Why Fink
流数据存在广泛的应用场景,传统数据架构是基于有限数据集的,而我们的目标是低延迟、高吞吐、结果具备准确性、服务具备良好的容错性
流处理的演变
Storm
Storm基于内存能实现低延迟的目标,但是扩展性受限无法实现高吞吐、结果准确性。
Spark Streaming
Spark Streaming 虽然保证了高吞吐和结果准确性,但是实际上是”微批”处理,低延迟方面无法和真正的流式处理相比,另外无法支持丰富的时间语义和处理乱序数据
Flink
集成了低延迟、高吞吐、结果正确、时间正确/语义化窗口、
特性
- Flink是基于事件驱动的(类似于web服务),比如Flume收集日志信息到Kafka,Flink基于从Kafka获取的数据进行计算产出结果。
- Flink认为一切都是由流组成的,离线数据是有边界的流(有开始结束时间段),而实时数据是一个没有界限的流(此时此刻一直在进行)。而Flink的有界流处理效果就相当于我们之前的离线批处理,和Spark刚好相反,Spark是将一切都转为批,如Spark Streaming的”微批”操作实现实时处理。
- 精确一次(Exactly-once)的状态一致性保证
- 低延迟,每秒处理百万个事件,毫秒级延迟
- 高可用,动态扩展
Flink VS Spark Streming
数据模型
Spark采用RDD模型,Spark Streaming的DStreaming实际上也就是一组组小批数据的RDD集合
Fink基本数据模型是数据流,以及事件(Event)序列
运行时架构
Spark是批处理,将DAG划分为不同的stage,一个计算完后才能计算下一个
Flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
分层API
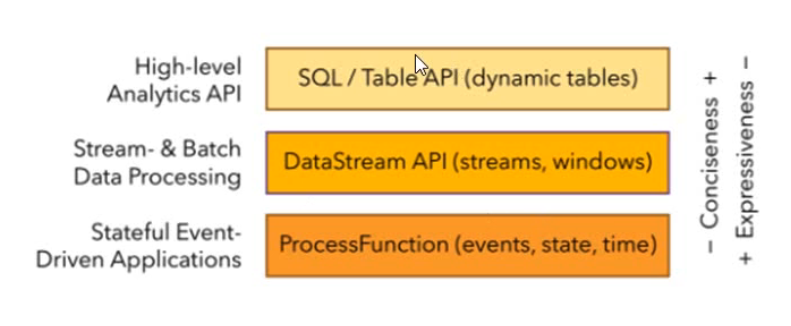
- SQL/Table API(dynamic tables)
- 顶层的是Flink SQL,使用方便、语义简洁
- DataStream API(streams、windows)
- 使用最为频繁的一层,折中了使用方便和功能丰富程度
- ProcessFunction(event、state、time)
- 最底层的API,功能丰富灵活,使用难度大

若有收获,就点个赞吧
0 人点赞
