Hbase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库
简介
稀疏存储特性(有的列簇列是空的,则不占存储空间,没有默认值)
逻辑结构映射的物理结构: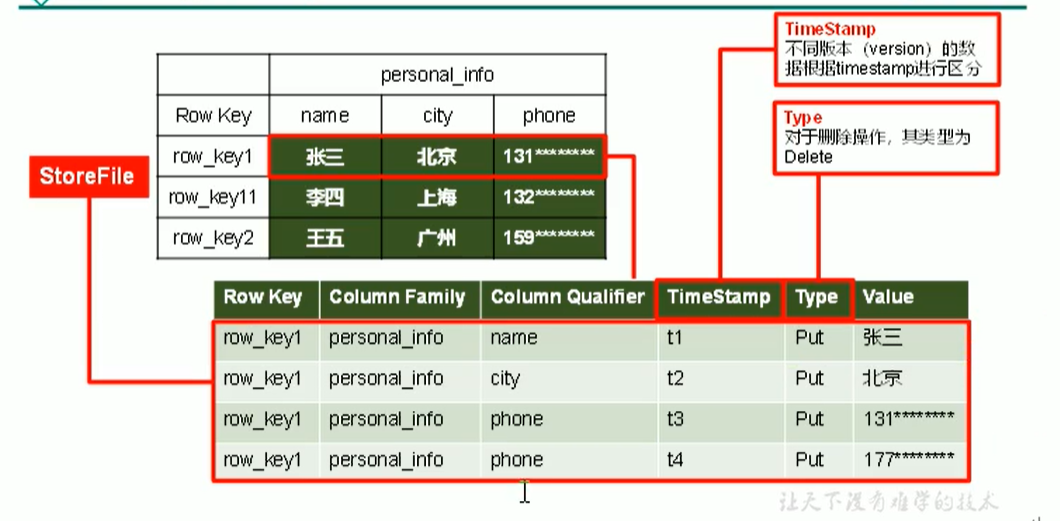
Hbase详细架构图: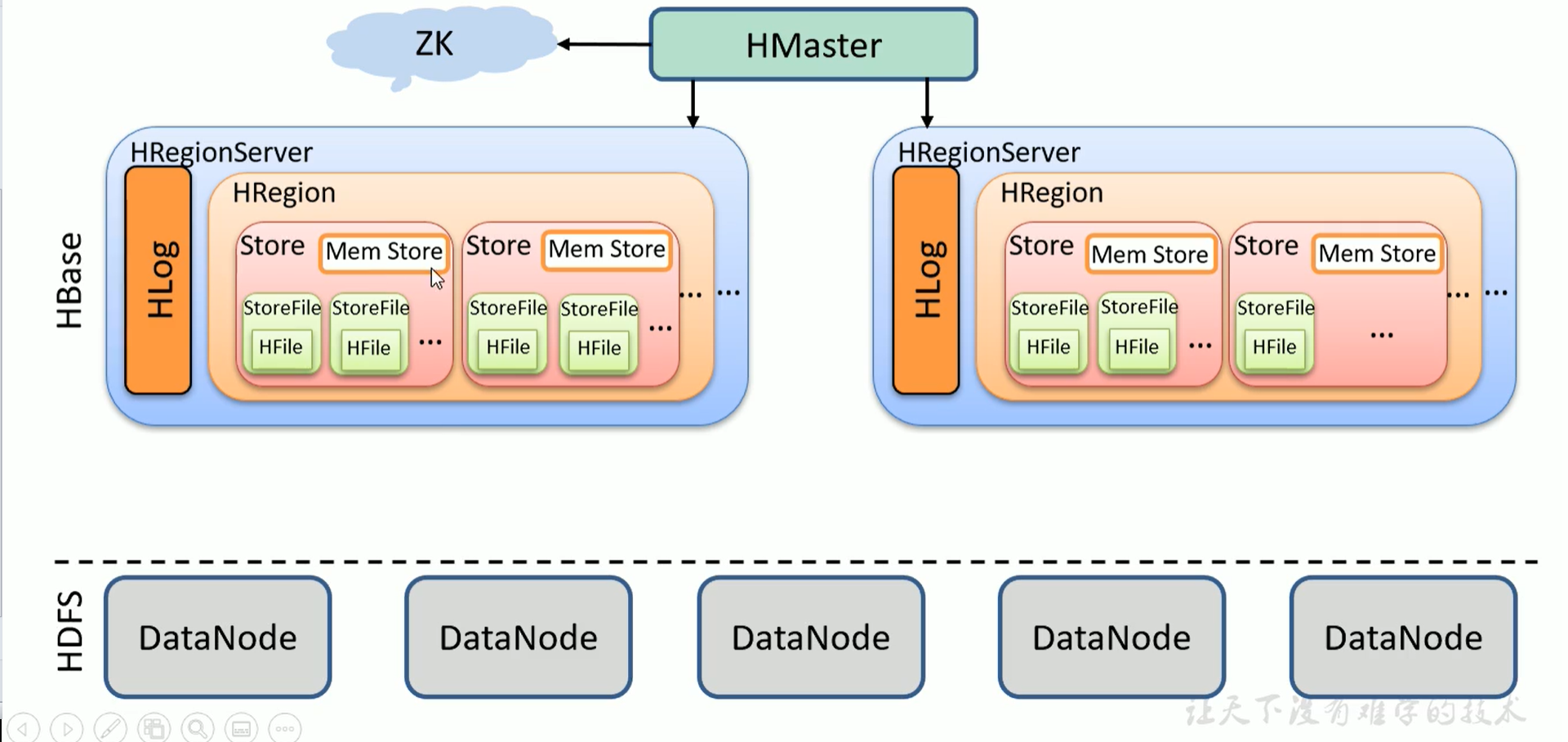
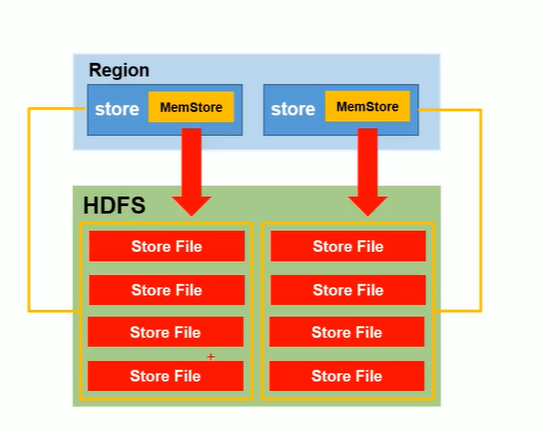
同一个region中,Store和列簇是一一对应的。StoreFile的实际位置其实是在DataNode(即HDFS中),所以mem store flush的时候,flush到Store File也就是HDFS中。HFile是文件格式(与.txt这种同级)。每次Mem Store刷写一次产生一个StoreFile。
详细流程
Hbase写流程
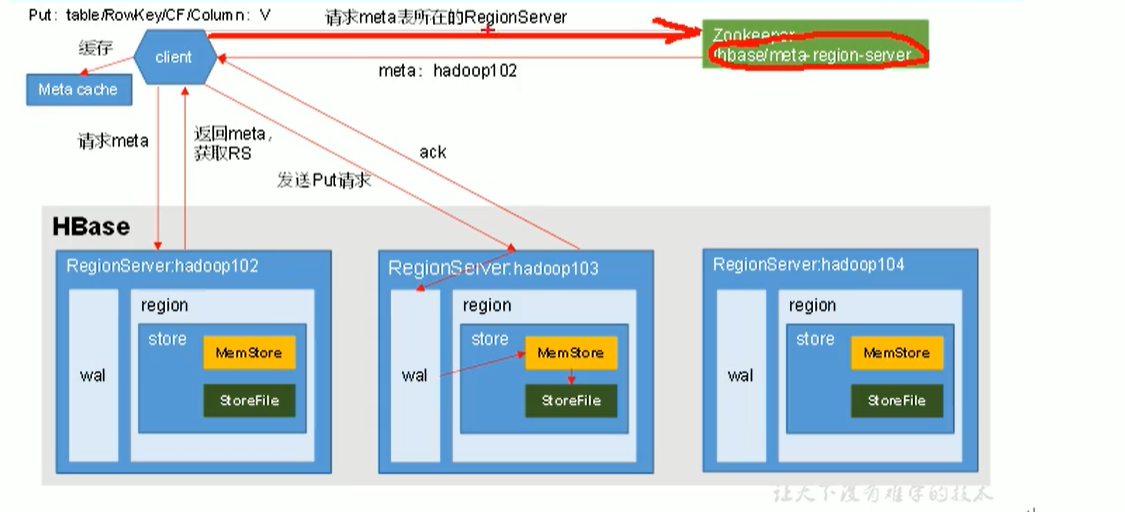

meta表里是一个region一条数据,而不是一张表一条数据,因为一张表可以被切分成多个region。
MemStore Flush
MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是一个HRegion的一个Column Family对应一个实例。它的排列顺序以RowKey、Column Family、Column的顺序以及Timestamp的倒序,如下所示: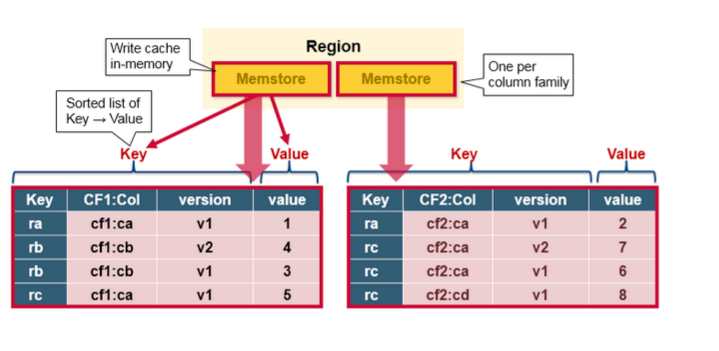
Mem Store刷写时机:
- 全局Regionserver.memstore.size > region启动的最大内存的x(默认40)%,则阻塞写方式flush。
- 全局Regionserver.memstore.size.lower.limit > region启动的最大内存的x默认(38)%,则非阻塞写方式flush。
- Regionserver.optionalcacheflushinterval为0则关闭自动刷新,最后一条数据到x(默认1小时)的时间段内都没有触发写入,则flush。即最后一次编辑时间。
- Region.memstore.flush.size >= 128M,则会刷写,注意,此处是region级别,不是RS级别,并且仅刷写当前region。
- Regionserver.max.logs,新版本已不暴露给用户的配置。当WAL文件数量超过x(默认32),region会按照时间顺序一次进行耍写,直到WAL文件数量减小到x以下。
- Regionserver.hlog.blocksize。hlog大小上线,默认为hdfs配置的block大小。
Hbase读流程
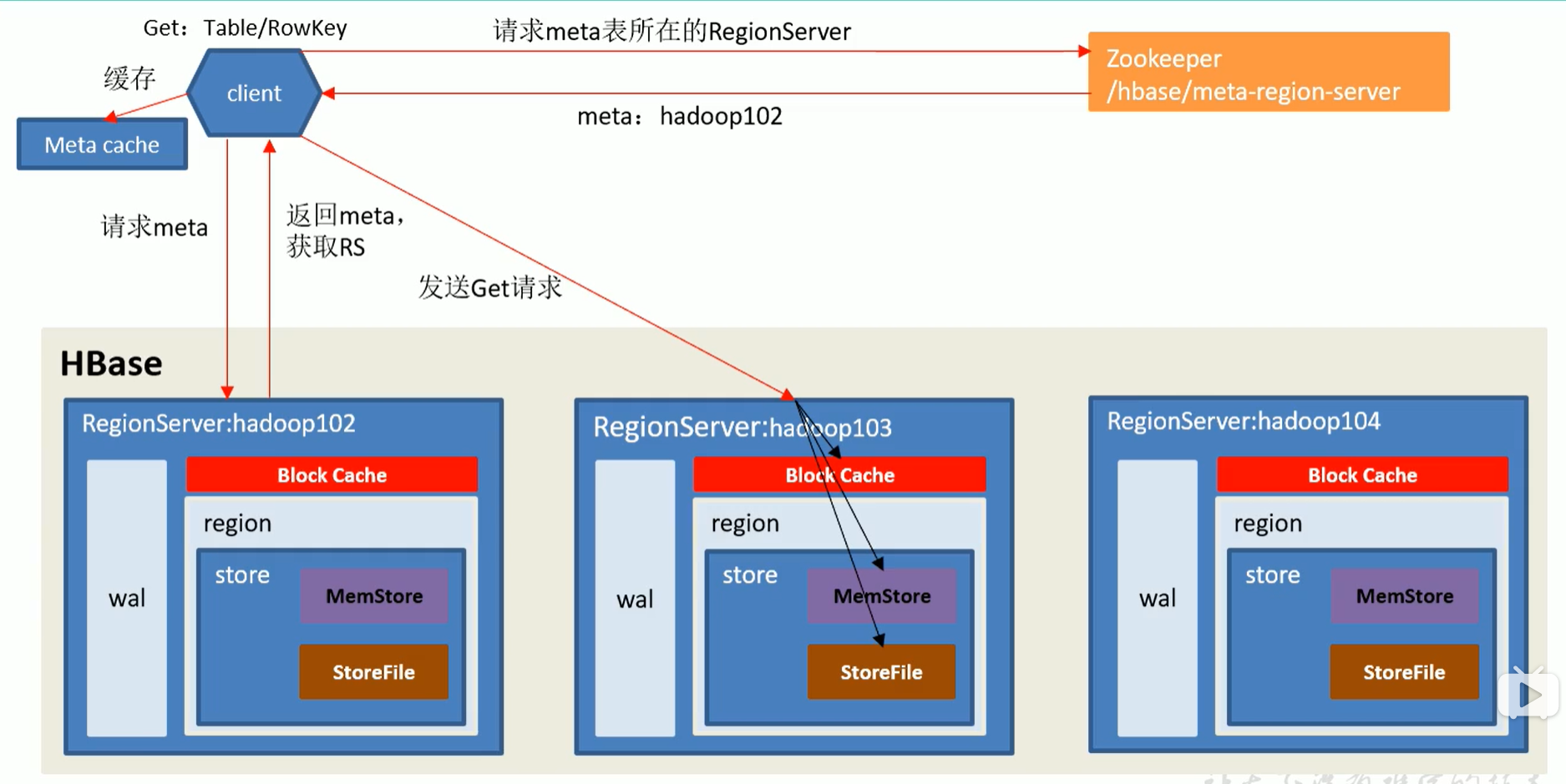
- 前面几步骤和写流程一致,找到需要操作的RS的region
- 在请求对应的RS时候,请求Block Cache数据,如果缓存中不存在对应的region块数据,则请求Store File然后再将StoreFile中的数据缓存回Block Cache。再请求MemStrore中的数据,与MemStore中的数据进行Merge,根据时间戳排序取出最新数据。
PS:之所以要Merge,是因为memStore中可能存在最新录入的数据,没有flush到store file中。之所以是merge而不是以memStore为最新数据为标准,是因为后写的数据如果指定的时间戳比storeFile中还要早,那么根据hbase的规则,是以时间戳大的数据为准的。
StoreFile Compact流程
Compact分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。Major Compaction会将一个Store下的所有HFile合并成一个大HFile,并会清理掉过期和删除的数据。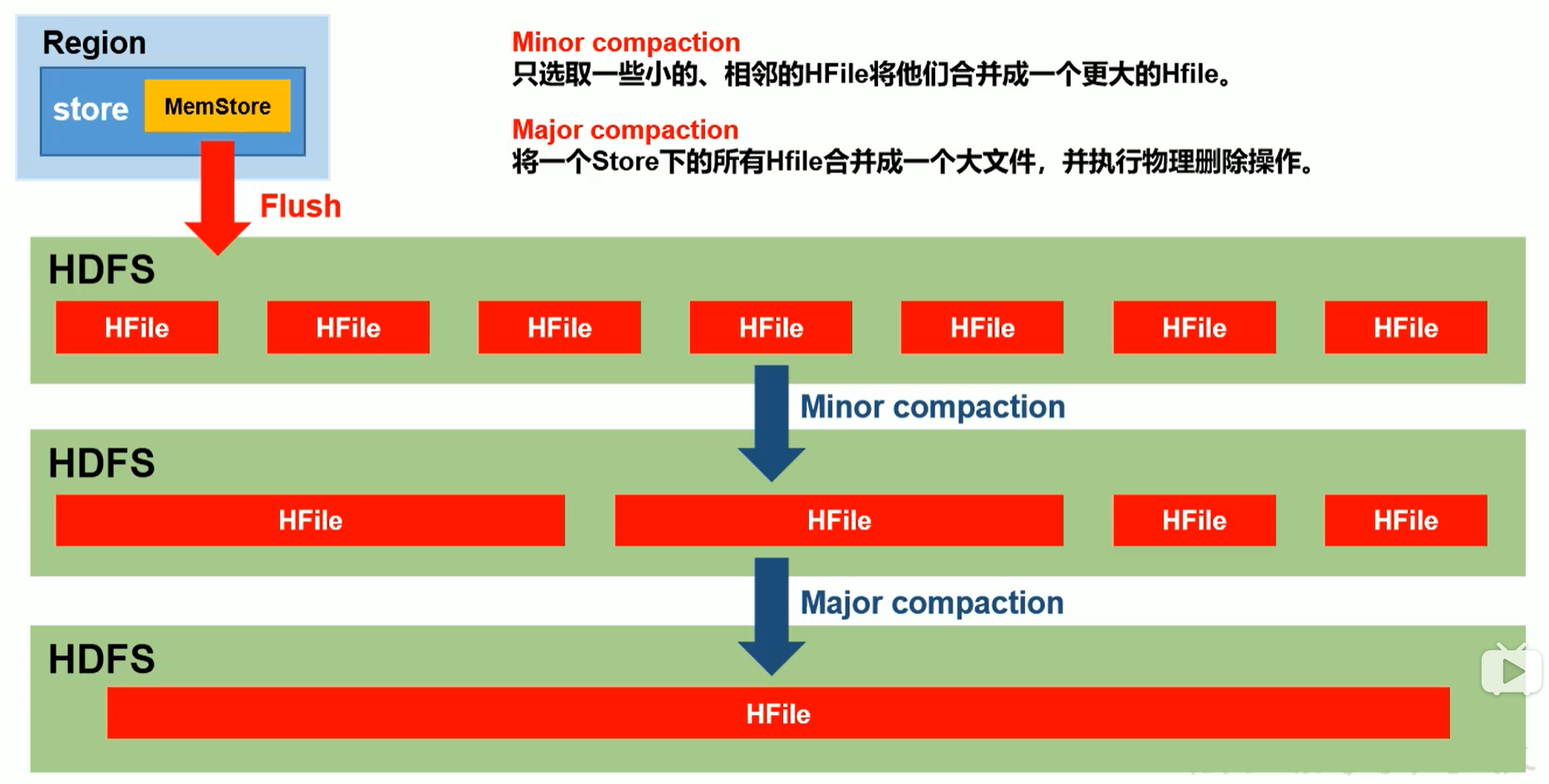
- Hregion.majorcompaction,合并的周期,默认是7天。Major compaction非常消耗资源,建议生产关闭(设置为0),在应用空闲时手动触发。
- Hstore.conpactionThreadhold,一个store里面允许存在的hfile的个数,超过这个数会被写到新的hfile里面。默认情况时3个hflie的时候就会对这些文件进行合并重写为一个新文件,设置个数越大,触发合并越少,但每次合并的时间就越长。(触发自动合并需要点时间,不是立刻触发)
Hbase读写流程-扩展
- 整个数据的读写流程都与HMaster无关。
- 在写客户端连接时,只需要写zk的地址即可,不需要写HMaster的ip端口。因为master还是注册在zk上,并且是高可用有备份的。直连master就不再高可用了。
- 但HMaster长期宕机集群是不健康的,因为当RS做Region切分的时候,新生成的region可能会调度到其他节点,这时候需要HMaster改meta元数据做region记录维护,并且还需要HMaster将这些数据调度到其他节点。
数据真正删除时间
- Flush
- 在同个memstore,同个内存内会删除
- 跨越多个文件时候,无法删除。flush只是操作内存,硬盘存在过期/覆盖数据都是看不到的。
- major compation
Region Split
hregion.max.filesize,HFile最大的大小,默认10G。当某个region的某个列簇超过这个大小会进行region拆分(0.94版本前)。新版本是当某个region中的某个store下所有storeFile的总大小超过Min(R^2*”hregion.memstore.flush.size”,”hbase.max.filesize”)。
注意:当rowkey设计不合理,会存在数据倾斜的问题。解决:预分区
官方建议定义一个列簇,原因:如果大量数据都在cf1中,cf2、cf3只有一点,切分后,如果触发全局flush,cf2、cf3都会形成小文件,形成大量小文件。生产环境中可以使用多列簇,但要控制下,尽量保证每个列簇的数据量差不多,不要差异太大。
Hbase与Hive对比
Hive是一个分析框架,Hbase是一个存储框架。为什么这么说,他们不都是依托于HDFS吗?但有个实质区别是在于Hive的元数据是依托于mysql,Hbase是自己管理的元数据。

Hbase优化
高可用
预分区


预分区规划因素:未来发展的数据量和机器规模。一般是1台机器对应2-3个region。分区一般10个以上,防止系统自己分区。数据量一般按半年-一年的数据量。
- 数据量扩展特别大,则建新表导入
- 数据量发展不多,则可以只分某个region。可能其他region只有1G,数据倾斜了。
rowkey设计
设计原则:
- 散列性
- 生成随机数、hash、散列值
- 字符串反转
- 字符串拼接
- 唯一性、
- 长序原则(70-100位)
- 这个长度适合扩展分区
设计时候既要保证散列,也要保证集中。比如通话记录,散列到各个分区,集中是最好把同个号码放在同个分区中,但这样可能会产生数据倾斜,所以在集中的基础的上又要散列,我们可以按号码+月/mod后进行散列集中的中庸。
内存优化
Hbase操作过程需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给Hbase的java堆。但是不建议分配非常大的堆内存,因为GC过程持续时间会非常久(flush时间过长),会导致RS长期不可用状态,一般16-48G内存久可以了。如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务托死。另外如果内存设置过大,memstore 在 x0.40.95 到x*0.4 之间阻塞写,x越大,阻塞时间也越长。
基础优化

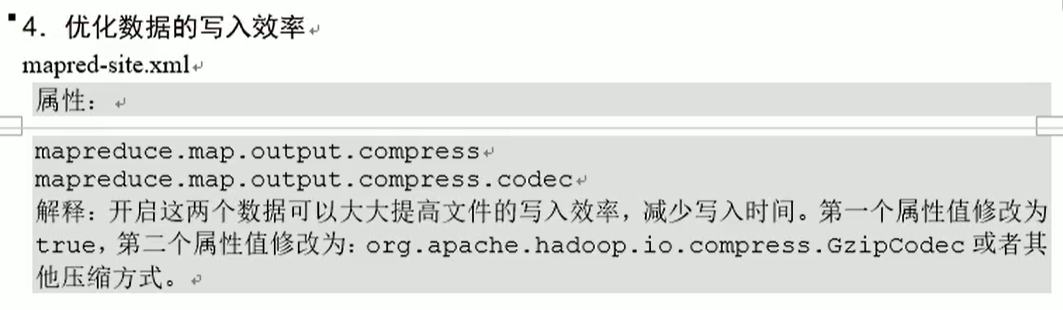




场景应用
适合点查或者批量带特征的数据,比如从海量数据中获取某个用户的所有微博,rowkey设计为uidts,直接过滤uid*。
doc文档

若有收获,就点个赞吧
0 人点赞
