给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回 0。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
输入:beginWord = "hit",endWord = "cog",wordList = ["hot","dot","dog","lot","log","cog"]输出: 5解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",返回它的长度 5。
BFS
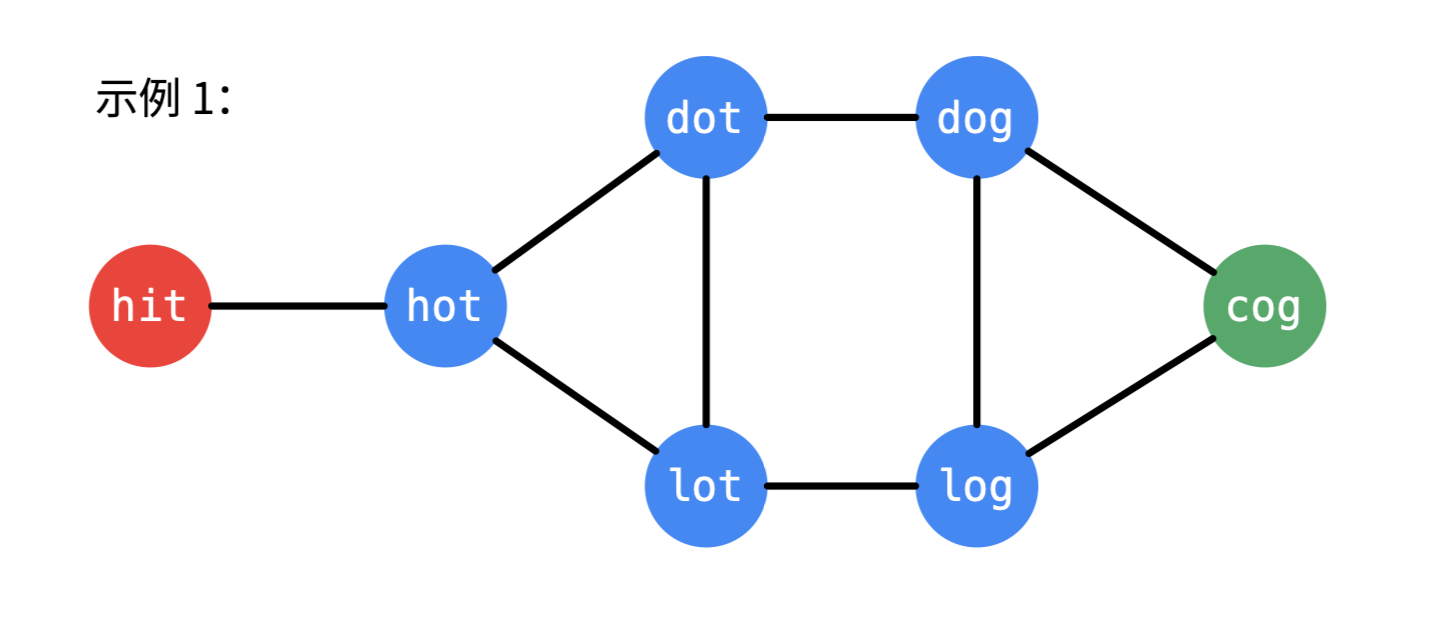
- 如果一开始就构建图,每一个单词都需要和除它以外的另外的单词进行比较,复杂度是 O(N \rm{wordLen})O(NwordLen),这里 NN 是单词列表的长度;
- 为此,我们在遍历一开始,把所有的单词列表放进一个哈希表中,然后在遍历的时候构建图,每一次得到在单词列表里可以转换的单词,复杂度是O(26×wordLen),借助哈希表,找到邻居与 NN 无关;
- 使用 BFS 进行遍历,需要的辅助数据结构是:队列;visited 集合。说明:可以直接在 wordSet (由 wordList 放进集合中得到)里做删除。但更好的做法是新开一个哈希表,遍历过的字符串放进哈希表里。这种做法具有普遍意义。
class Solution {public:int ladderLength(string beginWord, string endWord, vector<string>& wordList) {unordered_set<string> wordListSet(wordList.begin(), wordList.end());unordered_set<string> visited;queue<string> queueTodo;if (wordListSet.find(endWord) == wordListSet.end()) return 0; //注意先查找结果是否存在单词列表种int count = 1;queueTodo.push(beginWord);while (!queueTodo.empty()) {int len = queueTodo.size();for (int i = 0; i < len; i++) {string curWord = queueTodo.front(); queueTodo.pop();for (int j = 0; j < curWord.size(); j++) {char c = curWord[j];for (int k = 0; k < 26; k++) {curWord[j] = 'a' + k;if (curWord[j] == c) continue;if (curWord == endWord) return count+1; //不能用count++; 会加不上if (wordListSet.find(curWord) != wordListSet.end() && visited.find(curWord) == visited.end()) {queueTodo.push(curWord);visited.insert(curWord);}}curWord[j] = c;}}count++;}return 0;}};
双向BFS
从两端开始找,知道两端发生重合时,则说明找到了。
class Solution {public:int ladderLength(string beginWord, string endWord, vector<string>& wordList) {unordered_set<string> wordSet(wordList.begin(), wordList.end());//双向BFS 每次选择较小的一个,是因为较小的扩散的范围小,可以减少搜索。if (wordSet.find(endWord) == wordSet.end()) return 0;//用set 方便查找是否在另一个set里面,如果用队列的话,查找的时间复杂度为O(n)unordered_set<string> beginSet, endSet, visited, tmp;int resCount = 1;beginSet.insert(beginWord);endSet.insert(endWord);//bfs start herewhile(!beginSet.empty() && !endSet.empty()) {if (beginSet.size() > endSet.size()) {tmp = beginSet;beginSet = endSet;endSet = tmp;}tmp.clear();for (string curWord : beginSet) {for (int j = 0; j < curWord.size(); j++) {//依次换每个字符,与表中的单词做匹配char c = curWord[j];for (int k = 0; k < 26; k++) {curWord[j] = 'a' + k;if (endSet.find(curWord) != endSet.end()) {return resCount + 1;}if (wordSet.find(curWord) != wordSet.end() && visited.find(curWord) == visited.end()) {visited.insert(curWord);tmp.insert(curWord);}}curWord[j] = c;}}beginSet = tmp;// 当前层遍历完,清空,继续下一层遍历。 因为没有queue的出队,所以直接和一个set交换;resCount++;}return 0;}};

若有收获,就点个赞吧
0 人点赞
