学习资源:狂神 https://www.bilibili.com/video/BV1dX4y1V73G?p=28&spm_id_from=pageDriver
RabbitMQ
RabbitMQ支持的消息发送的模式
Simple简单模式、Work工作模式、fanout发布订阅模式、direct路由模式、主题Topic模式
1、Simple简单模式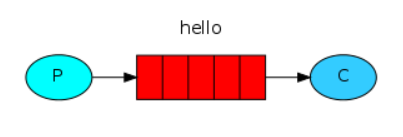
2、工作模式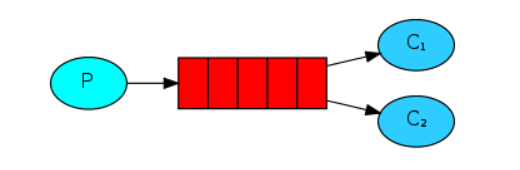
工作模式中公平分发和轮询分发都是我们经常使用的模式。
公平分发需要消费者开启手动应答,关闭自动应答
3、发布订阅模式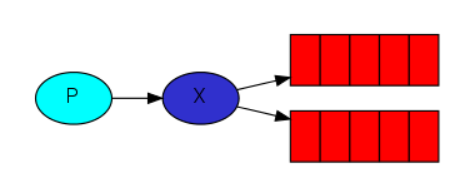
4、路由模式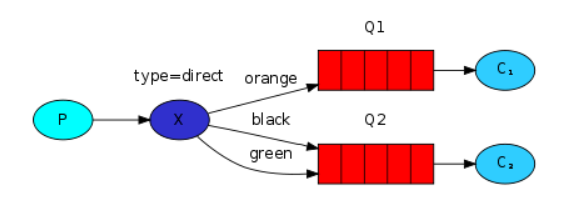
5、主题Topic模式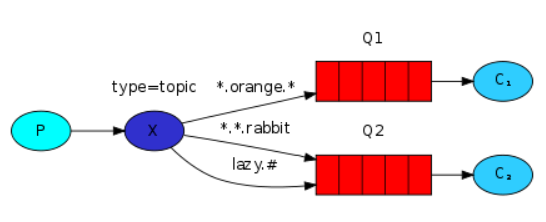
为什么使用消息队列?
消息队列使用的场景有 解耦、异步、削峰
解耦:
如果有个场景,A系统需要发送数据到BCD三个系统,通过接口调用发送,但是如果碰到业务修改的问题,如果E系统也需要调用数据,如果B系统突然又不需要了,那么对于A系统的业务逻辑的修改无疑是比较复杂的。
而且A系统与各种系统耦合在一起,要时刻考虑发送给他们的消息,如果消息发送失败该怎么办;如果其他系统挂了该怎么办
如果使用MQ解耦,那么A系统产生一条数据,发送到MQ里面去,如果某个系统需要数据,则去MQ中消费即可。如果新系统不需要消费了,就取消对MQ的消费;A系统不需要考虑给谁发送数据。
异步:
如果不使用MQ,如果这个请求不仅需要在A系统写入数据,还要在BCD系统写入数据,那么接口请求的延时就会很慢
如果使用MQ,那么A系统只需要在自己地方写入数据,并把消息发送到MQ中,就可以直接返回了,请求的延时会很快
削峰:
消息队列的优缺点
缺点:
系统可用性降低:系统结构复杂,如果MQ挂掉,则会导致整个系统都崩溃。所以需要保证消息队列的高可用性
如何保证消息队列的高可用性?
比如RabbitMQ,有单机模式、集群模式、镜像集群模式(高可用)
其中镜像集群是高可用的
镜像集群中,创建的queue队列,无论是元数据还是queue队列里面的消息,都会存在于多个实例上,每个RabbitMQ节点都有这个queue的一个完整的镜像,包括queue的全部数据。每次写消息的时候,都会自动把消息同步到多个实例的queue上。
这样一个机器宕机后,消费者还可以去其他机器消费。缺点是性能开销大,使得网络带宽压力和消耗很重
再拿kafka举例:系统复杂度提高
消费者有可能出现重复消费的情况,需要处理消息丢失,保证消息传递的顺序性等等
如何保证消息的重复消费(如何保证幂等性),和消息的顺序性?
重复消费可能出现的场景:如kafka
kafka有个offset的概念,就是每个消息写进去都有一个消息序号,然后定期把自己消费过的消息的offset提交一下,表明已经消费过。
但是如果碰到消费者系统重启,消费者还没来得及把消费的序号提交给zookeeper时,那么就会造成启动后,碰到重复的消息过来。
遇到重复消费不可怕,但是最重要的是考虑怎么保证幂等性?
幂等性就是一个数据或一个请求,重复多次,我们最终的结果是不变的。
这个解决的思路可以结合具体的业务逻辑:- 如果数据库存在这个主键,那么把插入操作变为更新操作
- 如果写redis,那么就没问题,每次set数据都一样,就是幂等的
- 如果场景复杂一点,可以将已经处理过的消息的id存入redis,每次处理时就可以判断消息是否已经被处理过
- 基于数据库唯一键保证重复数据只会插入一条
如何处理消息的丢失?
数据丢失的问题,可能出现在生产者、MQ、消费者中
如果针对生产者可能丢失消息的情况,有两种解决办法:
1.开启RabbitMQ的事务,如果在发送消息中生产者捕获到异常那么,就回滚事务,然后尝试重发消息
2.设置RabbitMQ的confirm机制,就是说,如果每次写入的消息会有一个唯一的id,然后如果消息成功写入MQ,则MQ会回传一个ACK消息,如果失败,则会回调一个nack接口。
两者的区别是,事务机制是同步的,confirm机制是异步的
如果针对MQ丢失消息的情况
可以设置MQ持久化磁盘上,RabbitMQ哪怕挂了,也会恢复之后自动读取之前存储的数据。
针对消费者弄丢了数据
关闭RabbitMQ的自动ACK,使用手动ACK的方式确认
- 一致性问题
如果自己设计一个消息中间件,你会怎么设计?
- 生产者、消费者模型
- 支持分布式架构
- 数据的高可用
- 消息数据不丢失

若有收获,就点个赞吧
0 人点赞
