- urllib是python的内置的http请求库
- urllib常见函数
- urlopen返回对象提供方法
- urllib.parse.urlencode(dict)
- urllib.reuqest.ProxyHandler(dict)可以将字典里面的ip当做代理去设置。
- urllib.parse.urlparse(urlstring,scheme=’’,allow_fragments=true)
- urllib.request.urlretrieve(url,filename=None,reporthook=None,data=None)
- urllib.request.Request(url,data=none,header=none,origin_host=none,unverifiable=false,method=none)
- urllib.request.HTTPCookieProcessor()
- 异常处理
urllib是python的内置的http请求库
urllib.requests 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
urllib常见函数
urllib.requests.urlopen(url,data,timeout)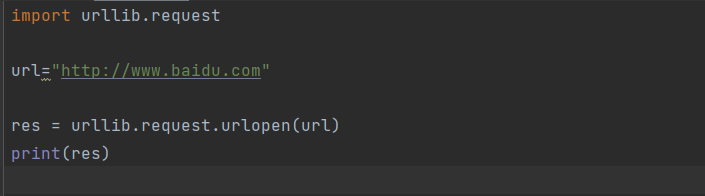

创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
urlopen返回对象提供方法
read()readline(),readlines(),fileneo(),close(),对HTTPResponse类型数据进行操作
把网站html源码进行读取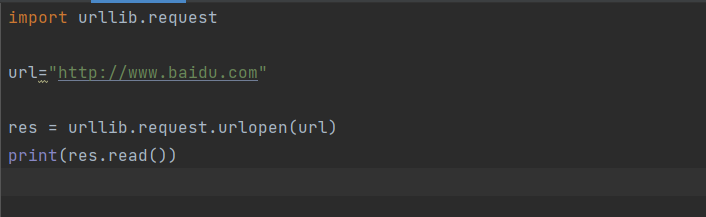
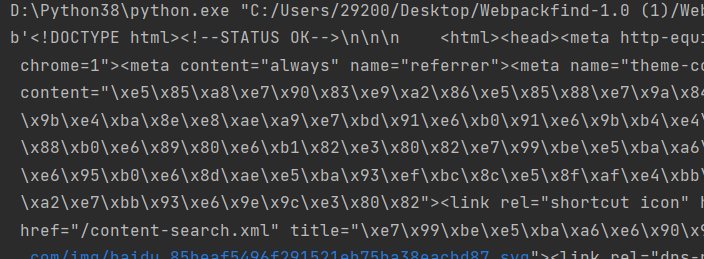
info()返回HTTPMessage对象,表示远程服务器返回的头的信息
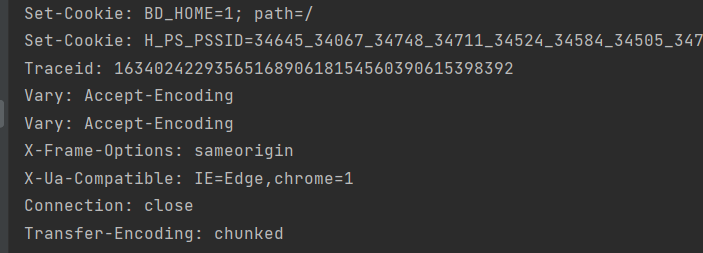
getcode():返回http状态码
geturl():返回请求的url。
urllib.parse.urlencode(dict)
将dict或包含两字元素的元组列表装换成url参数。
例如{“name”=’’qingmo’’,”age”=’’22’’}转换成”name=qingmo||age=22”
https://baijiahao.baidu.com/s?id=1622594556284170797&wfr=spider%26for%3Dpc
将urlid=1622594556284170797&wfr=spider%26for%3Dpc拼接成dict = {‘id’:’1622594556284170797’,’wfr’:’spider&for=pc’}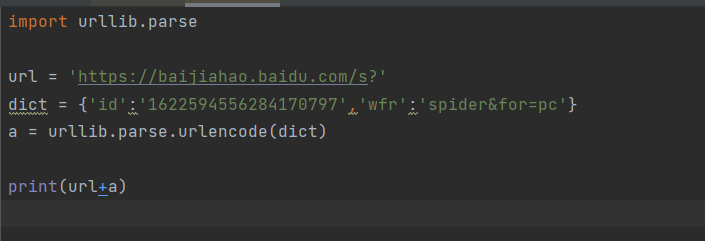

urllib.reuqest.ProxyHandler(dict)可以将字典里面的ip当做代理去设置。
urllib.parse.urlparse(urlstring,scheme=’’,allow_fragments=true)
url解析函数的重点是将url字符串拆分为其组件,或者将url组件组合为一个url字符串。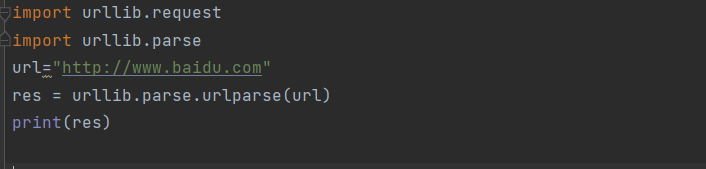

urllib.request.urlretrieve(url,filename=None,reporthook=None,data=None)
urlretrieve()方法直接将远程数据下载到本地。
参数url为请求地址
参数filename指定保存本地路径,(如果参数未指定,urllib会生成一个临时文件保存数据)
参数reporthook是一个回调函数,当连接上服务器,以及相应的数据块传输完毕是会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data是指post到服务器的数据,该方法返回一个包含两个元素(filename,headers)的元组,filename表示保存的本地路径,header表示服务器的响应头。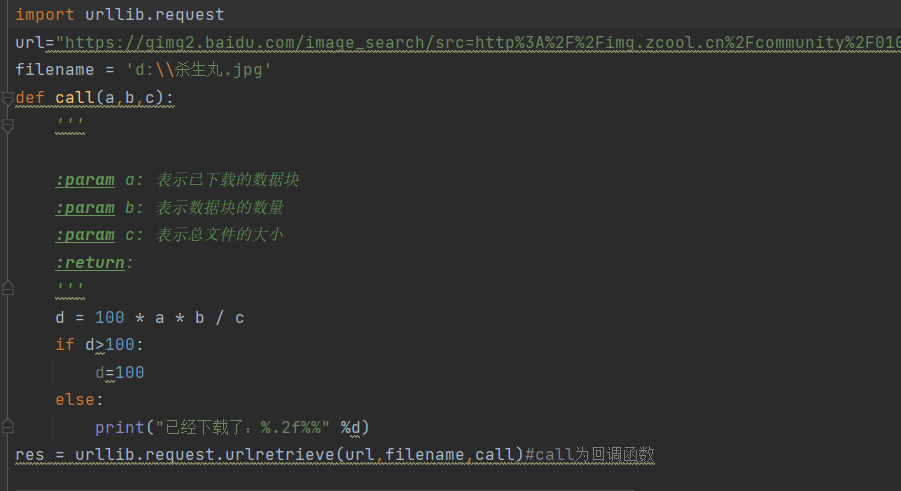
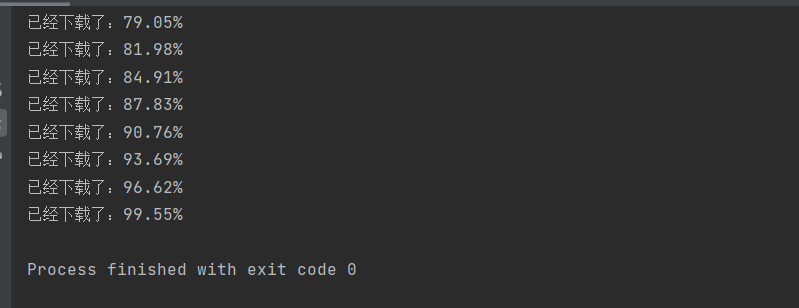
import urllib.requesturl="https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.zcool.cn%2Fcommunity%2F010d325b40df23a80121b9943080ad.jpg%401280w_1l_2o_100sh.jpg&refer=http%3A%2F%2Fimg.zcool.cn&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1636620879&t=de74f3e0c1926698163b036a30bfc07b"filename = 'd:\\杀生丸.jpg'def call(a,b,c):''':param a: 表示已下载的数据块:param b: 表示数据块的数量:param c: 表示总文件的大小:return:'''d = 100 * a * b / cif d>100:d=100else:print("已经下载了:%.2f%%" %d)res = urllib.request.urlretrieve(url,filename,call)#call为回调函数
urllib.request.Request(url,data=none,header=none,origin_host=none,unverifiable=false,method=none)
url :为访问地址
data:此参数为可选字段,其中传递的参数需要转为bytes,如果是字典我们需要通过urllib.parse.urlencode转换即可
headers:http相应的传递的信息,构造方法,headers参数传递,通过调用request对象的add_header()方法来添加请求头。
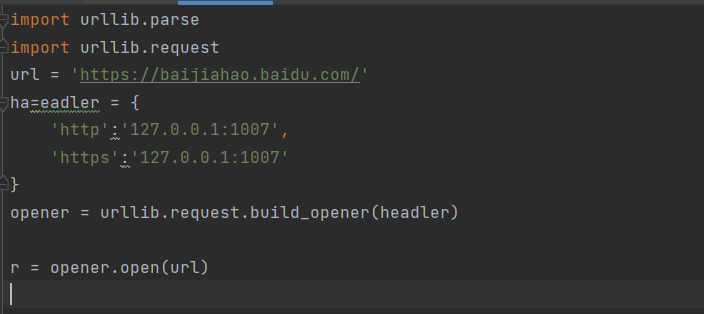
import urllib.requesturl = 'https://www.baidu.com/'headers= {'http':'127.0.0.1:1007','https':'127.0.0.1:1007'}data = {'name':'qingmo','age':'18'}res=urllib.request.Request(url,data=data,headers=headers)
urllib.request.HTTPCookieProcessor()
网站中通过cookie进行判断权限是很常见的。那么我们可以通过urllib.request.HTTPCookieProcessor(cookie)来操作cookie。使用cookie和使用代理ip一样也需要自己创建一个自己的opener。在http包中,提供了cookiejar模块,用于提供对cookie的支持。http。cookiejar功能强大,我们可以利用本模块的cookiejar类的对象来捕捉cookie并在后续链接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有cookiejar,Filecookiejar,Mozillacookiejar,LWPCcookiefar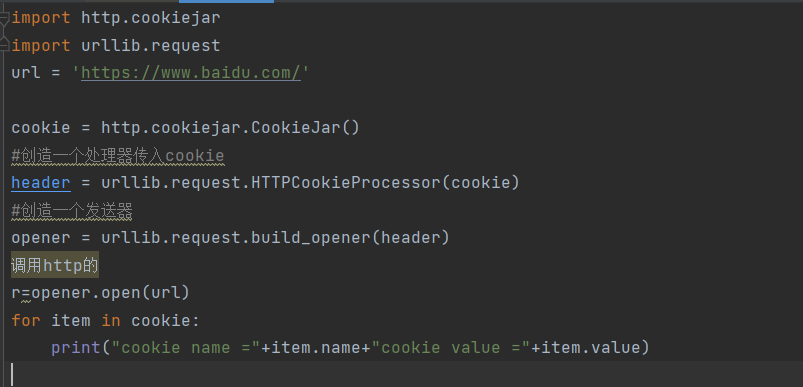
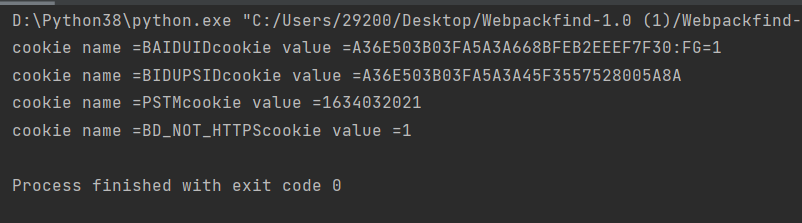
import http.cookiejarimport urllib.requesturl = 'https://www.baidu.com/'cookie = http.cookiejar.CookieJar()#创造一个处理器传入cookieheader = urllib.request.HTTPCookieProcessor(cookie)#创造一个发送器opener = urllib.request.build_opener(header)调用http的r=opener.open(url)for item in cookie:print("cookie name ="+item.name+"cookie value ="+item.value)
异常处理
如果访问时间没有在这个时间范围内就会报错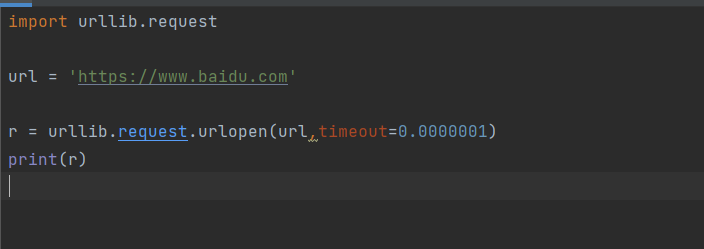
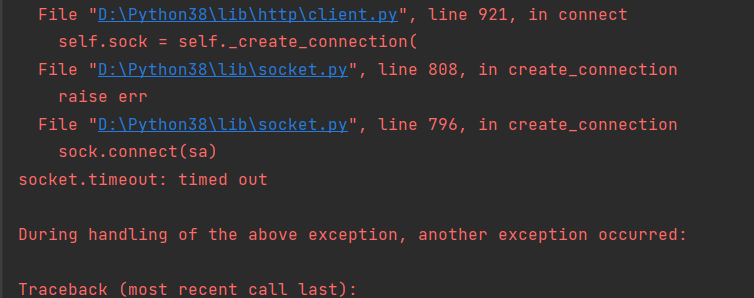
报错的位置,报了一个通信异常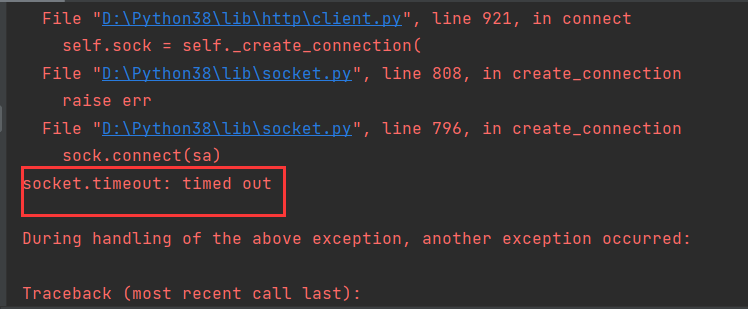
处理这个异常,导入通信的包
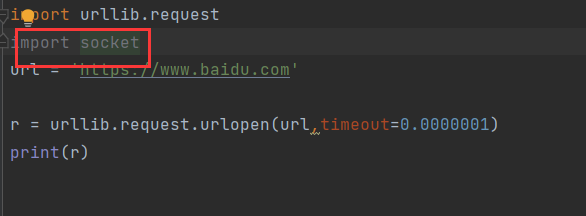
然后找到异常的包进行处理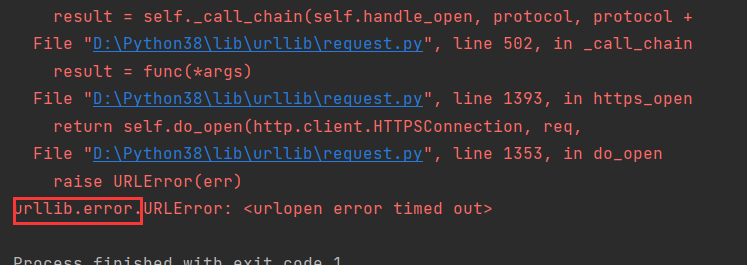
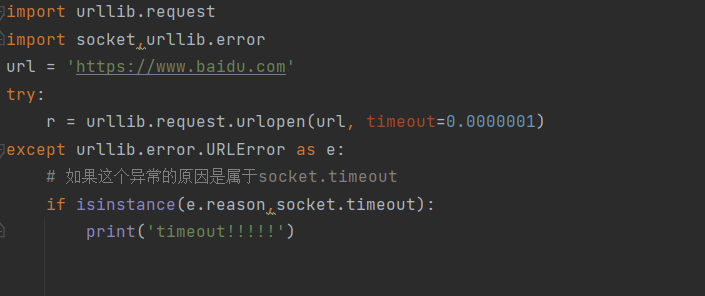
import urllib.requestimport socket,urllib.errorurl = 'https://www.baidu.com'try:r = urllib.request.urlopen(url, timeout=0.0000001)except urllib.error.URLError as e:# 如果这个异常的原因是属于socket.timeoutif isinstance(e.reason,socket.timeout):print('timeout!!!!!')

若有收获,就点个赞吧
0 人点赞
