数据库
什么是缓存雪崩、击穿、穿透?
- 缓存雪崩:大量缓存数据同时过期,或者Redis宕机
应对方法:
大量缓存数据同时过期的应对方法:1.均匀的设置过期时间 2.互斥锁 3.双key策略 4.后台更新缓存
Redis宕机的应对方法:1.服务熔断或请求限流 2.构建Redis高可用集群
- 缓存击穿:热点数据缓存过期
应对方法:1.互斥锁方案 2.不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
- 缓存穿透:用户访问的数据既不在缓存中又不在数据库中
应对方法:非法请求的限制;缓存空值或者默认值;使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;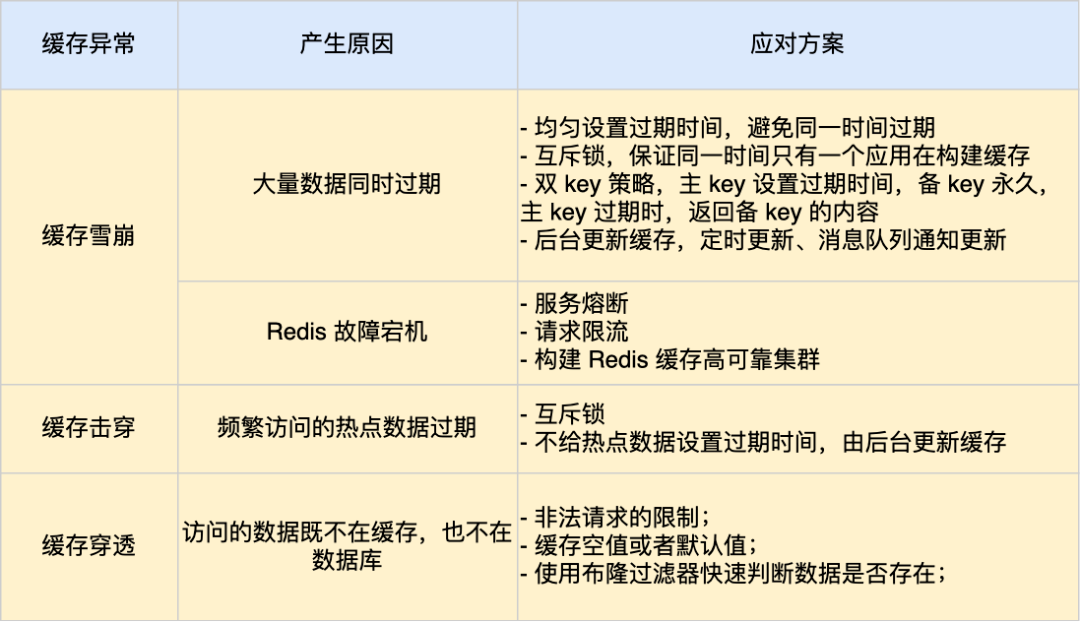
图片来源于 https://xiaolincoding.com/redis/cluster/cache_problem.html#%E6%80%BB%E7%BB%93
索引的分类
按数据结构分类可分为:B+tree索引、Hash索引、Full-text索引
按物理存储分类可分为:聚簇索引、二级索引(辅助索引)
按字段特性分类可分为:主键索引、普通索引、前缀索引
按字段个数分类可分为:单列索引、联合索引(复合索引、组合索引)
Hash索引适于key-value查询,通过Hash索引比B-tree索引查询更加迅速。但Hash索引不支持范围查找例如<><==,>==等。
(2)避免不走索引的场景
- 避免在字段开头模糊查询,会导致数据库放弃索引全表扫描
如:SELECT * FROM t WHERE username LIKE '%陈%'
改为:SELECT * FROM t WHERE username LIKE '陈%' - 尽量避免使用 in 和 not in,会导致引擎走全表扫描
- 如果是子查询,可以用 exists 代替
如:select * from A where A.id in (select id from B);
改为:select * from A where exists (select * from B where B.id = A.id); - 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描
可以用 union 代替 or,如下:SELECT * FROM t WHERE id = 1 OR id = 3改为SELECT * FROM t WHERE id = 1 UNION SELECT * FROM t WHERE id = 3 - 尽量避免进行 null 值的判断,会导致数据库引擎放弃索引进行全表扫描
如:SELECT * FROM t WHERE score IS NULL
改为0值判断:SELECT * FROM t WHERE score = 0 - 查询条件不能用 <> 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件 - order by 条件要与 where 中条件一致,否则 order by 不会利用索引进行排序
如:SELECT * FROM t order by age;
改为:SELECT * FROM t where age > 0 order by age;
UNIQUE(唯一索引)
不可以出现相同的值,可以有NULL值
INDEX(普通索引)
允许出现相同的索引内容
PRIMARY KEY(主键索引)
不允许出现相同的值,且不能为NULL值,一个表只能有一个primary_key索引
fulltext index(全文索引)
上述三种索引都是针对列的值发挥作用,但全文索引,可以针对值中的某个单词,比如一篇文章中的某个词,然而并没有什么卵用,因为只有myisam以及英文支持,并且效率低
- 维度高的列创建索引
数据列中不重复值出现的个数,这个数量越高,维度就越高
如数据表中存在8行数据a,b ,c,d,a,b,c,d这个表的维度为4
要为维度高的列创建索引,如性别和年龄,那年龄的维度就高于性别。性别这样的列不适合创建索引,因为维度过低 - 对 where、on、group by、order by 中出现的列使用索引
- 对较小的数据列使用索引
这样会使索引文件更小,同时内存中也可以装载更多的索引键 - 为较长的字符串使用前缀索引
- 不要过多创建索引,除了增加额外的磁盘空间外,对于DML操作的速度影响很大,因为其每增删改一次就得从新建立索引
- 使用组合索引,可以减少文件索引大小,在使用时速度要优于多个单列索引
减少数据的访问
返回更少的数据
减少交互次数
减少服务器 CPU 开销
利用更多资源
总结到SQL:
- 最大化利用索引
- 尽可能避免全表扫描
- 减少无效数据的查询
1、栈溢出Stack Overflow
(1)什么是栈溢出
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致栈中与其相邻的变量的值被改变
(2)栈溢出的原因
- 局部数组过大
局部变量是在栈中分配的 - 递归调用层次太多
递归函数在执行的时候会进行压栈操作 - 指针或者数组越界
例如字符串拷贝的时候

若有收获,就点个赞吧
0 人点赞
