8.2.1 接口获取子域名工具开发
Ip查询功能
Import socket
IP= socket.gethostbyname(‘www.baidu.com’)
Print(ip)
8.2.2 使用bing接口获取子域名:
1 使用bing接口搜索site:qq.com 获取url地址从参数构造
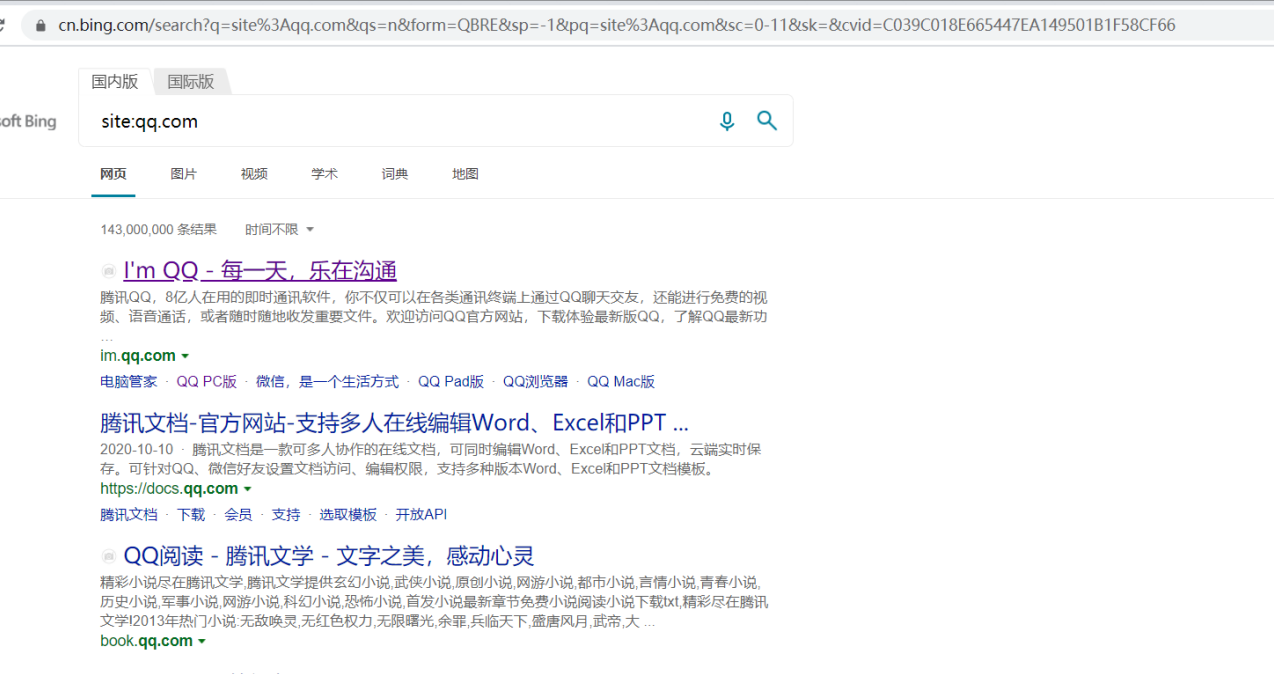
导入所需的库
Import request
From bs4 import beautifulsoup编写获取函数
import requests
from bs4 import BeautifulSoup
import re
def subdomain(url,page):
suburls=[]
headers = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Encoding’: ‘gzip, deflate, compress’,
‘Accept-Language’: ‘en-us;q=0.5,en;q=0.3’,
‘Cache-Control’: ‘max-age=0’,
‘Connection’: ‘keep-alive’,
‘User-Agent’: ‘Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0’
}
for p in range(1,int(page)+1):
domain=”https://cn.bing.com/search?q=site%3A"+url+"&qs=n&form=QBRE&sp=-1&pq=site%3A"+url+"&first="+str((int(p)-1)*10)+"&FROM=PERE“
rre=requests.Session()
rre.get(‘https://cn.bing.com',headers=headers)
res=rre.get(domain,headers=headers,timeout=3)
soup=BeautifulSoup(res.text,’lxml’)
con=soup.find_all(‘h2’)
for u in con:
ur=u.a.get(‘href’)
ur=re.search(‘://(.*com)\/‘,ur)
uu=ur.group(1)
if uu in suburls:
pass
else:
suburls.append(uu)
return suburls
subdomains=subdomain(‘qq.com’,8)
print(‘发现子域名个数: ‘,len(subdomains))
for i in subdomains:
print(i)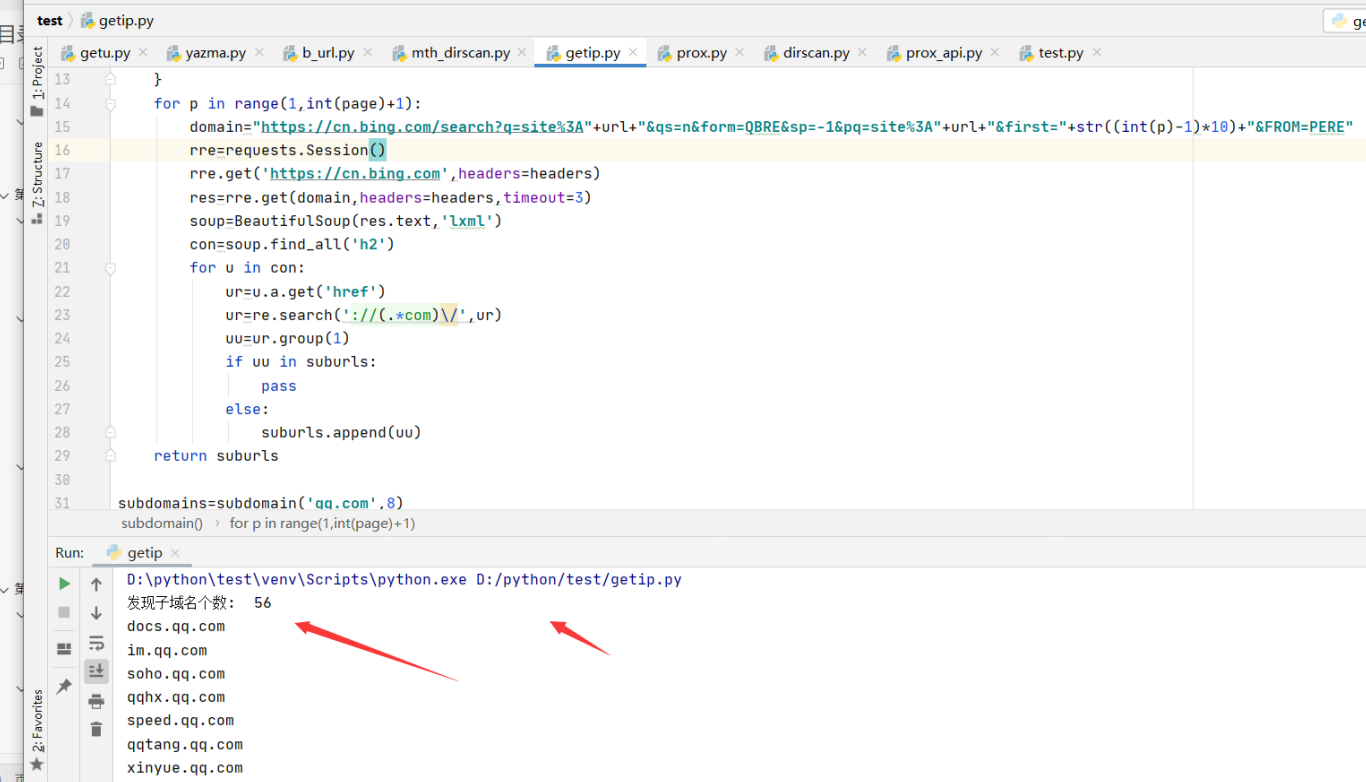
打印 子域名IP和容器信息
Import socket #导入socket库
加入以后代码 打印子域名的server信息和ip信息
try:
ures = rre.get(uurl, headers=headers, timeout=3)
print(uu,’ ‘,socket.gethostbyname(uu),’ ‘,ures.headers[‘Server’])
except:
Pass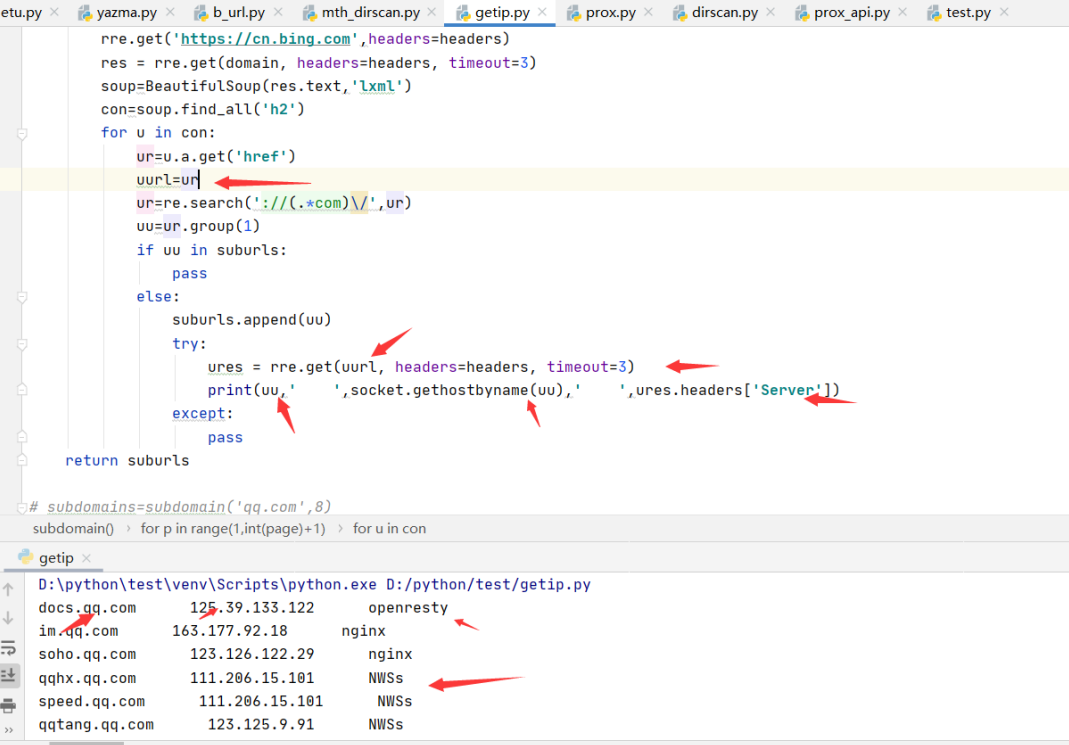
多线程爆破子域名
1.导入所需的库
Import requests
Import socket
- 加载子域名字典dic.txt,创建加载字典函数
import requests
import socket
import threadpool
dirs=[]
subdomains=[]
def loaddir():
global dirs
f=open(‘dic.txt’,’r’)
x=f.readlines()
dirs=[i.strip() for i in x]
loaddir()
print(dirs)
3,创建单线程爆破子域名函数
def brusubdoamin():
headers = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Encoding’: ‘gzip, deflate, compress’,
‘Accept-Language’: ‘en-us;q=0.5,en;q=0.3’,
‘Cache-Control’: ‘max-age=0’,
‘Connection’: ‘keep-alive’,
‘User-Agent’: ‘Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0’
}
domain=’baidu.com’
global subdomains
global dirs
cod=[200,403,301,302,500]
loaddir()
for dir in dirs:
url=’http://'+dir+'.'+domain
try:
re=requests.get(url,headers=headers,timeout=3)
if re.status_code in cod:
print(dir+’.’+domain,socket.gethostbyname(dir+’.’+domain),re.headers[‘Server’])
except:
pass
brusubdoamin()
4,创建多线程子域名爆破函数
def brusubdoamin(dir):
headers = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Encoding’: ‘gzip, deflate, compress’,
‘Accept-Language’: ‘en-us;q=0.5,en;q=0.3’,
‘Cache-Control’: ‘max-age=0’,
‘Connection’: ‘keep-alive’,
‘User-Agent’: ‘Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0’
}
domain=’baidu.com’
global subdomains
cod=[200,403,301,302,500]
url=’http://'+dir+'.'+domain
try:
re=requests.get(url,headers=headers,timeout=3)
if re.status_code in cod:
print(dir+’.’+domain,socket.gethostbyname(dir+’.’+domain),re.headers[‘Server’])
except:
pass
loaddir()
print(dirs)
print(‘使用字典数为: ‘,len(dirs))
pool=threadpool.ThreadPool(50) #定义线程池数
reqs=threadpool.makeRequests(brusubdoamin,dirs) #定义函数和字典
[pool.putRequest(req) for req in reqs] #遍历执行线程池
pool.wait()

若有收获,就点个赞吧
0 人点赞
