概述
RDD
弹性分布式数据集,是Spark一个重要的抽象概念,具备容错机制的特殊集合,分布在集群节点上,以函数式操作集合的方式进行各种并行操作。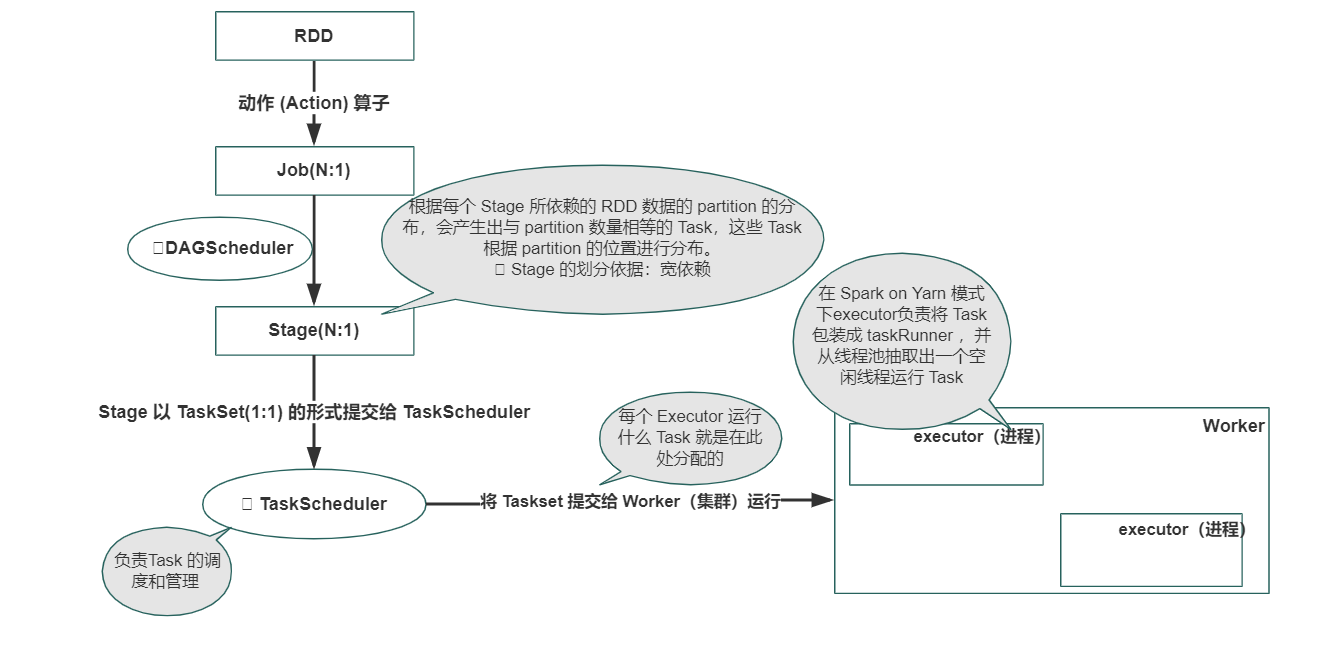
- DAG:即Directed Acyclic Graph,有向无环图。
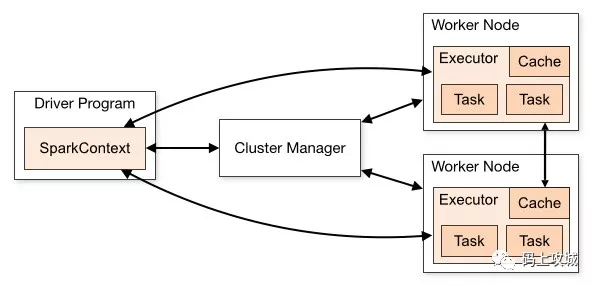
- Application:Application是用户编写的 Spark 应用程序,其中包含了一个Driver 功能的代码和分布在集群中多个节点上运行的 Executor 代码。
- Driver:使用Driver 这一概念的分布式框架很多,比如 Hive 等。 Spark 中的 Driver 即运行Application 的 main() 函数并创建SparkContext,创建 SparkContext 的目的是为了准备 Spark 应用程序的运行环境。在 Spark 中由 SparkContext 负责与ClusterManager 通信,进行资源的申请、任务的分配和监控等。当Executor 部分运行完毕后,Driver 同时负责将SparkContext 关闭。通常用 SparkContext 代表 Driver。
- Executor:某个 Application 运行在 Worker 节点上的一个进程,该进程负责运行某些 Task,并且负责将数据存在内存或者磁盘上,每个 Application 都有各自独立的一批 Executor。 在 Spark on Yarn 模式下它负责将 Task 包装成 taskRunner ,并从线程池抽取出一个空闲线程运行 Task。
- Task:被送到某个 Executor 上的工作单元,和 Hadoop MapReduce 中的 MapTask 和 ReduceTask 概念一样,是运行Application 的基本单元,代表单个数据分区上的最小处理单元。Task 分为 ShuffleMapTask 和 ResultTask 两类。ShuffleMapTask 执行任务并把任务的输出划分到 (基于 task 的对应的数据分区) 多个bucket(ArrayBuffer) 中,ResultTask 执行任务并把任务的输出发送给驱动程序。多个 Task 组成一个 Stage,而Task 的调度和管理等由下面的 TaskScheduler 负责。
- TaskSet:代表一组相关联的没有 shuffle 依赖关系的任务组成任务集。一组任务会被一起提交到更加底层的TaskScheduler 进行管理。
- Stage:Job 被确定后,Spark 的调度器 (DAGScheduler) 会根据该计算作业的计算步骤把作业划分成一个或者多个 Stage。Stage 又分为ShuffleMapStage 和 ResultStage,每一个 Stage 将包含一个 TaskSet。
- Job:Spark的计算操作是 lazy 执行的,只有当碰到一个动作(Action) 算子时才会触发真正的计算。一个 Job 就是由动作算子而产生包含一个或多个 Stage 的计算作业。
- RDD :Spark的基本计算单元,可以通过一系列算子进行操作(主要有 Transformation 和 Action 操作)的弹性分布式集合(Resilient Distributed Datasets)简称,是分布式只读且已分区集合对象。RDD 是 Spark 最核心的东西,它表示已被分区、被序列化的、不可变的、有容错机制的,并且能够被并行操作的数据集合。其存储级别可以是内存,也可以是磁盘,可通过spark.storage.StorageLevel属性配置。
- DAGScheduler:根据Job 构建基于 Stage 的 DAG,并提交 Stage 给 TaskScheduler。其划分 Stage 的依据是 RDD 之间的依赖关系,根据 RDD 和 Stage 之间的关系找出开销最小的调度方法,然后把 Stage 以 TaskSet 的形式提交给 TaskScheduler。此外,DAGScheduler 还处理由于 Shuffle 数据丢失导致的失败,这有可能需要重新提交运行之前的 Stage(非 Shuffle 数据丢失导致的 Task 失败由 TaskScheduler 处理)。
- TaskScheduler:将Taskset 提交给 Worker(集群)运行,每个Executor 运行什么 Task 就是在此处分配的。TaskScheduler还维护着所有 Task 的运行状态,重试失败的 Task。
- 宽依赖:与Hadoop MapReduce 中 Shuffle 的数据依赖相同,宽依赖需要计算好所有父 RDD 对应分区的数据,然后在节点之间进行 Shuffle。
- 窄依赖:指某个具体的 RDD,其分区 partitoin a 最多被子 RDD 中的一个分区 partitoin b 依赖。此种情况只有 Map 任务,是不需要发生 Shuffle 过程的。
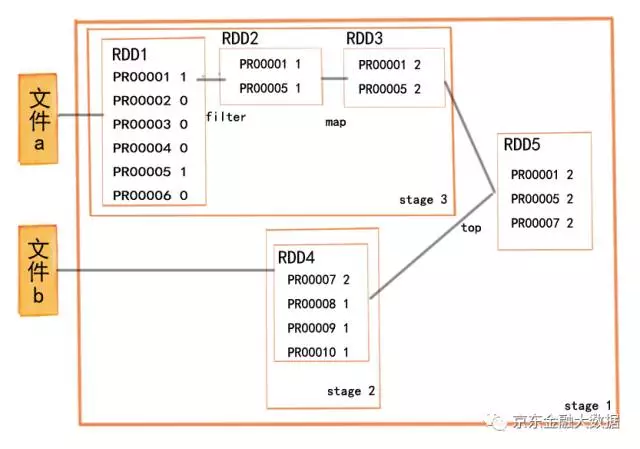
- Stage 的划分依据:是以 ShuffleDependency 为依据的,也就是说当某个 RDD 的运算需要将数据进行 Shuffle 时,这个包含了 Shuffle 依赖关系的 RDD 将被用来作为输入信息,进而构建一个新的 Stage。我们可以看到用这样的方式划分 Stage,能够保证有依赖关系的数据可以以正确的顺序执行。根据每个 Stage 所依赖的 RDD 数据的 partition 的分布,会产生出与 partition 数量相等的 Task,这些 Task 根据 partition 的位置进行分布。
算子
- 是否触发job的角度划分:
- Transform:map、flatmap、filter、distinct、union、groupBy、partionBy、union
- Action:count、reduce、foreach、top
- 是否触发stage的角度划分:
- 宽依赖(产生shuffle):groupByKey、reduceByKey、sortByKey
- 窄依赖:filter、map、union
groupByKey、reduceByKey、sortByKey区别:
sortBykey功能和另外两个不一样,只是根据key进行排序。reduceByKey在merge之前,支持本地的combine(预聚合),可以减少网络传输,并且本地merge操作支持函数自定义。相比之下,groupByKey不支持本地merge优化且不支持自定义函数,在大数据量情况下,效率比较低
flatmap

若有收获,就点个赞吧
0 人点赞
