维持性质,可能出现的情况如下:<br /> <br />【情况一】为跟节点<br /> <br />若新插入的节点N没有父节点,则直接当做根据节点插入即可,同时将颜色设置为黑色。<br /> <br />【情况二】父结点为黑色<br /> <br />那么插入的红色节点将不会影响红黑树的平衡,直接插入即可。<br /> <br />【情况三】父节点和叔节点都为红色<br /> <br />当叔父结点为红色时,无需进行旋转操作,只要将父和叔结点变为黑色,将祖父结点变为红色即可。<br /> <br />但是经过上面的处理,可能G节点的父节点也是红色,这个时候我们需要将G节点当做新增节点递归处理。<br />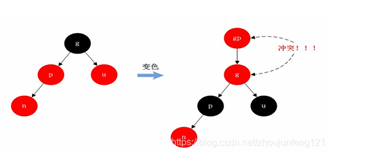<br /> <br />【情况四】父红,叔黑,并且新增节点和父节点都为左子树<br /> <br />对于这种情况先已P节点为中心进行右旋转,在旋转后产生的树中,节点P是节点N、G的父节点。<br />但是这棵树并不规范,所以我们将P、G节点的颜色进行交换,使之其满足规范。<br />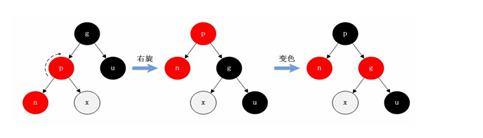<br />【情况五】父红,叔黑,并且新增节点和父节点都为右子树<br /> <br />对于这种情况先已P节点为中心进行左旋转,在旋转后产生的树中,节点P是节点G、N的父节点。但是这棵树并不规范,所以我们将P、G节点的颜色进行交换,使之其满足规范。<br />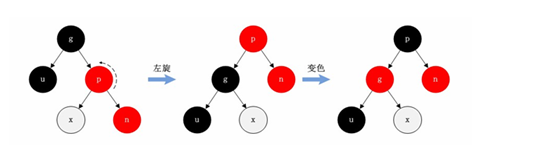<br />【情况六】父红,叔黑,并且新增节点为左子树,父节点为右子树<br /> <br />对于这种情况先以N节点为中心进行右旋转,在旋转后产生的树中,节点N是节点P、X的父节点。然后再以N节点为中心进行左旋转,在旋转后产生的树中,节点N是节点P、G的父节点。但是这棵树并不规范,所以我们将N、G节点的颜色进行交换,使之其满足规范。<br />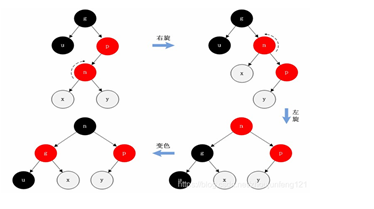<br /> <br />【情况七】父红,叔黑,并且新增节点为右子树,父节点为左子树<br /> <br />对于这种情况先以N节点为中心进行左旋转,在旋转后产生的树中,节点N是节点P、Y的父节点。然后再以N节点为中心进行右旋转,在旋转后产生的树中,节点N是节点P、G的父节点。但是这棵树并不规范,所以我们将N、G节点的颜色进行交换,使之其满足规范。<br />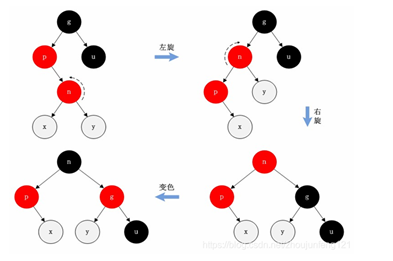<a name="jyJSD"></a>### 3. LinkedHashMap<a name="wq481"></a>## 三、 迭代器iteration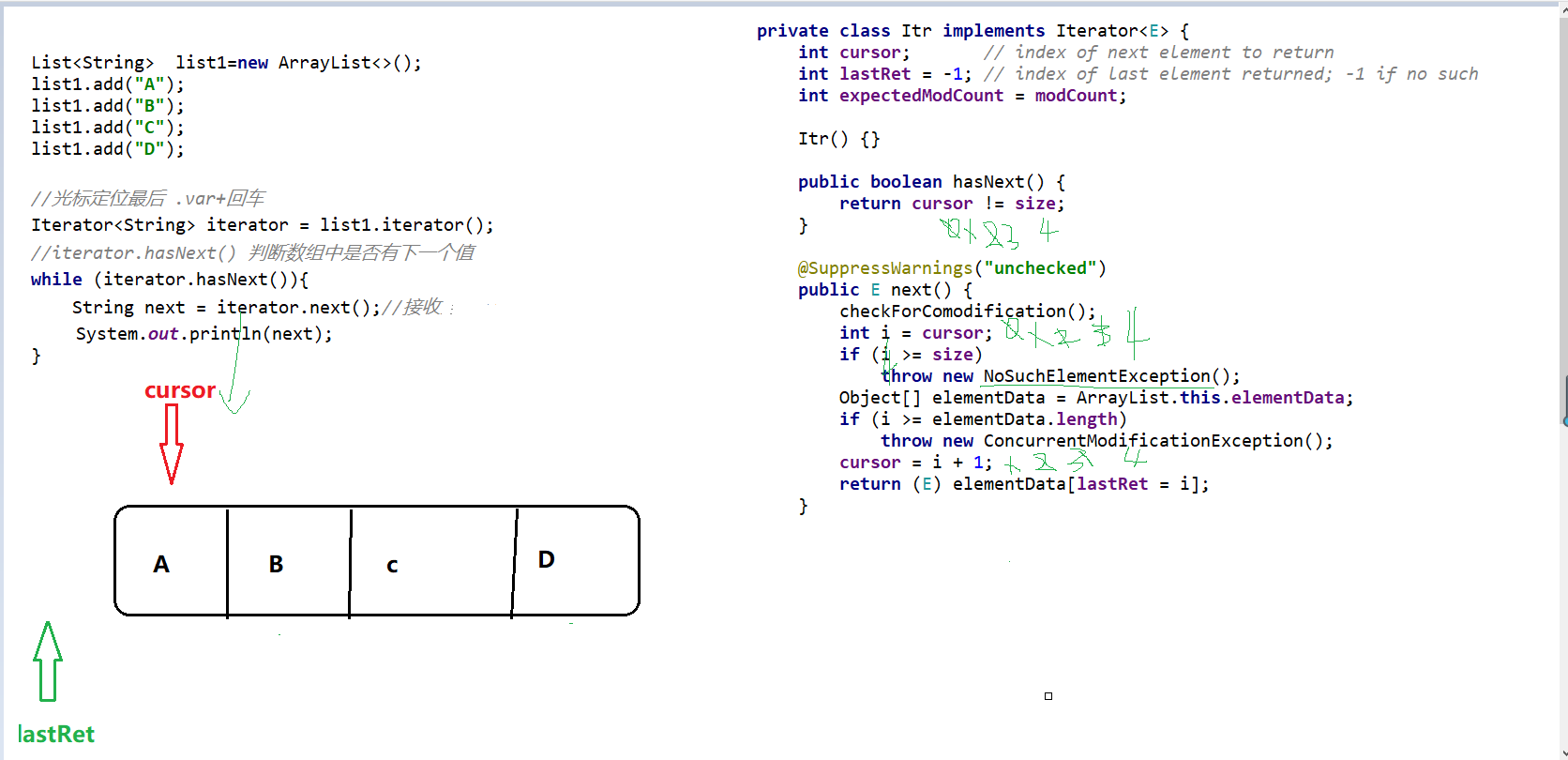<a name="VcupA"></a>### 1. 迭代器在List、Set、Map中的应用```javaimport java.util.*;public class IteratorTestA {public static void main(String[] args) {System.out.println("----------------List Iterator--------------");List<String> list=new ArrayList<>();list.add("A");list.add("B");list.add("C");list.add("D");Iterator<String> iterator = list.iterator();while (iterator.hasNext()){String next = iterator.next();System.out.println(next);}System.out.println("----------------Set Iterator--------------");Set<String> set=new HashSet<>();set.add("A");set.add("B");set.add("C");set.add("D");Iterator<String> iterator1 = set.iterator();while (iterator1.hasNext()){String next1 = iterator1.next();System.out.println(next1);}System.out.println("----------------Map Iterator--------------");Map<String,String> map=new HashMap<>();map.put("A","bj");map.put("B","sxt");map.put("C","bjsxt");Iterator<String> iterator2 = map.keySet().iterator();while (iterator2.hasNext()){String next2 = iterator2.next();System.out.println(map.get(next2));}}
2. 针对List集合的迭代器
import java.util.ArrayList;import java.util.Iterator;import java.util.List;import java.util.ListIterator;public class IteratorTest {public static void main(String[] args) {List<String> list=new ArrayList<>();list.add("A");list.add("B");list.add("C");list.add("D");System.out.println("-----------------iterator遍历----------------------");Iterator<String> iterator = list.iterator();while (iterator.hasNext()){ //判断数组中是否有下一个值String next = iterator.next(); //保存值到next中System.out.println(next);}System.out.println("-----------------只是针对list集合的迭代器----------------------");ListIterator<String> stringListIterator = list.listIterator();//正序遍历while (stringListIterator.hasNext()){String next = stringListIterator.next();System.out.println(next);}System.out.println("-------------------------------------------------------");while (stringListIterator.hasPrevious()){String previous = stringListIterator.previous();//逆序遍历System.out.println(previous);}}}
四、 CollectionS工具类
CollectionS工具类中的常用方法
list集合的线程是不安全的,我们使用sysnchronizedList使集合变得安全
public class CollectionTest {public static void main(String[] args) {List<Integer> list=new ArrayList<>();Collections.addAll(list,20,12,13,14,15,16,17,18,19); //在指定集合中快速的追加元素System.out.println(list);Collections.sort(list); //对集合中的元素进行排序System.out.println(list);int i = Collections.binarySearch(list, 15); //使用二分查找法对查询元素对应的下标,要求必须集合是有序的System.out.println(i);Integer min=Collections.min(list); //最小值Integer max=Collections.max(list);//最大值System.out.println(min+"-----"+max);//Collections.fill(list,null);//快速填充元素List<Integer> list1=new ArrayList<>();Collections.addAll(list1,0,0,0,0,0,0,0,0,0,0,0,0);Collections.copy(list1,list);//集合赋值,保证原集合和目标集合的长度一样System.out.println(list1);//list集合的线程是不安全的,我们使用sysnchronizedList使集合变得安全List<Integer> list2=Collections.synchronizedList(list);//线程安全System.out.println(list2);/* Collections.synchronizedMap();Collections.synchronizedSet();*/}
五、集合分代
1. 第一代
Vector
• 实现原理和ArrayList相同,功能相同,都是长度可变的数组结构,很多情况下可以互用
• 两者的主要区别如下
• Vector是早期JDK接口,ArrayList是替代Vector的新接口
• Vector线程安全,效率低下;ArrayList重速度轻安全,线程非安全
• 长度需增长时,Vector默认增长一倍,ArrayList增长50%
Hashtable类
• 实现原理和HashMap相同,功能相同,底层都是哈希表结构,查询速度快,很多情况下可互用
• 两者的主要区别如下
• Hashtable是早期JDK提供,HashMap是新版JDK提供
• Hashtable继承Dictionary类,HashMap实现Map接口
• Hashtable线程安全,HashMap线程非安全
• Hashtable不允许key的null值,HashMap允许null值
2. 第二代
Lsit Set Map
3. 第三代
ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet:
六、 泛型
没有用泛型之前:
- 不安全:添加元素是无检查,宽进
- 繁琐:获取元素时需要强制类型转换 严出
采用泛型之后:
- 安全 严进
- 简单 宽出
-
1. 泛型类
public class ArrayList<E> {}
2. 泛型接口
public interface List<E> {}
3. 泛型方法
E:element 元素
T:type 类型
K:key 键
V:value:值public <T> void cc(T t){ }public static <T> void dd(T t){ }
4. 上限和下限通配符
```java public class Test02 { public static void sxt(List
list){} //? 传入类型只可以是UU的父类/接口 下限通配符 public static void sxt1(List<? super UU> list){} //? 传入类型只可以使UU的本类/子类 上限通配符 public static void sxt2(List<? extends UU> list){} public static void main(String[] args) {
sxt(new ArrayList<UU>());sxt1(new ArrayList<TT>());sxt2(new ArrayList<RR>());
} } class TT{} class UU extends TT{} class RR extends UU{}
```

若有收获,就点个赞吧
0 人点赞
