《MySQL是怎样运行的》
InnoDB行格式
页是InnoDB中磁盘和内存交互的基本单位,也是InnoDB管理存储存储单元的基本单位,默认为16KB
InnoDB的四种行格式
- COMPACT行格式
- REDUNDANT行格式

- DYNAMIC和COMPRESSED行格式
溢出列
在COMPACT和REDUNDANT行格式汇总,对于占用存储空间非常多的列,在记录的真实数据处只会存储该列的一部分数据,而把剩余数据分散存储在几个其他的页中,然后在记录的真实数据处用20字节存储指向这些页的地址和分散在其他页面的数据所占用的字节数,从而找到剩余数据所在的页。
这些因为列占用空间太多而一页存储不下而将剩余数据存储到其他页,存储剩余数据的页面,称为溢出页。InnoDB数据页结构
各个数据页组成一个双向链表,每个数据页中的记录都会按照主键值从小到大的顺序组成一个单向链表。
每个数据页都会为存储在它里面的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可找到指定的记录。
每个数据页都是按照下图的结构,以下内容详细解释每个部分的作用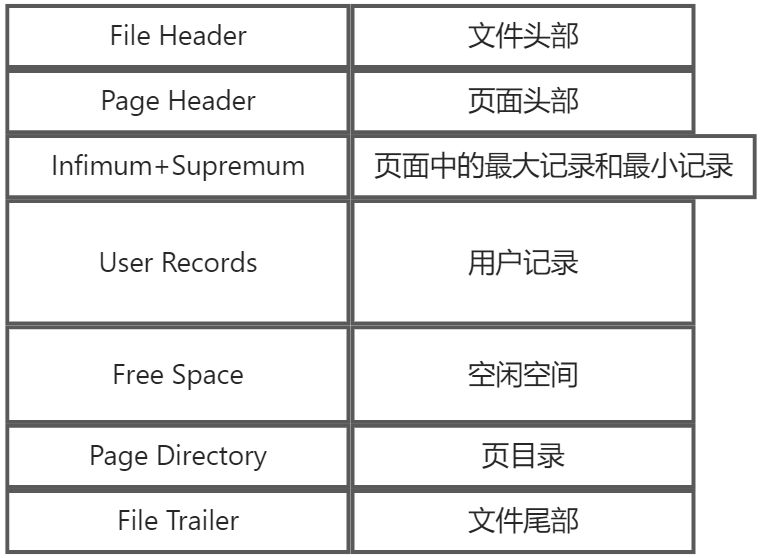
User Records中的记录信息
我们向表中插入的数据都是放到数据页的User Records部分
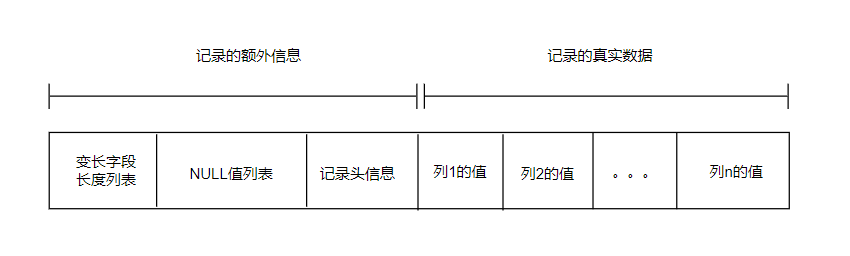
COMPACT行格式中的记录头信息
COMPACT行格式记录的额外信息中有:变长字段长度列表、NULL值列表、记录头信息
记录头信息的属性有:deleted_flag、min_rec_flag、n_owned、heap_no、record_type、next_record
- deleted_flag
- 被删除的记录不会从磁盘移除,因为移除他们后,还需要在磁盘上重新排列其他的记录,这会带来性能消耗,所有只打一个删除标记就可以避免这个问题。所有被删除的记录组成一个垃圾链表,记录在这个链表占用的空间称为可重用空间
- min_rec_flag
- B+树每层非叶子节点中的最小的目录项会添加此标记
- n_owned
- heap_no
- 表示一条记录在堆(User Records中)中的相对位置
- 堆中记录的heap_no值再分配之后就不会发生改动了,即使之后删除了堆中的某条记录,这条被删除记录的heap_no值也保持不变
- 每个数据页都有两条虚拟记录(伪记录),一条代表页面中的最小记录(Infimum),一条代表页面中的最大记录(Supremum)
- record_type
- 记录的类型:0表示用户记录,1表示B+树非叶结点的目录项记录,2表示Infimum,3表示Supremum
- next_record
- 通过二分法确定该记录所在分组对应的槽
- 通过记录的next_record属性遍历该槽所在的组中的各个记录
Page Header页面头部
存储数据页中的记录的状态信息,部分字段如下
PAGE_N_DIR_SLOTS 在页目录中的槽数量
PAGE_LAST_INSERT 最后插入记录的位置
PAGE_N_RECS 该页中用户记录的数量(不包括Infimum和Supremum以及被删除的记录)File Header 文件头部
描述一些通用于各种页的信息(38字节),部分字段如下,
FIL_PAGE_SPACE_OR_CHKSUM:当前页面的校验和
FIL_PAGE_OFFSET:每个页都有一个单独的页号,InnoDB通过页号来唯一定位一个页
FIL_PAGE_TYPE:表示当前页的类型。
FIL_PAGE_PREV和FIL_PAGE_NEXT:分别代表数据页的上一个页和下一个页的页号。存储记录的数据页是可以通过这两个属性来组成一个双向链表File Trailer文件尾部
一共八字节
前四字节代表页的校验和
后四字节代表页面被最后修改时对应的LSN的后四字节,正常情况下应该与File Header部分的FIL_PAGE_LSN的后字节相同。用来校验页的完整性。B+树索引
没有索引时的查找
在一个页中查找:
- 以主键为搜索条件:在页目录使用二分法快速定位到槽;然后再遍历该槽对应的分组中的记录
- 以其他列为搜索条件:依次遍历页中的每条记录
在很多页中查找:
- 定位到记录所在的页
- 从所在的页内查找对应的记录
一个简单的索引方案
给所有页建立一个目录项,每个目录项包含两个部分:页的用户记录中最小的主键值key、页号page_no。
在对页中记录进行增删改操作的过程中,我们必须通过一些记录移动等操作来始终保持这个状态一直成立: 必须满足下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值,这个过程叫页分裂。
InnoDB中的索引方案
InnoDB复用了之前存储用户记录的数据页的结构来存储目录项
目录项和普通的用户记录的不同点:
- 目录项记录的record_type值是1,而普通用户记录的record_type值是0
- 目录项只能主键值和页的编号两个列,而普通用户记录的列是用户自己定义的,可能包含很多列,另外还有InnoDB自己添加的隐藏列。
- 目录项的记录头信息中的min_rec_flag属性为1,普通用户记录的min_rec_flag属性都是0
查询记录的步骤
- 确定存储目录项记录的页
- 通过存储目录项记录的页确定用户记录真正所在的页
- 二分法快速定位到对应的目录项记录
- 在真正存储用户记录的页定位到具体的记录
二级索引
联合索引

若有收获,就点个赞吧
0 人点赞
