数据类型
基本数据类型
整型
TINYINT (1字节整数)
SMALLINT (2字节整数)
INT/INTEGER (4字节整数)
BIGINT (8字节整数)
浮点型
FLOAT (4字节浮点数)
DOUBLE (8字节双精度浮点数)
时间类型
- TIMESTAMP (时间戳) (包含年月日时分秒的一种封装)
- DATE (日期)(只包含年月日)
字符串类型
- STRING (不设定长度)
- VARCHAR (字符串1-65355长度,超长截断)
- CHAR (字符串,最大长度255)
其他类型
- BOOLEAN(布尔类型):true false
- BINARY (二进制)
集合数据类型
| HIVE数据类型 | 描述 |
|---|---|
| ARRAY |
| 数组是一组具有相同类型和名称的变量的集合。这些变量称位数组的元素,每个数组元素都有一个编号,编号从零开始。 | | MAP | Map是一组键值对元祖集合,使用数组表示法可以访问数据 | | STRUCT | 和C语言的struct类似,都可以通过“点”符号访问元素内容 |
DDL
CREATE TABLE employees (name STRING,salary FLOAT,subordinates ARRAY<STRING>,deductions MAP<STRING, FLOAT>,address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>) PARTITIONED BY (country STRING, state STRING);ROW FORMAT DELIMITEDFIELDS TEMINATED BY '\001'COLLECTION ITEMS TERMINATED BY '\002'MAP KEYS TEMINATED BY '\003'LINES TERMINATED BY '\n'SORTED BY TEXTFILE;--如果想要查询里面的数据,可以用下面的SQLselect name, salary, subordinates[0], deductions['key'], address.cityfrom employees;
分区表
级联 cascade
分区字段更新注意点,要加上cascade
1. cascade的中文翻译为“级联”,也就是不仅变更新分区的表结构(metadata),同时也变更旧分区的表结构。
2. 对于删除操作也是,级联删除表中的信息,当表A中的字段引用了表B中的字段时,一旦删除B中该字段的信息,表A的信息也自动删除。(当父表的信息删除,子表的信息也自动删除)
3. 在我们执行更改字段类型、增加字段时,在语句末尾加上cascade就ok了,要不然很麻烦
alter table table_name change column 字段 字段 bigint cascade;
参考 https://blog.csdn.net/m0_48283915/article/details/113318482
分区字段
// 1. 创建分区表
CREATE TABLE stag_tmp.test_employees (
name STRING,
salary FLOAT,
age bigint,
sex String
) PARTITIONED BY (country STRING, state STRING);
// 2. 删除分区表
drop table stag_tmp.test_employees;
// 3. 插入数据
insert into stag_tmp.test_employees partition (country='china', state='1') values('aaa', 123.12, 12, 'male')
// 4. 查询数据
select * from stag_tmp.test_employees
// 5. 删除字段(目前执行会报错,网上语法如下)
ALTER table stag_tmp.test_employees replace COLUMNS (
name STRING,
salary FLOAT,
sex String
) PARTITIONED BY (country STRING, state STRING);
DML
insert into直接追加到表中数据的尾部
insert overwrite会重写数据,即先进行删除,再写入
//手动插入:
INSERT into test_partition partition(day='20200204') values(56, 'kky');
//查询插入:
INSERT into test_partition partition(day='20200202') SELECT id, name from test;
//查询插入:
INSERT overwrite table test_partition partition(day='20200202') SELECT id, name from test;
函数
排序
全局排序
全局排序,只有一个Reducer
Order by 默认为一个reducer,手动设置也没有效果,它只在一个reduce中进行所以数据量特别大的时候效率非常低。
分区排序
类似MR中partition,进行分区,结合sort by使用。
注意,Hive要求Distribute by语句要写在sort by 语句之前。
sort by和cluster by
sort by 是单独在各自的reduce中进行排序,所以并不能保证全局有序,一般和distribute by 一起执行,而且distribute by 要写在sort by前面
distribute by 和 sort by 合用就相当于cluster by,但是cluster by 不能指定排序为asc或 desc 的规则,只能是升序排列。
分桶
使用场景
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式,分桶是将数据集分解为更容易管理的若干部分的另一种技术。
原理
跟MR中的HashPartitioner的原理一模一样,MR中:按照key的hash值去模除以reductTask的个数。Hive中:按照分桶字段的hash值去模除以分桶的个数。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
窗口函数
over()函数
查询2017.4购买过的顾客和总人数,比如返回 neil|2,mart|2
类似sql: select name, count(distinct(name)) from table 但语法不会通过
select name, count(*) over() from table group by name
查询顾客的购买明细及月购买总额,实现如下图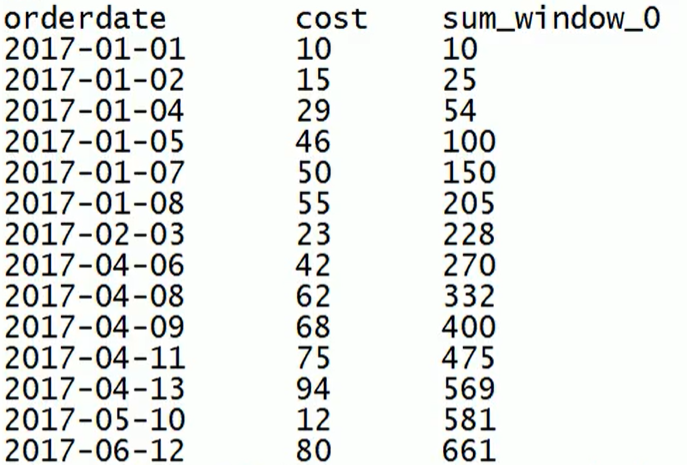
//给每条数据都开了独立的窗口,第一条数据看不到后面的数据,所以sum的时候只有自己的cost.
Select order_date, cost, sum(cost) over(order by order_date) from table
查询顾客的购买明细及按人聚合的总消费数,实现如下图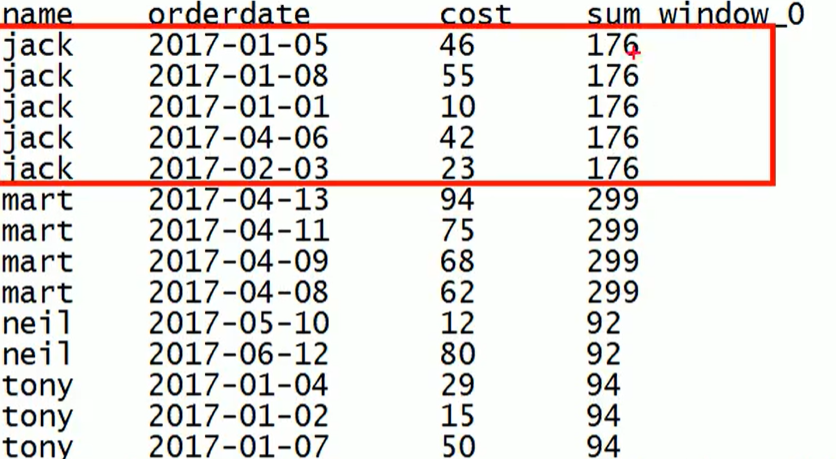
Select name, orderdate, cost, sum(cost) over(disturbe by name) from table
rank()函数
RANK()
排序相同时会重复,总数不会变
DENSE_RANK()
排序相同时会重复,总数会减少
ROW_NUMBER()
会根据顺序计算,应用场景分组排序取各自的第1(/N)条
select t.id, t.name, t.time_c
from (
select id,
name,
time_c,
row_number() over(partition by id order by time_c desc) rank
from table_name
) t
where t.rank = 1

若有收获,就点个赞吧
0 人点赞
