beautiful soup
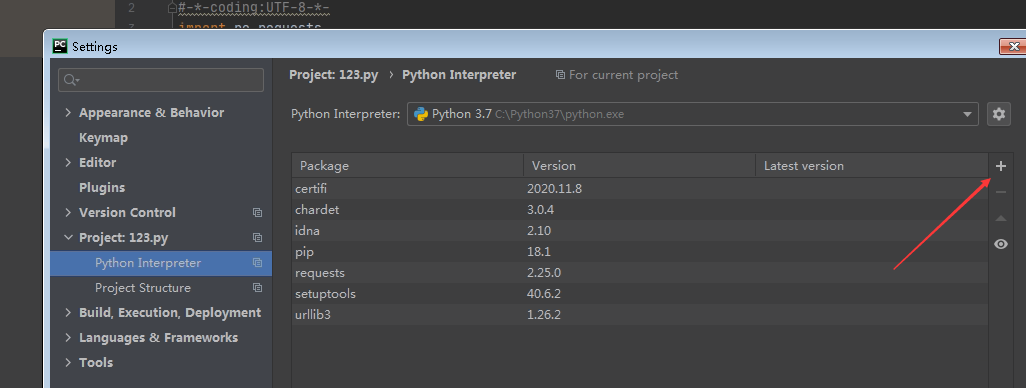
安装一个bs4和lxml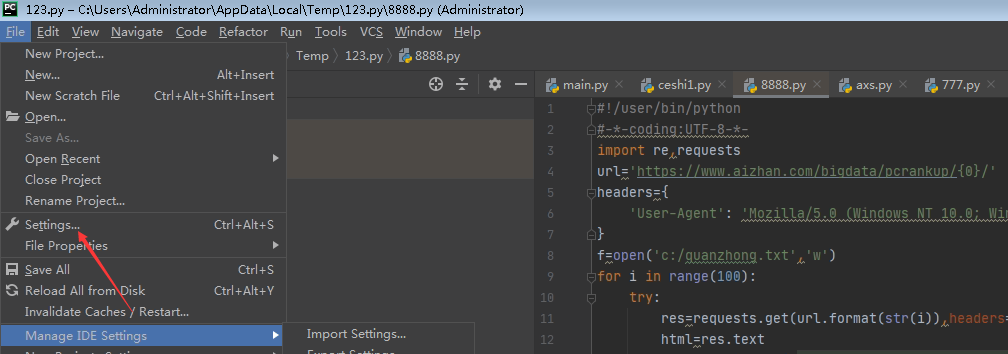





lxml的用法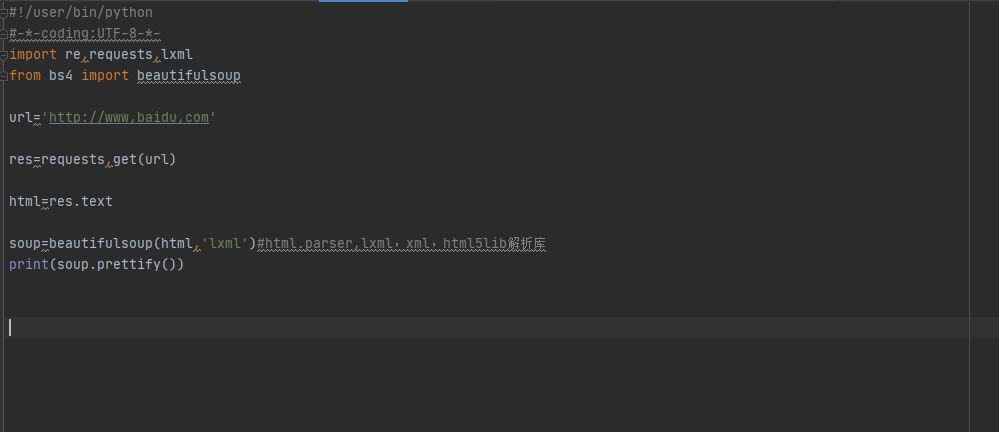
代码
#!/user/bin/python#-*-coding:UTF-8-*-import requestsimport lxmlfrom bs4 import BeautifulSoupurl='http://www.baidu.com'res=requests.get(url)html=res.textsoup=BeautifulSoup(html,'lxml')#html.parser,lxml,xml,html5lib解析库print(soup.prettify())
打印title标签里面的字符串
#!/user/bin/python#-*-coding:UTF-8-*-import re,requests,lxmlfrom bs4 import BeautifulSoupurl='http://www,baidu,com'res=requests,get(url)html=res.textsoup=beautifulsoup(html,'lxml')#html.parser,lxml,xml,html5lib解析库print(soup.title.string)#打印title头
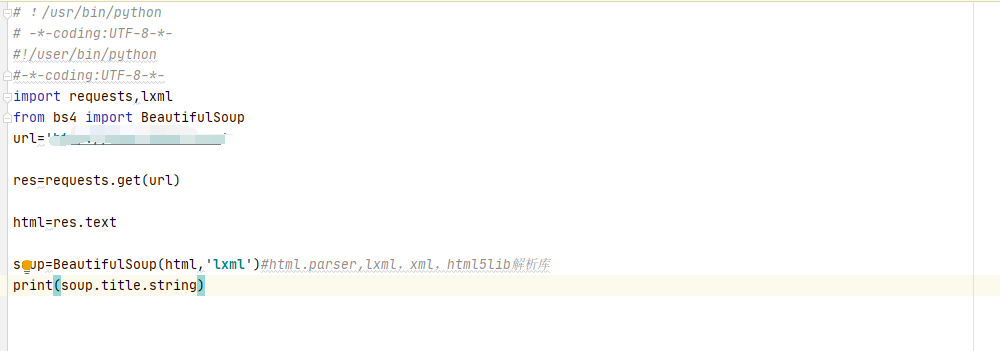

标签节点选择嵌套
#!/user/bin/python#-*-coding:UTF-8-*-import re,requests,lxmlfrom bs4 import BeautifulSoupurl='http://www,baidu,com'res=requests.get(url)html=res.textsoup=beautifulsoup(html,'lxml')#html.parser,lxml,xml,html5lib解析库print(soup.head.title.string)#打印title#标签节点选择嵌套
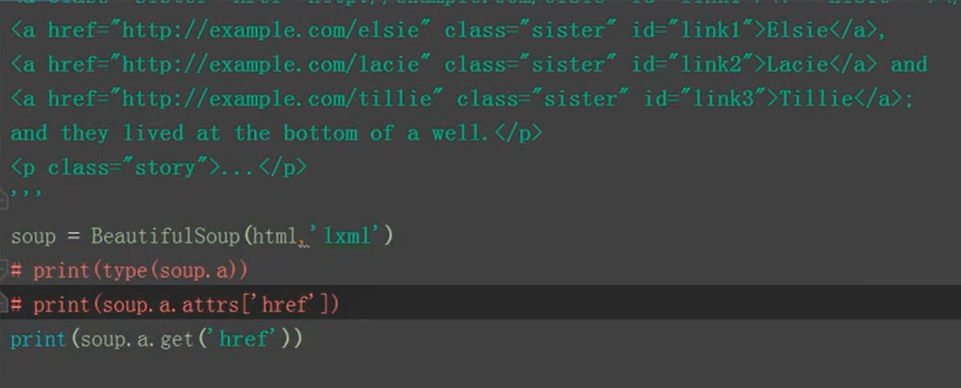
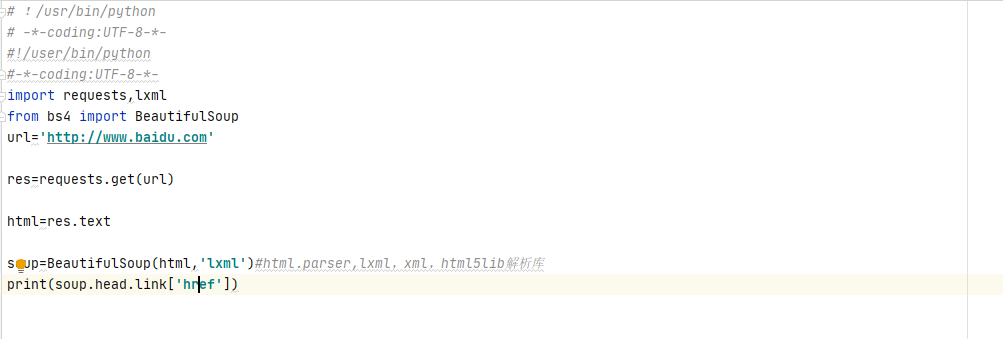
标签的属性选择
#!/user/bin/python#-*-coding:UTF-8-*-import re,requests,lxmlfrom bs4 import BeautifulSoupurl='http://www,baidu,com'res=requests.get(url)html=res.textsoup=beautifulsoup(html,'lxml')#html.parser,lxml,xml,html5lib解析库print(soup.link.['href'])#打印a标签属性的名称为href的值

生成器用法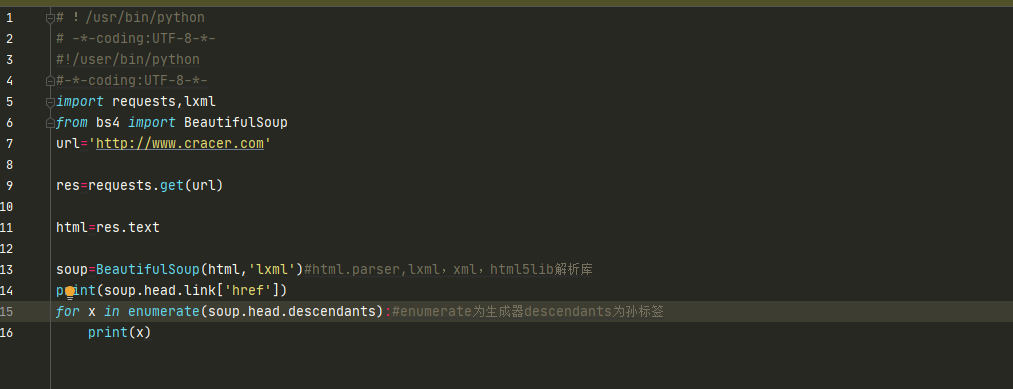
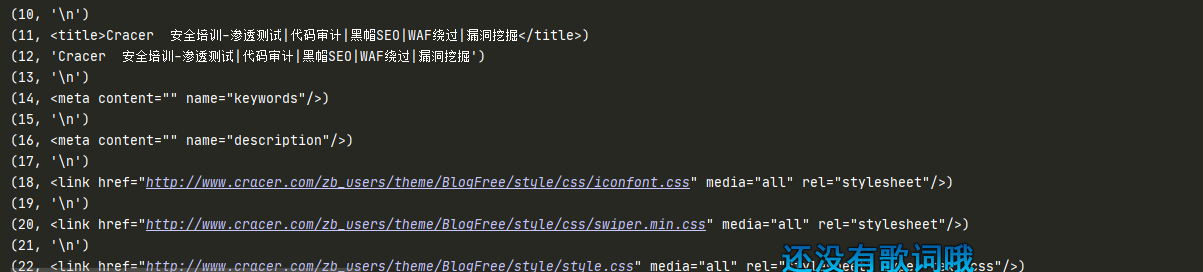
兄弟节点
上一个兄弟节点用next_sibling
下一个兄弟节点则用previous_sibling
方法选择器
find()匹配第一个满足条件的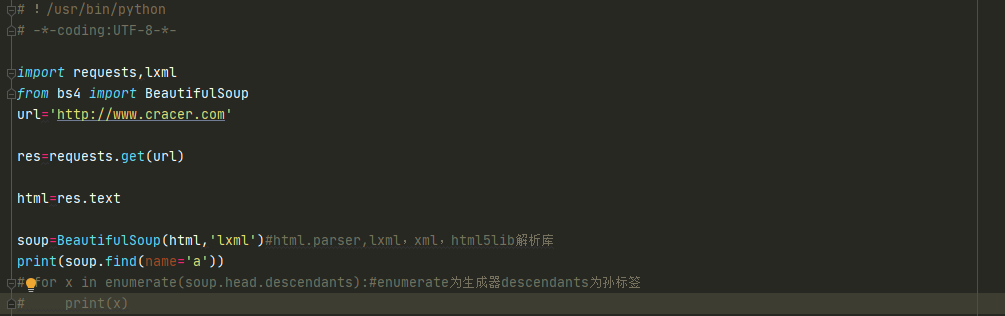

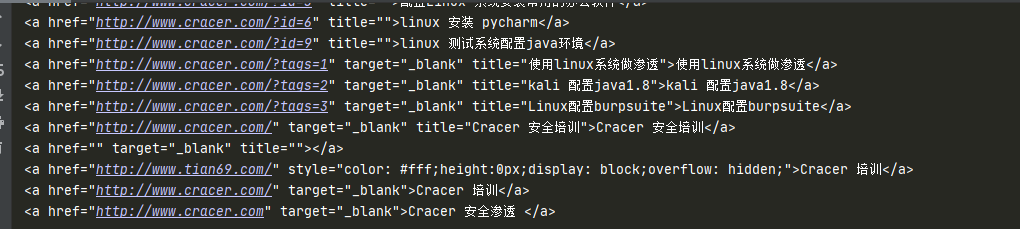
find_all()查找复合所有条件的元素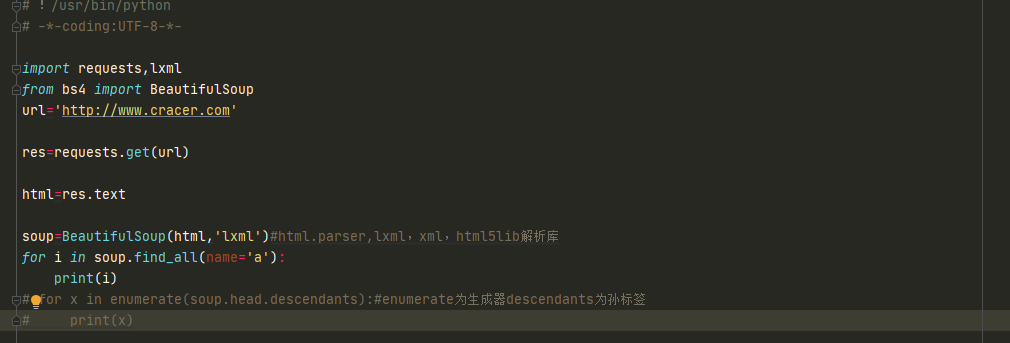
写入文件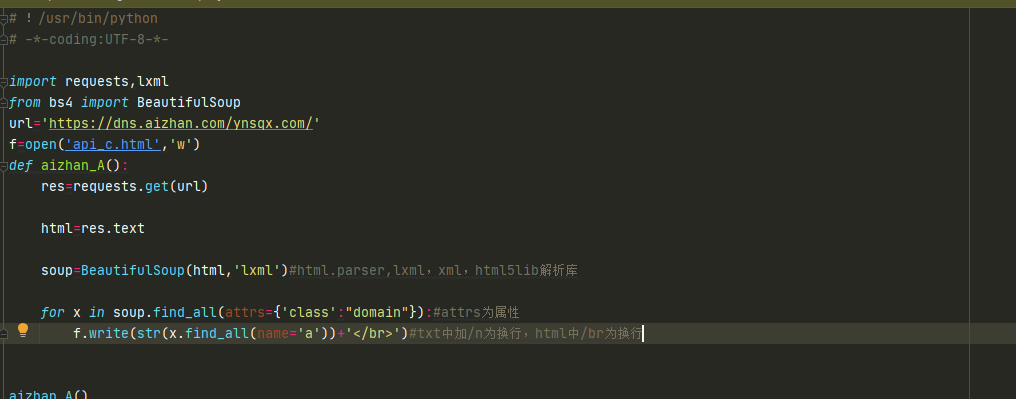
代码
# !/usr/bin/python# -*-coding:UTF-8-*-import requests,lxmlfrom bs4 import BeautifulSoupurl='https://dns.aizhan.com/ynsqx.com/'f=open('api_c.html','w')def aizhan_A():res=requests.get(url)html=res.textsoup=BeautifulSoup(html,'lxml')#html.parser,lxml,xml,html5lib解析库for x in soup.find_all(attrs={'class':"domain"}):#attrs为属性f.write(str(x.find_all(name='a'))+'</br>')#txt中加/n为换行,html中/br为换行aizhan_A()
css选择器
可以直接使用select这个函数进行选择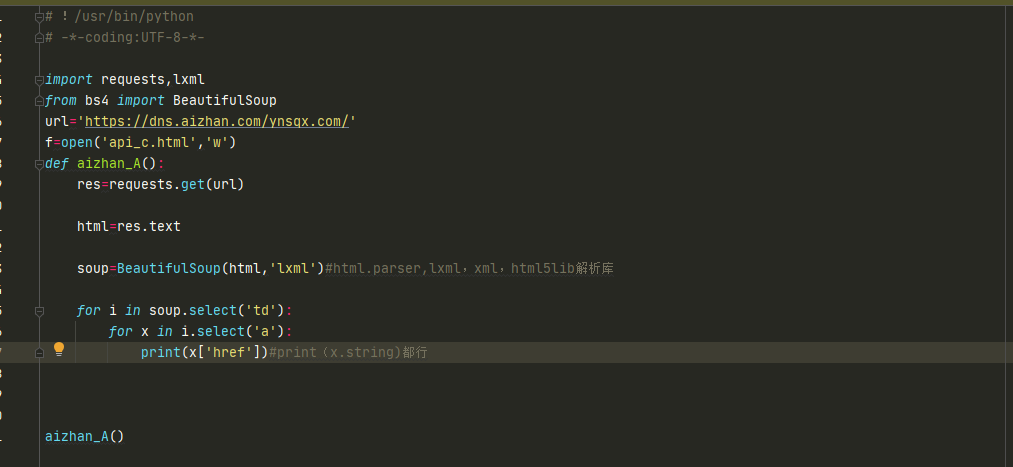


若有收获,就点个赞吧
0 人点赞
