首先打开搜索界面,然后打开检查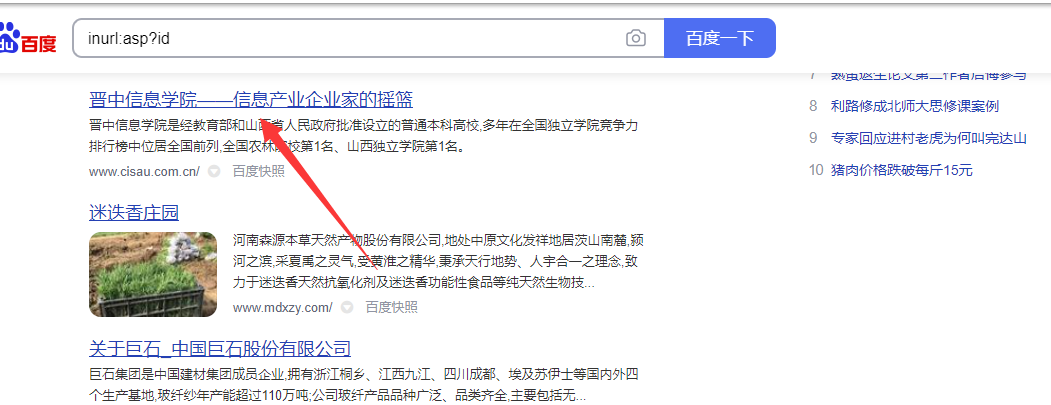
res=browser.find_elements_by_class_name(‘result’)抓取页面的内容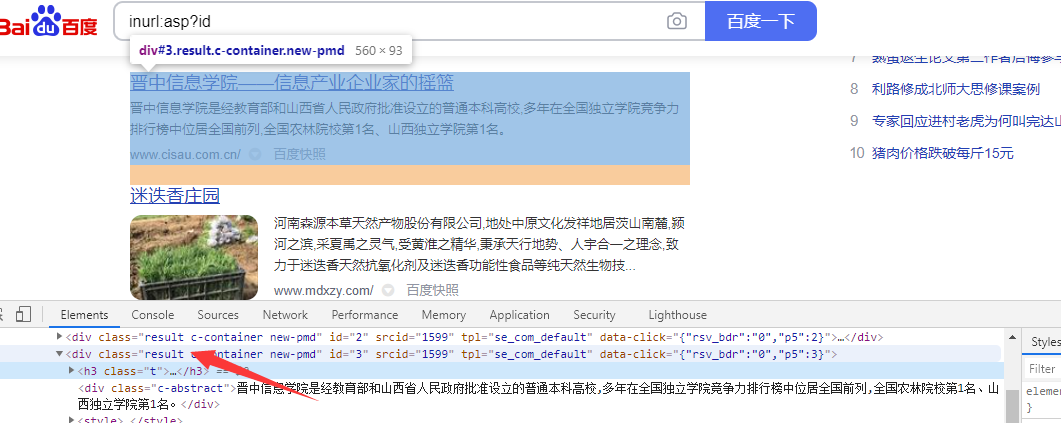
x=browser.find_element_by_id(‘page’)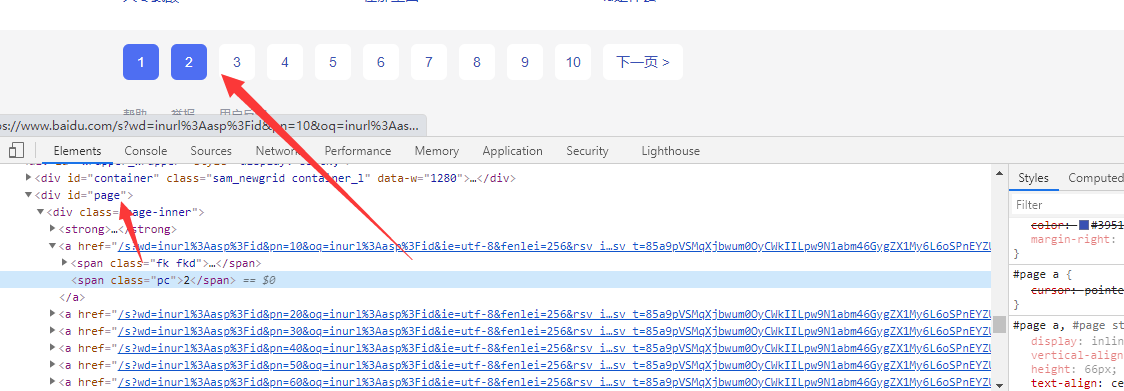
然后抓取page里面的a标签,links=x.find_elements_by_tag_name(‘a’)
然后for循环,赋值给a for a in links:
if page_num in a.get_attribute(‘href’):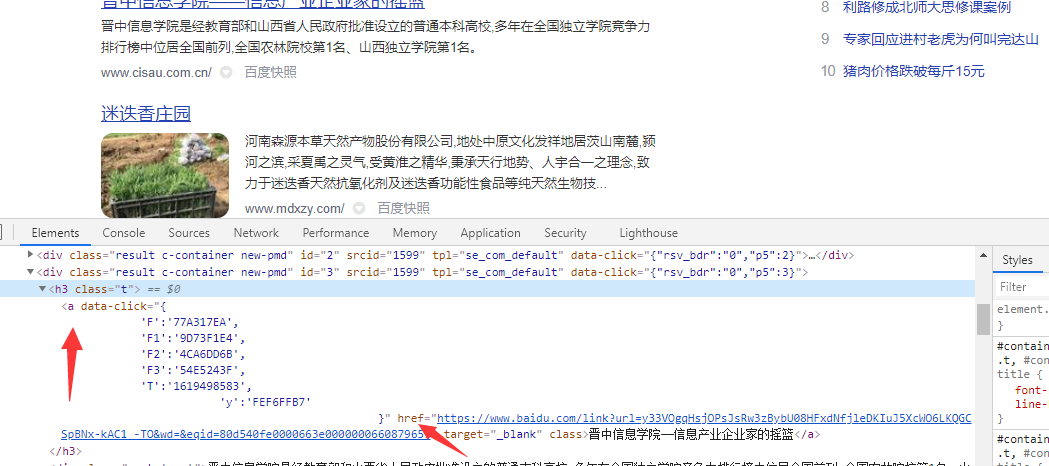
百度采集
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom time import sleepimport requestsheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, compress','Accept-Language': 'en-us;q=0.5,en;q=0.3','Cache-Control': 'max-age=0','Connection': 'keep-alive','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'}def baidu_url():browser=webdriver.Chrome()browser.get('https://www.baidu.com')browser.find_element_by_id('kw').send_keys('inurl:asp?id=')browser.find_element_by_id('kw').send_keys(Keys.ENTER)pn=0for p in range(10,1000,10):page_num='&pn='+str(p)sleep(5)res=browser.find_elements_by_class_name('result')zhuqu(res)x=browser.find_element_by_id('page')links=x.find_elements_by_tag_name('a')for a in links:if page_num in a.get_attribute('href'):a.click()breakprint('当前抓取第%s 页内容' % int(p / 10+1))def zhuqu(res):for re in res:f=open('d:/baidu_url.txt','a')t=re.find_element_by_tag_name('a').textzu=re.find_element_by_tag_name('a').get_attribute('href')baiurl=requests.get(zu,headers=headers,allow_redirects=False)true_url=baiurl.headers['Location']print(t)print(true_url)f.write(true_url+'\n')baidu_url()
模拟登录
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom time import sleepbr=webdriver.Chrome()br.get('https://localhost:3443/#/login')input=br.find_element_by_id('txtEmailAddress').send_keys('2920015236@qq.com')input=br.find_element_by_id('txtPassword').send_keys('x5201314..')dj=br.find_element_by_id('btnLogin').click()

若有收获,就点个赞吧
0 人点赞
