Spark中JOIN执行的5种策略【1】
Spark提供了5种JOIN机制来执行具体的JOIN操作。该5种JOIN机制如下所示:
- Shuffle Hash Join
- Broadcast Hash Join
- Sort Merge Join
- Cartesian Join
- Broadcast Nested Loop Join
Shuffle Hash Join【2】
简介
当要JOIN的表数据量比较大时,可以选择Shuffle Hash Join。这样可以将大表进行按照JOIN的key进行重分区,保证每个相同的JOIN key都发送到同一个分区中。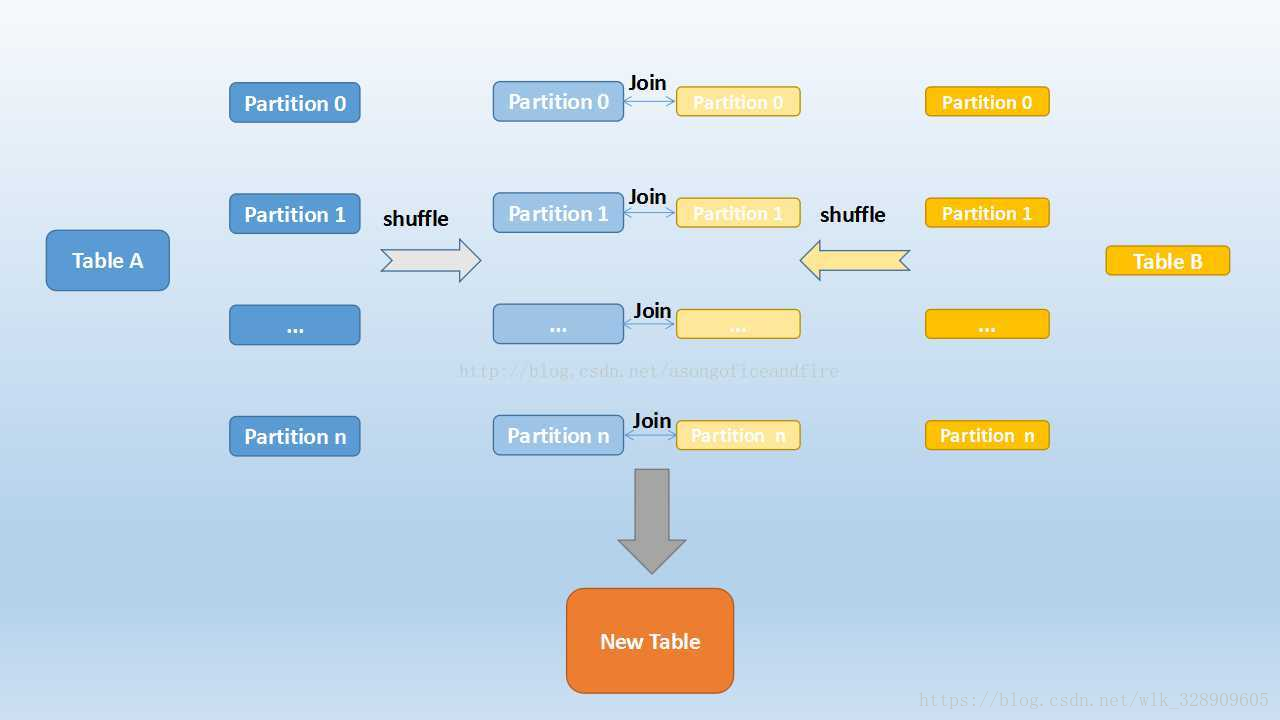
Shuffle Hash Join的基本步骤主要有以下两点:
- 首先,对于两张参与JOIN的表,分别按照join key进行重分区,该过程会涉及Shuffle,其目的是将相同join key的数据发送到同一个分区,方便分区内进行join。
其次,对于每个Shuffle之后的分区,会将小表的分区数据构建成一个Hash table,然后根据join key与大表的分区数据记录进行匹配。
条件与特点
仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型
- 需要对小表构建Hash map,属于内存密集型的操作,如果构建Hash表的一侧数据比较大,可能会造成OOM
将参数spark.sql.join.prefersortmergeJoin (default true)置为false
Broadcast Hash Join
简介
也称之为Map端JOIN。当有一张表较小时,我们通常选择Broadcast Hash Join,这样可以避免Shuffle带来的开销,从而提高性能。比如事实表与维表进行JOIN时,由于维表的数据通常会很小,所以可以使用Broadcast Hash Join将维表进行Broadcast。这样可以避免数据的Shuffle(在Spark中Shuffle操作是很耗时的),从而提高JOIN的效率。在进行 Broadcast Join 之前,Spark 需要把处于 Executor 端的数据先发送到 Driver 端,然后 Driver 端再把数据广播到 Executor 端。如果我们需要广播的数据比较多,会造成 Driver 端出现 OOM。具体如下图示:
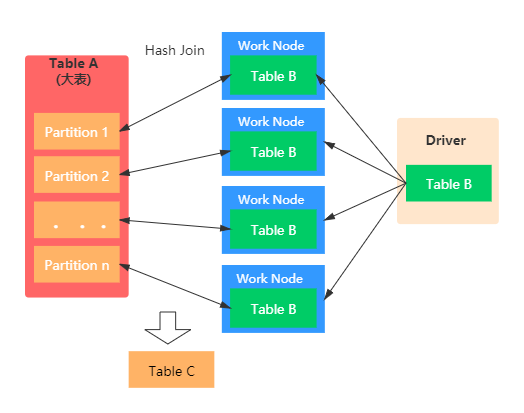
条件与特点
仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型
- Broadcast Hash Join相比其他的JOIN机制而言,效率更高。但是,Broadcast Hash Join属于网络密集型的操作(数据冗余传输),除此之外,需要在Driver端缓存数据,所以当小表的数据量较大时,会出现OOM的情况
- 被广播的小表的数据量要小于spark.sql.autoBroadcastJoinThreshold值,默认是10MB(10485760)
- 被广播表的大小阈值不能超过8GB
Sort Merge Join
简介
该JOIN机制是Spark默认的,可以通过参数**spark.sql.join.preferSortMergeJoin**进行配置,默认是true,即优先使用Sort Merge Join。一般在两张大表进行JOIN时,使用该方式。Sort Merge Join可以减少集群中的数据传输,该方式不会先加载所有数据的到内存,然后进行hashjoin,但是在JOIN之前需要对join key进行排序。具体图示: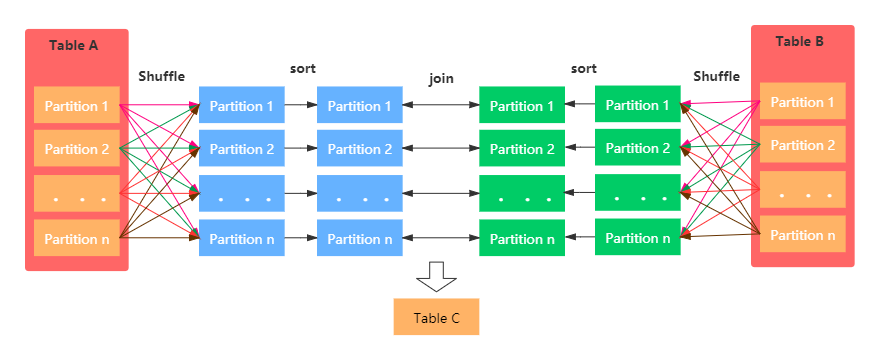
Sort Merge Join主要包括三个阶段:
- Shuffle Phase : 两张大表根据Join key进行Shuffle重分区
- Sort Phase: 每个分区内的数据进行排序
Merge Phase: 对来自不同表的排序好的分区数据进行JOIN,通过遍历元素,连接具有相同Join key值的行来合并数据集
条件与特点
仅支持等值连接
- 支持所有join类型
-
Cartesian Join
简介
如果 Spark 中两张参与 Join 的表没指定join key(ON 条件)那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张行数的乘积。
条件
仅支持内连接
- 支持等值和不等值连接
- 开启参数spark.sql.crossJoin.enabled=true
Broadcast Nested Loop Join
该方式是在没有合适的JOIN机制可供选择时,最终会选择该种join策略。优先级为:Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > cartesian Join > Broadcast Nested Loop Join.
在Cartesian 与Broadcast Nested Loop Join之间,如果是内连接,或者非等值连接,则优先选择Broadcast Nested Loop策略,当时非等值连接并且一张表可以被广播时,会选择Cartesian Join。
条件与特点
- 支持等值和非等值连接
- 支持所有的JOIN类型,主要优化点如下:
- 当右外连接时要广播左表
- 当左外连接时要广播右表
- 当内连接时,要广播左右两张表
Spark是如何选择JOIN策略的
等值连接的情况
有join提示(hints)的情况,按照下面的顺序
- Broadcast Hint:如果join类型支持,则选择broadcast hash join
- Sort merge hint:如果join key是排序的,则选择 sort-merge join
- shuffle hash hint:如果join类型支持, 选择 shuffle hash join
shuffle replicate NL hint: 如果是内连接,选择笛卡尔积方式
没有join提示(hints)的情况,则逐个对照下面的规则
如果join类型支持,并且其中一张表能够被广播(spark.sql.autoBroadcastJoinThreshold值,默认是10MB),则选择 broadcast hash join
- 如果参数spark.sql.join.preferSortMergeJoin设定为false,且一张表足够小(可以构建一个hash map) ,则选择shuffle hash join
- 如果join keys 是排序的,则选择sort-merge join
- 如果是内连接,选择 cartesian join
如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
非等值连接情况
有join提示(hints),按照下面的顺序
broadcast hint:选择broadcast nested loop join.
shuffle replicate NL hint: 如果是内连接,则选择cartesian product join
没有join提示(hints),则逐个对照下面的规则
如果一张表足够小(可以被广播),则选择 broadcast nested loop join
- 如果是内连接,则选择cartesian product join
- 如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
参考
【1】:https://jiamaoxiang.top/2020/11/01/Spark%E7%9A%84%E4%BA%94%E7%A7%8DJOIN%E6%96%B9%E5%BC%8F%E8%A7%A3%E6%9E%90/
【2】:https://blog.csdn.net/wlk_328909605/article/details/82933552

若有收获,就点个赞吧
0 人点赞
