计算机网络
关于好的文章
https://blog.csdn.net/qzcsu/article/details/72861891 TCP握手挥手详解
访问url会发生什么
- DNS查询(递归和迭代)
- HTTP报文生成
- TCP封装头部(源端口、目的端口)建立TCP三次握手
- IP封装头部(原地址、目的地址)
- 数据链路层、物理层(网卡、交换机、路由器)发送出去
- 返回html资源,浏览器加载
- 断开连接
- 浏览器输入URL后,首先对这个URL地址进行解析,确定域名和需要请求的资源文件的路径
然后生成HTTP报文,生成完成后,现在还不知道要发往哪里 - 通过DNS查询域名对应的IP地址,首先浏览器会查询浏览器缓存,然后操作系统也会查询自己的缓存,还有host文件中有没有对应的域名的缓存,如果没有,最后再去问本地域名服务器
- 本地域名服务器会向根域名服务器发送请求,根域名服务器会告知本地域名服务器下一次请求的顶级域名服务器地址,然后本地域名服务器继续发起请求;请求经过根域名服务器->顶级域名服务器->最后到权威级别的域名服务器,找到对应的IP地址
- 通过DNS获取IP地址后,浏览器会将HTTP报文的传输工作交给操作系统中的协议栈,协议栈上部分是TCP/UDP,经过TCP封装一个TCP头部,TCP头部主要包括源端口、目的端口、序号、确认序号、状态位、窗口大小(进行流量控制),如果HTTP数据包的长度超过了MSS(TCP最大报文长度)那么TCP会将HTTP报文进行拆分。
- 这些数据包在网络层由IP层封装一个IP头部,由IP协议进行发送,IP头部有源IP地址、目的IP地址、协议(06TCP)、片偏移等,在DNS查询到的IP地址在此处就放入目的IP地址字段
经过数据链路层封装成帧、物理层的网卡、交换机、路由器到达另一台主机,实现发送的过程,接受过程就是拆头部的过程,就实现了两台主机之间的通信。
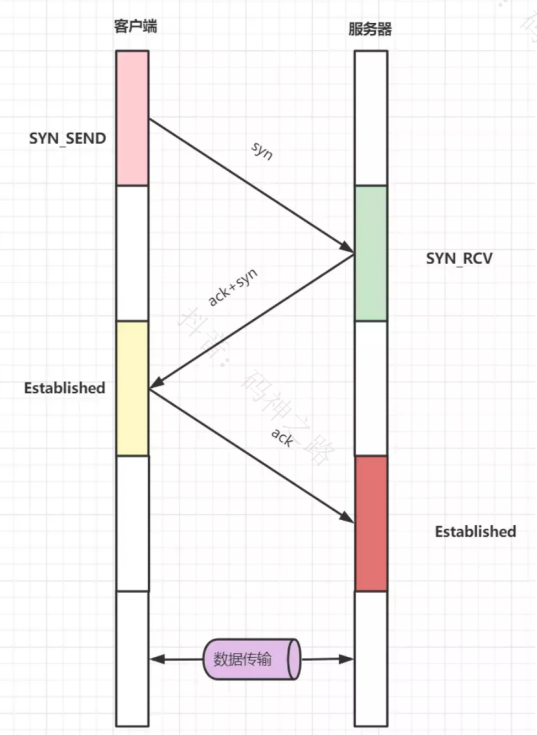
TCP三次握手
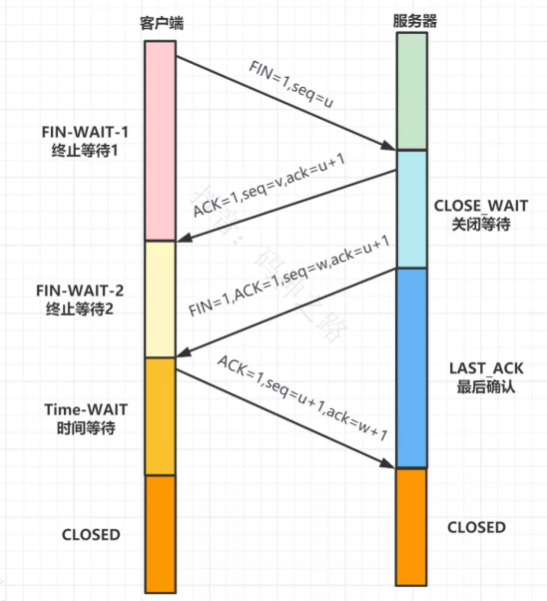
TCP四次挥手
HTTP1.1和1.0的区别?
HTTP1.1使用长连接的方式,减少了每次请求都进行三次握手的开销
支持管道的网络传输方式,请求发出去不用等待请求的回应,可以直接发送下一个请求
HTTP1.0和2.0的区别?
HTTP/2做了一下改进
头部压缩
- 如果是同时发送多个请求,请求的头部都是一样的,协议会帮你消除重复的部分,在服务端和客户端维护一张头部信息表,只需要
- 二进制格式,增加数据传输的效率
- 数据流
- 多路复用
- 服务器推送
操作系统
进程和线程的区别
课本知识:
进程是资源调度的基本单位,线程是CPU调度的基本单位。线程是进程的一部分,计算机内软硬件资源分配与线程无关,线程只能共享它所属进程的资源。进程拥有一个完整的虚拟地址空间,线程没有自己的地址空间。进程不依赖于线程而独立存在。
线程的缺点:
- 匿名管道:半双工,只能在父子进程间通信。(C中对应的api:int pipe(int fd[2]))
- 有名管道:半双工,允许非父子进程间的通信。
- 不管是匿名管道还是有名管道,进程写入的数据都是缓存在内核中,另一个进程读取时也是在内核中读取,同时通信数据遵循先进先出的原则
- Linux命令中的
|就是匿名管道,是单向传输数据的
- 消息队列:(在Linux中)也称作信箱,内核提供的链表结构,有对应的C语言api。
- 消息队列可以实现两个进程间频繁的通信数据
- 缺点是 不合适比较大的数据传输、通信过程中存在内核态和用户态之间的数据拷贝开销
- 信号量:一种计数器,常作为锁机制,主要用作进程间的同步手段。
- 用来进行PV操作,进行进程间的互斥和同步
- 共享内存:由一个进程创建的可被多个进程访问的共享内存。可搭配信号量等机制实现同步的信息通信。
- 消息队列的读取和写入过程中,都有发生用户态和内核态的数据拷贝开销,而共享内存解决了这个问题
- 共享内存的机制,就是两个进程都拿出一块虚拟地址空间来,映射到同一块物理内存上
- 套接字:走网络途径,可用于不同主机上的进程间的通信。
信号:信号是进程间通信机制中唯一的异步通信机制,可以在任何时候发送信号给进程。
线程间通信方式
共享内存:(java:体现为公共变量,一般加锁或加volatile保证原子性、可见性)
- 消息传递:(java:体现为如wait/notify、join等方法)
- 管道流: (java:体现为PipedOutputStream、PipedInputStream等IO类)
虚拟内存
虚拟内存在平常很容易看到,比如Windows系统运行了很多程序,这些程序所占用的内存大小远远超出了物理内存的大小,虚拟内存给程序一种自己在独享操作系统内存的假象,为程序分配一个连续的虚拟地址空间,而实际上,这些空间在物理内存上是离散的,还有一部分存储在磁盘上。
虚拟内存实现的基础是:局部性原理。因为程序运行具有局部性原理,因此我们可以只装入一部分程序在内存上,其他留在外存,程序就可以开始运行。局部性原理,分为空间局部性和时间局部性;空间局部性是指最近访问过的数据,它周围的数据很有可能被再次访问;时间局部性是指最近执行过的指令,最近还有可能再次执行;虚拟内存地址
引入:单片机只能执行一条程序,因为它直接操作物理内存
操作系统为了解决这个问题,引入了虚拟地址,提供了一种机制,可以将不同进程的虚拟地址和不同内存的物理地址映射起来。这样程序访问虚拟地址,由操作系统转换成不同的物理地址,不同的程序操作的是不同的物理内存,不会发生冲突。
在这里就引出了两种地址的概念:
程序所使用的的就是 虚拟内存地址
硬件中的地址就是 物理内存地址
虚拟内存地址到物理内存地址的映射是通过 CPU芯片中的内存管理单元(MMU) 实现的
引申:
操作系统是如何管理虚拟地址与物理地址之间的关系?
Todo
死锁
死锁产生的条件:互斥访问、不可剥夺、占有且等待、环路等待
- 死锁防止
破坏占有且等待条件:采用静态分配方式,进程在执行前就获取全部资源,直到获取到所有资源再开始执行。
破坏环路等待条件:给资源编号,进程获取资源必须按照编号顺序依次进行。
破坏不可剥夺条件:进程获取资源,必须释放已占有的其他资源。
- 死锁避免
判定和检测安全状态,如果分配一个资源会进入不安全的状态,则拒绝分配这个资源。
相关:银行家算法。
- 死锁检测和恢复
数据库
实际生产环境的 B+ 树索引有多少层?
2~3层,存放2千万条数据
https://blog.csdn.net/ThinPikachu/article/details/121180127
Mysql索引
索引的底层数据结构有哈希表、B+树、B树
Mysql索引底层是使用B+树实现的,B+树和B树的区别
- B树所有结点既存放索引值,也存放数据;B+只有叶子结点存放数据,非叶子结点存放索引值(疑问,索引值和数据值对应到数据库是啥?不太明白)
- B树的每个结点都是独立的,而B+树叶子结点有一条引用链指向他相邻的叶子结点
- B树的搜索可能在任何位置结束,B+树搜索是从根节点到叶子结点,检索效率更稳定
聚簇索引和非聚簇索引
TODOmysql日志
binlog、redo log、undo log
TODOMySQL的锁有哪些
行锁、表锁、间隙锁
?具体不清楚怎么回答了
一条SQL语句执行的流程
TODO细节问题待补充
图示: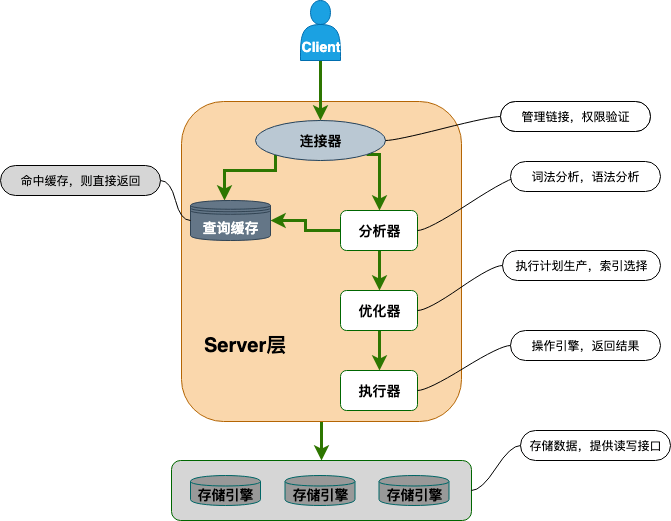
查询语句的流程
- 连接器(权限验证)
- 查询缓存
- 分析器(词法分析、语法分析)
- 优化器
- 执行器(权限验证、调用执行引擎的接口)
TODO待补充
更新语句的流程(此处细节问题很多)
- 分析器
- 权限验证
- 执行器
- 引擎
- redo log(prepare状态)
- binlog
- redo log(commit状态)

若有收获,就点个赞吧
0 人点赞
