Ajax技术
什么是ajax
Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。 它不是一门编程 语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新 部分网页的技术。 对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax,便可以在页面不 被全部刷新的情况下更新其内容。 在这个过程中,页面实际上是在后台与服务器进行了数据交互,获 取到数据之后,再利用 JavaScript 改变网页,这样网页内容就会更新了。
Ajax 分析方法
Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。 它不是一门编程 语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新 部分网页的技术。 对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax,便可以在页面不 被全部刷新的情况下更新其内容。 在这个过程中,页面实际上是在后台与服务器进行了数据交互,获 取到数据之后,再利用 JavaScript 改变网页,这样网页内容就会更新了。
. 基本原理
初步了解了 Ajax 之后,我们再来详细了解它的基本原理。 发送 Ajax 请求到网页更新的这个过程 吁以简单分为以下 3 步:
(I)发送请求;
(2)解析内容;
(3)渲染网页。
抓取今日头天美图案例
1.先打开今日头条网站进行分析,是否ajax加载页面
https://www.toutiao.com/
搜索图片,打开网络监听,然后选择xhr模式,下来滚动条,里面自动加载,有发送请求到服务器,而页面没有发生跳转,判断是ajax加载。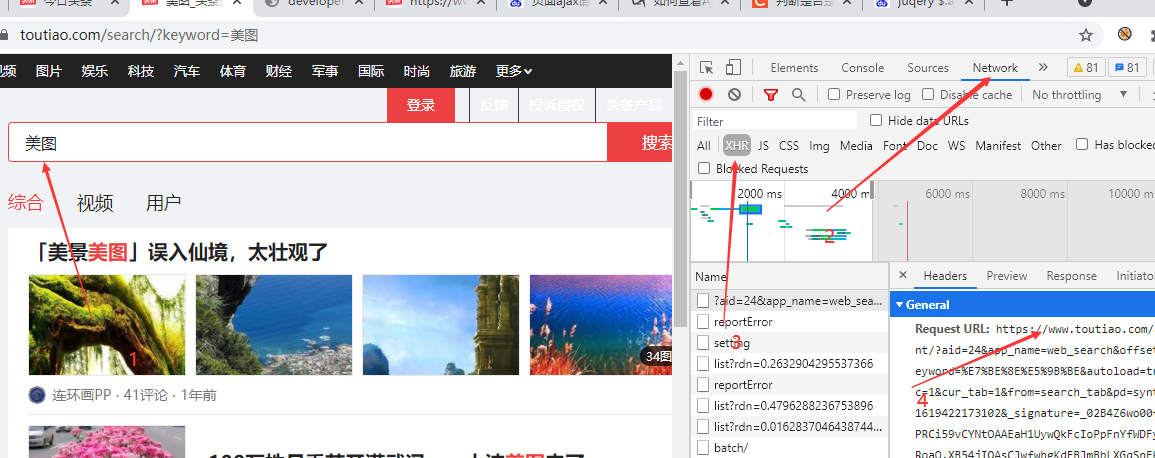
我们随机抽取一条Ajax发送给服务器的请求来抓取图片内容。
import requests,reheaders={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}url='https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=60&format=json&keyword=%E7%BE%8E%E5%9B%BE&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1602406043867&_signature=BJhvvAAgEBAqqfArgsHgvgSZLqAAFsg7GpQM7xzfxXDF89jrMfSQ5bp9m1SlGKt9pFE40rkMza1dMtGNThG-K5SrKw65eMYulOSqi0ITBuzsqZwFSF1l0OwH0E1PAVepcFW'r=requests.get(url)json=r.json()a=[]if json.get('data'):for item in json.get('data'):title=item.get('title')images=item.get('image_list')try:for x in images:print(title)print(x['url'])except:Pass
Selenium使用
浏览器版本
Chrome驱动下载http://npm.taobao.org/mirrors/ChromeDriver/
解压到Python的环境变量里面
selenium是一个自动化测试工具,利用他可以驱动浏览器执行特定的动作。
selenium支持很多浏览器,如Chrome,Firefox,还支持手机端的浏览器。
import requests
from selenium import webdriver
browser=webbdriver.Chrome()
from selenium.webdriver.common.keys import Keys的作用
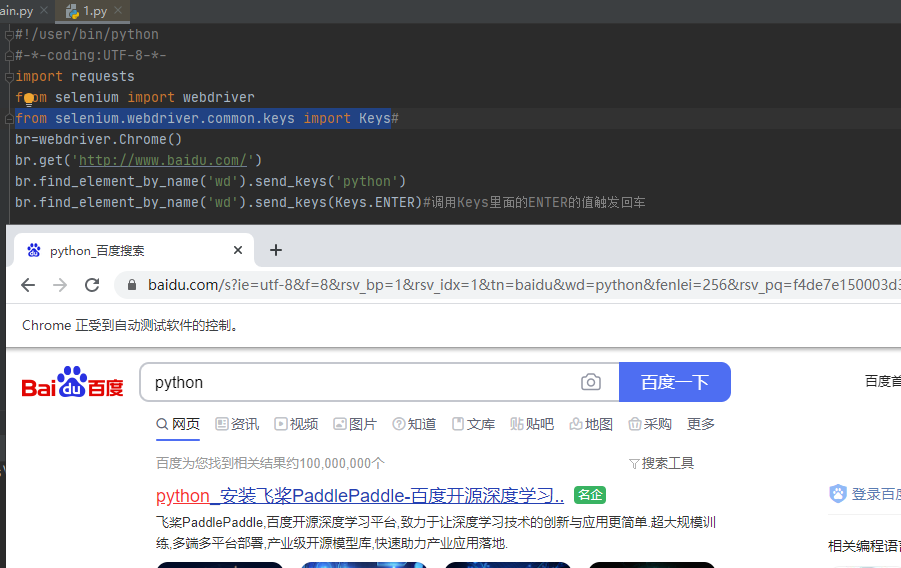
节点交互
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。 比较常见 的用法有:输入文字时用 send_keys()方法,清空文字时用 clear()方法,点击按钮时用 click()方法,也可以用Key。enter。 示例如下: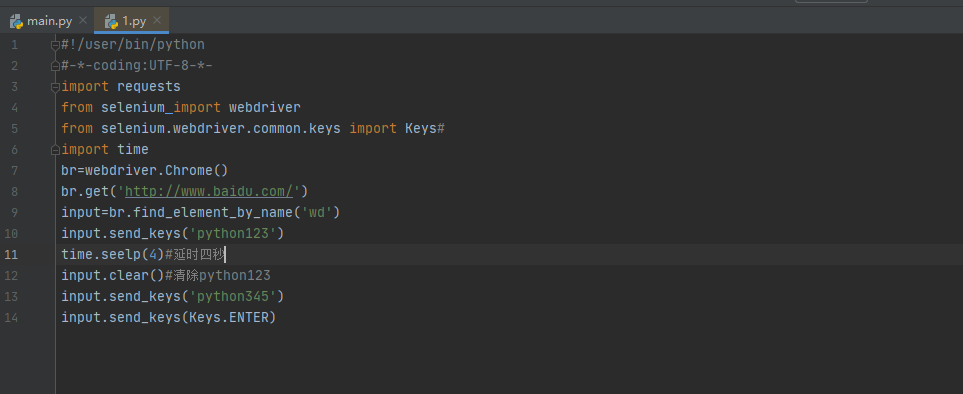
查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。 比如,我们想要完成向某 个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium 提供了一系列查找节点的方 法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
单个节点
比如,想要从百度页面中提取搜索框这个节点,首先要观察它的源代码,如图所示。
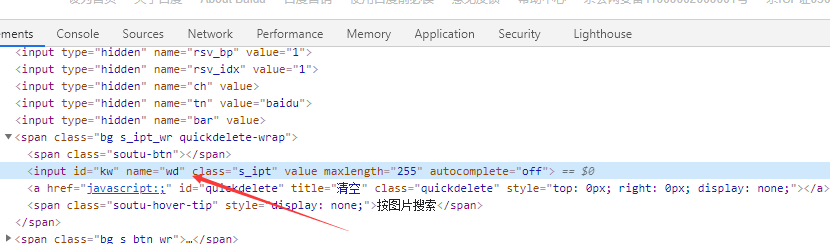
多个节点
多个节点 如果查找的目标在网页中只有一个,那么完全可以用 find_element()方法。 但如果有多个节点, 再用 find_element()方法查找,就只能得到第一个节点了。 如果要查找所有满足条件的节点, 需要用 find_elements()这样的方法。 注意,在这个方法的名称中, element 多了一个 s,注意区分
动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。 比如,对于输入框,我们就调用它的 输入文字和清空文字方法;对于按钮,就调用它的点击方法。 其实,还有另外一些操作,它们没有特 定的执行对象,比如鼠标拖曳、 键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
执行JavaScript
对于某些操作, Selenium API并没有提供。 比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute script()方法即可实现
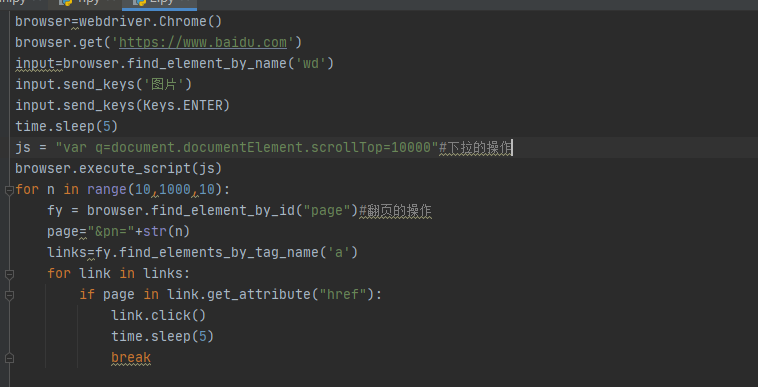
import requestsimport timefrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysbrowser=webdriver.Chrome()browser.get('https://www.baidu.com')input=browser.find_element_by_name('wd')input.send_keys('图片')input.send_keys(Keys.ENTER)time.sleep(5)js = "var q=document.documentElement.scrollTop=10000"browser.execute_script(js)for n in range(10,1000,10):fy = browser.find_element_by_id("page")page="&pn="+str(n)links=fy.find_elements_by_tag_name('a')for link in links:if page in link.get_attribute("href"):link.click()time.sleep(5)Break
**
5.2.7 获取节点信息
前面说过,通过 page_source 属性可以获取网页的源代码,接着就可以使用解析库(如正则表达 式、 Beautiful Soup、 pyquery 等)来提取信息了。
不过,既然 Selenium 已经提供了选择节点的方法,返回的是 WebElement 类型,那么它也有相关 的方法和属性来直接提取节点信息,如属性、文本等。 这样的话,我们就可以不用通过解析源代码来 提取信息了,非常方便。
获取属性
我们可以使用 get_attribute()方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:
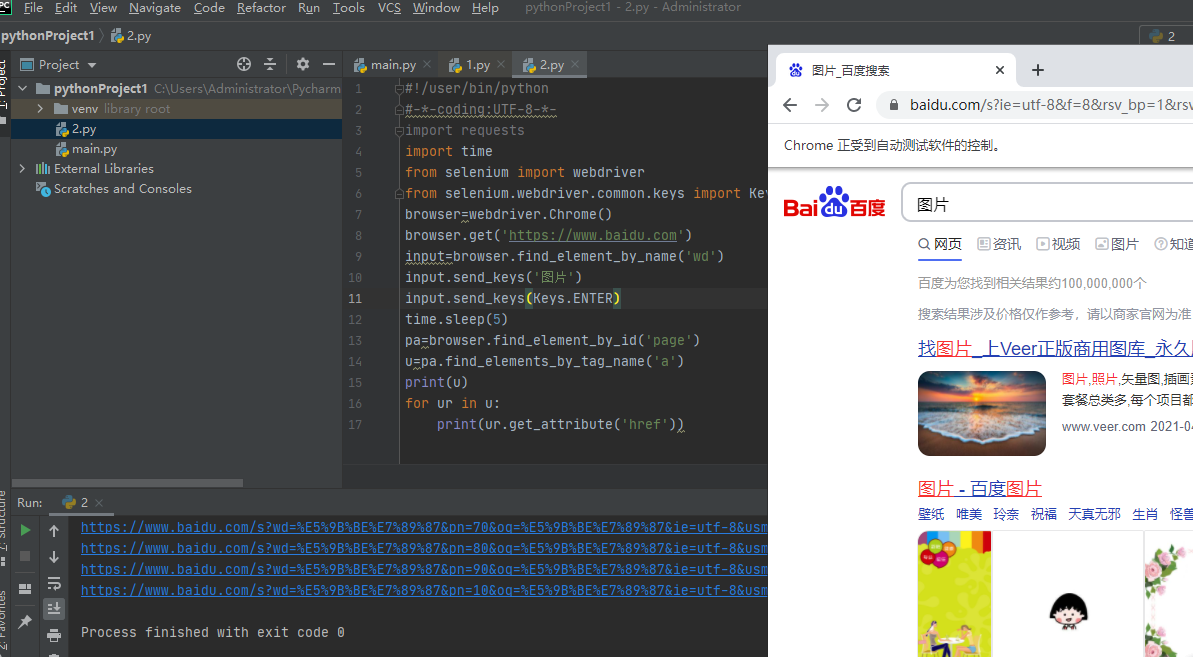
import requestsimport timefrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysbrowser=webdriver.Chrome()browser.get('https://www.baidu.com')input=browser.find_element_by_name('wd')input.send_keys('图片')input.send_keys(Keys.ENTER)time.sleep(5)pa=browser.find_element_by_id('page')u=pa.find_elements_by_tag_name('a')print(u)for ur in u:print(ur.get_attribute('href'))
获取文本值
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息,这相 当于 Beautiful Soup 的 get_text()方法、 pyquery 的 text()方法,示例如下:
import requestsimport timefrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysbrowser=webdriver.Chrome()browser.get('https://www.baidu.com')input=browser.find_element_by_name('wd')input.send_keys('图片')input.send_keys(Keys.ENTER)time.sleep(5)pa=browser.find_element_by_id('page')u=pa.find_elements_by_tag_name('a')print(u)for ur in u:print(ur.text)
获取 id、位置、 标签名和大小
另外, WebElement 节点还有一些其他属性,比如 id 属性可以获取节点 id , location 属性可以获 取该节点在页面中的相对位置, tag_name 属性可以获取标签名称, size 属性可以获取节点的大小,也 就是宽高,这些属性有时候还是很有用的。 示例如下:
pa=browser.find_element_by_id('page')print(pa.id)print(pa.location)print(pa.tag_name)print(pa.size)
5.2.8 COOkie 操作
print(browser.get_cookies())browser.delete_all_cookies()browser.add_cookie({'name':'cracer','domain':'www.baidu.com'})print(browser.get_cookies())browser.delete_all_cookies()print(browser.get_cookies())

若有收获,就点个赞吧
0 人点赞
