好文
MySQL的三大范式
第一范式1NF
确保数据库字段的原子性,一个字段只存储一种数据
第二范式2NF
满足第一范式,表有主键,并且非主键列必须完全依赖于主键,而不是部分依赖
第三范式3NF
满足第二范式,并且非主键列必须直接依赖于主键列,不能存在传递依赖,即不能存在:非主键列A依赖于非主键列B,B依赖于主键
MySQL事务
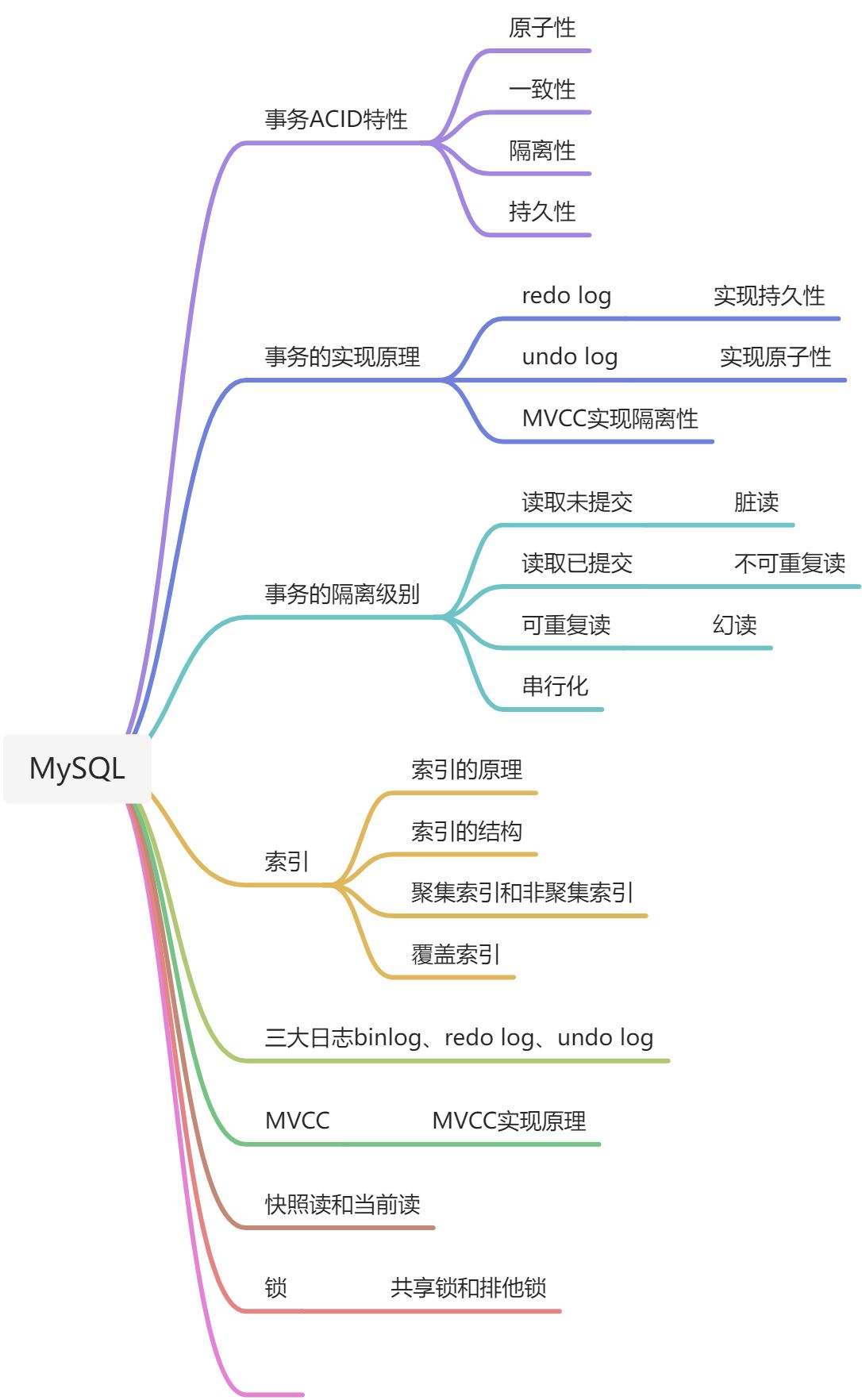
事务的ACID特性
原子性、一致性、隔离性、持久性
原子性:某个事务中的操作要么不发生,要么全部执行
一致性:事务执行前后,数据应保证一致。比如转账前后转账者和收款人的总额应该是不变的。
隔离性:并发访问数据库时,事务在执行过程中,应该不被其他事务所干扰,各并发事务之间的数据库是独立的。
持久性:一个事务被提交之后,它对数据库的改变是持久性的。
数据库事务的实现原理
MySQL InnoDB引擎通过redo log(重做日志)来保证事务的持久性,undo log(回滚日志)来保证事务的原子性
MySQL InnoDB引擎通过锁机制、MVCC来保证事务的隔离性
事务的隔离级别
READ-UNCOMMITTED(读取未提交)
一个事务可以读取到另一个事务未提交的数据,可能产生脏读
READ-COMMITTED(读取已提交)
允许读取并发事务已经提交的数据。不会产生脏读,但是可能会产生不可重复读、幻读
repeatable-read(可重复读)
一个事务读取一个数据时,是可重复读的。解决了不可重复读的问题,但是还是有可能发生幻读问题。
seriazable(串行化)
最高的隔离级别,每个事务一个一个运行。不会产生干扰。
MySQL默认的隔离级别是可重复读(READ-COMMITTED)
索引
索引用来快速检索数据,一般索引结构有Hash、B树、B+树。
Hash:使用Hash算法来快速通过key找到value值。
缺点:不支持范围查询和排序、哈希冲突问题
B树和B+树的区别?为什么用B+树不用B树?
1.B树的每个结点都存储key和数据,B+树只有叶子结点存储key和数据,其他结点只存放key
2.B树的每个结点都是独立的,B+树每个叶子结点都有一条引用链指向相邻的结点
3.B树的检索可能在任何一个结点结束,而B+树的检索很稳定,都是从根节点到叶子结点的过程
B+树叶子结点间有引用链,更适合范围查询;B+树检索效率更加稳定
实际生产环境的 B+ 树索引有多少层?
2~3层,存放2千万条数据
https://blog.csdn.net/ThinPikachu/article/details/121180127
MyISAM和InnoDB引擎的不同
MyISAM和InnoDB引擎底层都是用的是B+ Tree,但是两者的实现方式不同
MyISAM是非聚集索引,InnoDB是聚集索引
MyISAM使用非聚集索引,索引文件和数据文件是分离的,查询时先根据索引文件查询到位置,从叶子结点的data域中拿出数据记录的地址,然后在读取数据。被称为非聚集索引
InnoDB中,数据文件本身就是索引文件,数据文件就是按B+Tree组织的一个索引结构,树的叶子结点的data域保存了比较完整的数据。这个索引的Key就是表的主键,被称为聚集索引(聚簇索引)。其他的索引作为辅助索引,辅助索引叶子结点的data域存储的是主键的值而不是数据记录的地址,这是跟MyISAM不同的地方。
查询时,如果是根据主索引查询,直接找到key所在的位置就可以取出数据。根据辅助索引查找时,需要找出主索引的值,然后走一遍主索引。
MySQL的锁
按锁的粒度分:
行锁:锁某行的数据,锁的粒度最小,并发度高
表锁:锁整张表,锁粒度最大,并发度低
间隙锁:锁的是一个区间
共享锁:也就是读锁,一个事务加了读锁,其他事务可以读,但是不能写
排他锁:写锁,一个事务加了写锁,其他事务不能读也不能写
乐观锁:不会真正锁某行记录,通过一个版本号来实现的
悲观锁:上面的行锁、表锁都是悲观锁
MVCC
MVCC(Mutiversion concurrency control)是同一份数据保留多个版本的方式,进而实现并发控制。查询的时候通过read view和版本链找到对应版本的数据
作用:提高并发性能。对于高并发场景,MVCC比行级锁开销更小
MVCC实现原理
MVCC的实现依赖于版本链,版本链通过表的三个隐藏字段实现。
DB_TRX_ID:当前事务id,通过事务id的大小判断事务的时间顺序
DB_ROLL_PRT:回滚指针,指向当前行记录的上一个版本,通过这个指针将数据的多个版本连接在一起构成undo log版本链
DB_ROLL_ID:主键,如果没有主键,InnoDB自动生成主键
生成版本链的过程
当事务更新该行记录时,就会生成版本链,过程如下:
1.排他锁锁住该行
2.将该行原本的值拷贝到undo log,作为版本链用于回滚
3.修改当前行的值,更新事务id,并且使回滚指针指向旧版本的记录,形成一条版本链
read view的实现
read view可以理解成将数据在每个时刻的状态都记录下来。获取某t时刻的数据时,到此时刻去取数据
read view内部维护一个活跃事务的链表,存储创建read view之前还未提交的事务。
在当前事务执行过程中,根据readview可以知道可以访问哪些数据
每个数据行都有一个最新事务id,表示最新被哪个事务修改过,
如果这个值大于readview中最大的活跃事务id,说明修改数据的事务在readview生成之后执行的,不可被当前事务访问,然后通过版本链找到上一个版本,再次判断数据是否可见。
如果这个值小于readview中最小的活跃事务id,说明修改这个数据的事务已经在readview生成之前提交了,可以被访问
如果这个值介于两者之间,那么在活跃事务id中寻找是否存在等于这个事务id的值,如果存在,说明事务还没提交,不可访问,如果不存在,说明事务已经提交了,可以访问。
MySQL引擎
InnoDB引擎和MyISAM引擎的区别
事务和崩溃后的恢复:InnoDB支持事务和崩溃后的回滚和恢复,MyISAM不支持事务
行级锁:InnoDB支持行级锁和表级锁,默认为行级锁,MyISAM只支持表级锁
外键:InnoDB支持外键,MyISAM不支持外键
MVCC:InnoDB支持,MyISAM不支持
索引:InnoDB使用聚簇索引,MyISAM使用非聚簇索引
详细见上面索引下的两个引擎的不同处
快照读和当前读
快照读:如SELECT,使用MVCC进行并发控制,不用加锁
当前读:如UPDATE、DELETE、INSERT
快照读情况下,可以使用MVCC解决幻读现象,但是MVCC无法解决当前读的幻读问题,因为当前读每次读的都是最新数据,这时如果两次查询中间有其他事务插入数据,就会产生幻读现象。
那么MySQL是如何避免幻读?
- 快照读情况下,使用MVCC
- 当前读情况下,使用next-key实现,加行锁和间隙锁
next-key包括两部分:行锁和间隙锁。行锁是加在索引上的锁,间隙锁是加在索引之间的。
串行化的隔离级别也可以避免幻读问题,但不推荐。
大表怎么优化
1.限制查询的时间范围
2.读写分离,主库负责写,从库负责读
3.通过分库分表的方式进行优化,主要有水平拆分和垂直拆分
慢查询的优化
三大日志bin log、redo log、undo log
bin log是MySQL数据库级别的日志文件,记录对于数据库的执行修改的所有操作,不会记录select语句,主要用于数据库的同步和恢复
redo log是innodb引擎级别的日志文件,用来记录innodb引擎的事务日志,不管事务是否提交都会被记录下来,用于数据恢复。当数据库发送故障,innodb会使用redo log恢复到故障发生的时候,保证数据的完整性。
undo log是回滚日志,当进行数据修改时,undo log保存修改前的数据,可以实现事务的回滚,实现回滚到某个版本的数据,实现MVCC
bin log和redo log的区别
1.bin log会记录所有日志记录,包括Innodb、MyISAM引擎级别的日志;redo log只记录Innodb自身的日志记录
2.bin log是逻辑日志,记录SQL的原始逻辑,redo log是物理日志,只记录在某个数据页上做了什么修改。
3.bin log会在事务提交前写入磁盘,一个事务只写一次,而redo log在事务进行中,只要更新发生就会不断写入。

若有收获,就点个赞吧
0 人点赞
