计算机网络
TCP协议 流量控制 连接双方都有固定大小的缓冲区,接收端只允许发送端发送接收段缓冲区大小的数据,当接收方来不及处理发送方发送的确认数据时候,会提示发送方降低发送速率。TCP使用滑动窗口协议实现流量控制
GET 请求和 POST 请求的区别
- HTTP报文层面,GET请求将信息放到url中,POST请求将信息放到请求体中
- 数据库层面,GET请求是幂等性和安全性的,POST不是
- 缓存,GET 请求能够被缓存,POST不可以
第二次挥手和第三次挥手能否合并
可以合并
TCP四次挥手里,第二次和第三次挥手之间,是有可能有数据传输的。第三次挥手的目的是为了告诉主动方,”被动方没有数据要发了”。
在第一次挥手之后,如果被动方没有数据要发给主动方。第二和第三次挥手是有可能合并传输的。这样就出现了三次挥手。详细讲一下TCP的滑动窗口?
为什么TCP需要滑动窗口?如果TCP没有滑动窗口,那么TCP发送一个请求,必须等待接收到上一个请求的应答,才会继续发送下一个请求。这样的方式有个缺点:往返时间越长,通信效率越低。而滑动窗口解决了这个问题滑动窗口的工作过程
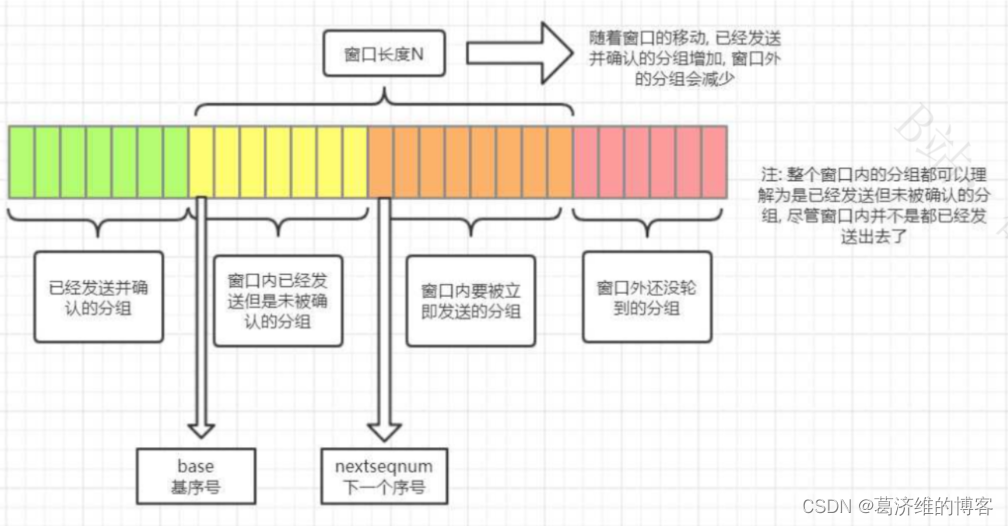
如图用自己的语言讲述
以发送方的滑动窗口为例,滑动窗口左边是已经发送并收到确认的分组,滑动窗口右边是未发送并超过窗口范围的分组,滑动窗口内部又分为两个区域:一个是已经发送但是未收到确认的分组,一个是即将发送的分组
当已经发送的窗口收到确认时,窗口会向右移,之前在窗口右边的分组就会移动到窗口内部
滑动窗口的作用
流量控制
流量控制是什么?
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制
为什么要进行流量控制?
发送方如果无脑发送数据给接收方,但是接收方处理不过来,那么就会导致触发超时重传,从而导致网络资源的浪费
怎么进行流量控制?
连接双方都有固定大小的缓冲区,接收端只允许发送端发送接收端缓冲区大小的数据,当接收方来不及处理发送方发送的数据时候,会降低窗口的大小,使得发送方的发送速率降低.
拓展知识:
如果发送窗口降低为0,那么发送方停止发送数据,等待接收方处理数据后主动通知发送方,但是发送方会隔一段时间(指数增加)发送一个窗口探测报文,探测发送到一定次数,并且窗口大小一直为0时,发送方会关闭连接。 窗口探测的次数一般为 3 次,每次大约 30-60 秒(不同的实现可能会不一样)。如果 3 次过后接收窗口还是 0 的话,有的 TCP 实现就会发
RST报文来中断连接。 发送方发送窗口的大小取 接收方窗口的大小和拥塞窗口的最小值
2、拥塞避免
- 慢开始
- 拥塞避免
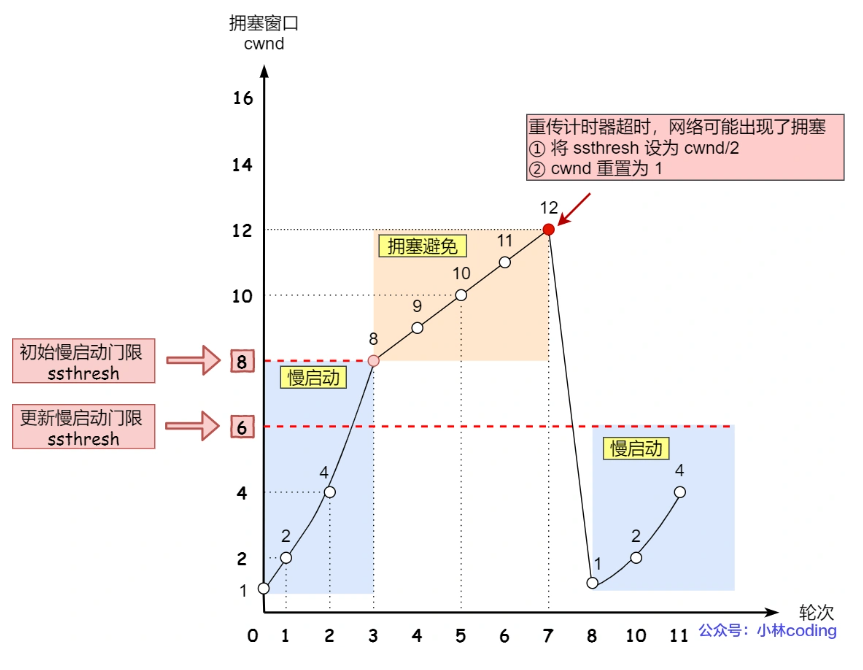
- 快重传和快恢复
3、ARQ协议
发送完一个分组就停止等待确认报文,收到确认报文后在发送下一个分组数据
SYN Flood攻击
什么是SYN Flood?
SYN Flood属于典型的DDoS攻击,攻击的原理就是短时间内伪造大量不存在的IP,向服务器疯狂发送SYN;
造成的结果:
- 处理大量SYN请求并返回ACK,会有大量的连接处于SYN_RECV的状态,占满整个半连接队列 ,无法处理正常的请求
由于是不存在的IP,那么服务端收不到客户端的ACK请求,会导致服务端不断超时重传,直到耗尽服务端资源
如何应对SYN Flood攻击?
增加SYN连接,也就是增加半连接队列的容量
- 减少SYN+ACK的重试次数,减少超时重发
- 利用 SYN Cookie 技术,在服务端接收到 SYN 后不立即分配连接资源,而是根据这个 SYN 计算出一个Cookie,连同第二次握手回复给客户端,在客户端回复ACK 的时候带上这个 Cookie 值,服务端验证 Cookie 合法之后才分配连接资源。
附加的需要了解的概念
三次握手前,服务端的状态从 CLOSED 变为 LISTEN , 同时在内部创建了两个队列: 半连接队列和全连接队列,即SYN队列和ACCEPT队列 半连接队列 当客户端发送 SYN 到服务端,服务端收到以后回复 ACK 和 SYN ,状态由 LISTEN 变为 SYN_RCVD ,此时这个连接就被推入了SYN队列,也就是半连接队列。 全连接队列 当客户端返回 ACK , 服务端接收后,三次握手完成。这个时候连接等待被具体的应用取走,在被取走之前,它会被推入另外一个 TCP 维护的队列,也就是全连接队列(Accept Queue)。
HTTP状态码
| 状态码 | 类别 |
|---|---|
| 1XX | 信息性状态码 |
| 2XX | 成功状态码 |
| 3XX | 重定向状态码 |
| 4XX | 客户端错误状态码 |
| 5XX | 服务端错误状态码 |
1XX
- 100 Continue:表示正常,客户端可以继续发送请求
- 101 Switching Protocols:切换协议,服务器根据客户端的请求切换协议。
2XX
- 200 OK:请求成功
- 201 Created:已创建,表示成功请求并创建了新的资源
- 202 Accepted:已接受,已接受请求,但未处理完成。
- 204 No Content:无内容,服务器成功处理,但未返回内容。
- 205 Reset Content:重置内容,服务器处理成功,客户端应重置文档视图。
- 206 Partial Content:表示客户端进行了范围请求,响应报文应包含Content-Range指定范围的实体内容
3XX
- 301 Moved Permanently:永久性重定向
- 302 Found:临时重定向
- 303 See Other:和301功能类似,但要求客户端采用get方法获取资源
- 304 Not Modified:所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。
- 305 Use Proxy:所请求的资源必须通过代理访问
- 307 Temporary Redirect: 临时重定向,与302类似,要求使用get请求重定向。
4XX
- 400 Bad Request:客户端请求的语法错误,服务器无法理解。
- 401 Unauthorized:表示发送的请求需要有认证信息。
- 403 Forbidden:服务器理解用户的请求,但是拒绝执行该请求
- 404 Not Found:服务器无法根据客户端的请求找到资源。
- 405 Method Not Allowed:客户端请求中的方法被禁止
- 406 Not Acceptable:服务器无法根据客户端请求的内容特性完成请求
- 408 Request Time-out:服务器等待客户端发送的请求时间过长,超时
5XX
- 500 Internal Server Error:服务器内部错误,无法完成请求
- 501 Not Implemented:服务器不支持请求的功能,无法完成请求
502 Bad Gateway是指错误网关,无效网关;在互联网中表示一种网络错误;表现在WEB浏览器中给出的页面反馈;它通常并不意味着上游服务器已关闭(无响应网关/代理) ,而是上游服务器和网关/代理使用不一致的协议交换数据
HTTP请求头
https://segmentfault.com/a/1190000018234763
(1)General
(不属于headers,只用于收集请求url和响应的status等信息)
Request URL
- Request Method
- Status Code
-
(2)Request Headers
Accept
- Accept-Encoding
- Connection
- Cookie
- Host
- Origin
-
(3)Response Headers
cache-control
- connection
- data
操作系统
问题4 五种IO模型
阻塞IO 模型
假设应用程序的进程发起IO调用,但是如果内核的数据还没准备好的话,那应用程序进程就一直在阻塞等待,一直等到内核数据准备好了,从内核拷贝到用户空间,才返回成功提示,此次IO操作,称之为阻塞IO。非阻塞IO模型
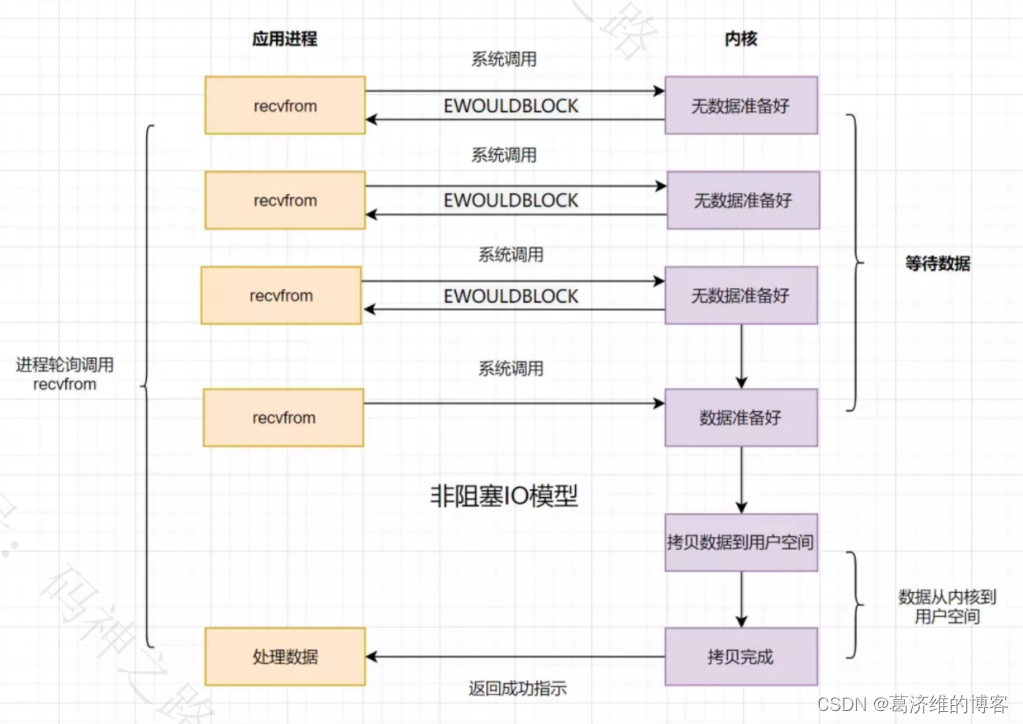
如果内核数据还没准备好,可以先返回错误信息给用户进程,让它不需要等待,而是通过轮询的方式再来请求。这就是非阻塞IO,流程图如下
IO多路复用模型
IO多路复用之select
应用进程通过调用select函数,可以同时监控多个fd(文件描述符),在select函数监控的fd中,只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时应用进程再发起recvfrom请求去读取数据
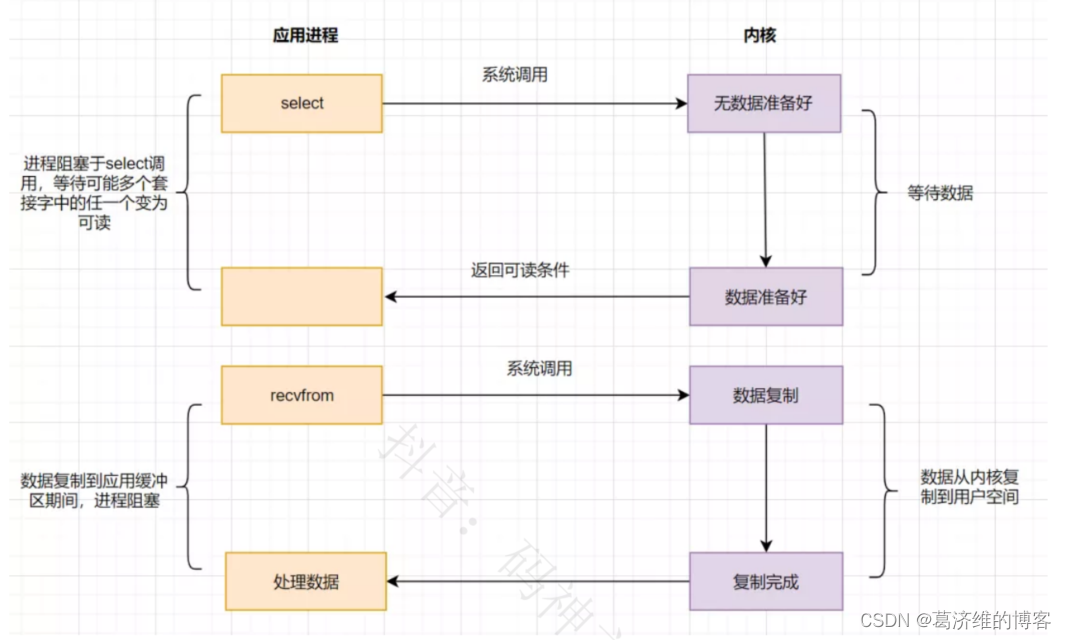
select有几个缺点:
- 最大连接数有限,在Linux系统上一般为1024。
- select函数返回后,是通过遍历fdset,找到就绪的描述符fd。
IO多路复用之epoll
为了解决select存在的问题,多路复用模型epoll诞生,它采用事件驱动来实现,流程图如下
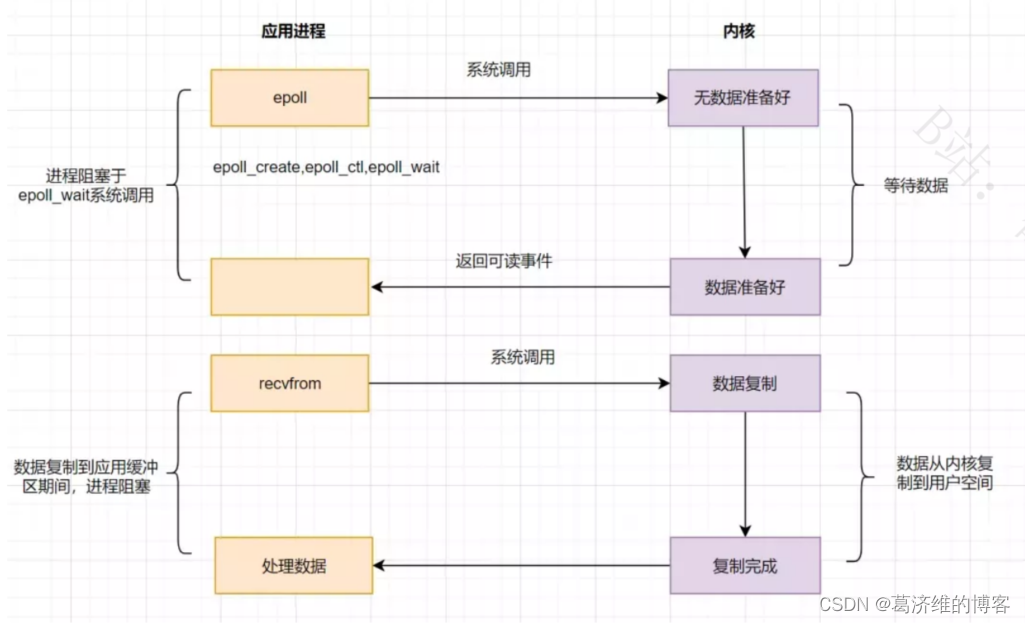
epoll先通过epoll_ctl()来注册一个fd(文件描述符),一旦基于某个fd就绪时,内核会采用回调机制,迅速激活这个fd,当进程调用epoll_wait()时便得到通知。这里去掉了遍历文件描述符的坑爹操作,而是采用监听事件回调的机制。这就是epoll的亮点。
IO模型之信号驱动模型
IO 模型之异步IO(AIO)
补充:
BIO和NIO区别? 4核cpu,100个http连接,用BIO和NIO分别需要多少个线程 BIO是阻塞的,NIO是多路复用的 BIO要100个 NIO要5个 一个接受请求,四个处理请求
内存管理机制
块式管理、页式管理、段式管理、段页式管理
块式管理:很早之前计算机操作系统内存管理的方式,将内存分为几个固定大小的块,
页式管理:
段式管理:
段页式管理
块表的概念
进程切换的消耗为什么比线程切换要多?
- 进程切换需要切换虚拟地址空间,而同一个进程中的线程是共享进程的虚拟地址空间的,所以线程切换不用切换虚拟地址空间
- 页表切换导致TLB失效。每个进程都有页表来进行虚拟地址到物理地址的转换,进程切换时,页表也跟着相应的切换;因为页表查询是个很慢的过程,操作系统使用TLB缓存页表,当页表切换后,TLB缓存就会失效,表现就是程序运行变慢。
第二种回答: 每个进程都有对应的页表,进程切换的时候需要切换页表,为了加快虚拟地址的地址转换效率,所以引入了TLB来缓存对应的虚拟地址和物理地址的映射。 切换页表这个操作本身是不太耗费时间的,切换之后,TLB就失效了,所以在进行地址转化的时候需要重新去查找页表,这就造成了程序运行的效率低下。 同一个进程的线程之间是共用一个页表的,所以线程之间的切换是不需要切换页表的。 原文链接:https://blog.csdn.net/qq_40276626/article/details/122070810
参考:
https://blog.csdn.net/qq_40276626/article/details/122070810
https://blog.csdn.net/weixin_41803650/article/details/113660996
https://blog.csdn.net/qq_34417408/article/details/110393655
第三种回答: 进程与线程最大的区别在于上下文切换过程中,线程不用切换虚拟内存,因为同一个进程内的线程都是共享虚拟内存空间的,线程就单这一点不用切换,就相比进程上下文切换的性能开销减少了很多。由于虚拟内存与物理内存的映射关系需要查询页表,页表的查询是很慢的过程,因此会把常用的地址映射关系缓存在 TLB 里的,这样便可以提高页表的查询速度,如果发生了进程切换,那 TLB 缓存的地址映射关系就会失效,缓存失效就意味着命中率降低,于是虚拟地址转为物理地址这一过程就会很慢
参考:https://xiaolincoding.com/cs_learn/cs_learn.html#%E4%B8%89%E3%80%81%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F
数据库
三大范式
第一范式:所有列不可再分
第二范式:消除所有非主属性对对主属性的部份依赖
第三范式:消除所有非主属性对主属性的传递依赖
为什么redis快?
- 完全基于内存,绝大部分请求是内存操作,执行效率高
- 数据结构简单,对数据操作也简单
- 采用单线程,单线程也能处理高并发请求
- 使用多路I/O复用模型,非阻塞IO
redis数据类型:String Hash List Set ZSet
问题7
一:java集合种类
二:什么场景下用ArrayList,有哪些线程安全的集合,LinkedList怎么改双向?(这个问题当时我没太懂)
三:HashMap的扩容机制,红黑树,在map节点是链表的情况下发生put冲突会导致什么样的情况?
四:讲下ConcurrentHashMap;
五:讲下CAS是如何工作的?
六:线程池,为什么在阻塞队列满之后才开始使用最大线程,而不是一开始就使用?
七:讲下悲观锁与乐观锁
八:线程顺序打印有哪些方法实现?
九:(数据库)事务的隔离级别,课重复读会出现的错误?
十:索引,如何建立索引,B+树的叶子节点是单指针还是双指针;

若有收获,就点个赞吧
0 人点赞
