二叉树节点结构
public class Node<V> {V value;Node<V> left;Node<V> right;public Node(V value) {this.value = value;}}
工具类
import java.util.HashMap;import java.util.Map;public class TreeGenerator {/*** 根据传入数组按照层级生成一棵树*/public static Node getTree(int[] arr) {if (arr == null || arr.length == 0) return null;Map<Integer, Node> map = new HashMap<>();for (int i = 0; i < arr.length; i++) {map.put(i, new Node(arr[i]));}for (int i = 1; i < arr.length; i++) {// 父节点int index = (i - 1) / 2;Node node = map.get(index);if (node.left == null) {node.left = map.get(i);} else {node.right = map.get(i);}}return map.get(0);}}
遍历
递归实现
使用递归实现二叉树的前序、中序、后序遍历
public class RecursionTraversal {
public static void preorder(Node tree) {
if (tree == null) return;
System.out.print(tree.value + "\t");
preorder(tree.left);
preorder(tree.right);
}
public static void middleOrder(Node tree) {
if (tree == null) return;
middleOrder(tree.left);
System.out.print(tree.value + "\t");
middleOrder(tree.right);
}
public static void postorder(Node tree) {
if (tree == null) return;
postorder(tree.left);
postorder(tree.right);
System.out.print(tree.value + "\t");
}
public static void main(String[] args) {
Node tree = TreeGenerator.getTree(new int[]{1, 2, 3, 4, 5, 6});
preorder(tree);
System.out.println();
middleOrder(tree);
System.out.println();
postorder(tree);
}
}
非递归实现
使用非递归实现二叉树的前序、中序、后序遍历
思路:使用栈结构
前序遍历步骤:
- 将当前节点压栈并打印当前节点 value 后弹出
- 按照先右子节点后左子节点的顺序压栈
- 打印顶端节点 value 并弹出,重复第 2 步
中序遍历步骤:
- 将当前节点已经当前节点的所有左子节点依次压入栈
- 弹出顶部节点,并打印 value
- 将弹出节点的右子树执行 第 1 步
后续遍历:使用两个栈,分别为 stack 和 stackHead
- 当前节点压入 stack 中
- stack 顶部节点弹出,并压入 stackHead 中
- stackHead 顶部节点弹出,将该节点的左右子节点压入 stack 中,循环第 1 步,直到 stack 栈为空
- 弹出 stackHead 栈中的所有节点并打印 value ```java import java.util.Stack;
public class NotRecursionTraversal {
public static void preorder(Node tree) {
if (tree == null) return;
Stack<Node> stack = new Stack<>();
stack.push(tree);
while (!stack.empty()) {
Node node = stack.pop();
System.out.print(node.value + "\t");
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
}
}
public static void middleOrder(Node tree) {
if (tree == null) return;
Stack<Node> stack = new Stack<>();
Node cur = tree;
while (!stack.empty() || cur != null) {
if (cur != null) {
stack.push(cur);
cur = cur.left;
} else {
cur = stack.pop();
System.out.print(cur.value + "\t");
cur = cur.right;
}
}
}
public static void postorder(Node tree) {
if (tree == null) return;
Stack<Node> stack = new Stack<>();
Stack<Node> stackHead = new Stack<>();
stack.push(tree);
while (!stack.empty()) {
Node cur = stack.pop();
stackHead.push(cur);
if (cur.left != null) stack.push(cur.left);
if (cur.right != null) stack.push(cur.right);
}
while (!stackHead.empty()) {
System.out.print(stackHead.pop().value + "\t");
}
}
public static void main(String[] args) {
Node tree = TreeGenerator.getTree(new int[]{1, 2, 3, 4, 5, 6});
preorder(tree);
System.out.println();
middleOrder(tree);
System.out.println();
postorder(tree);
}
}
<a name="26HWR"></a>
## 宽度优先遍历
宽度优先遍历,可以叫做层序遍历,就是把二叉树逐层遍历。<br />思路:使用队列 queue,把当前节点放入 queue 中,弹出后依次把当前节点的左右子节点放入 queue 中,直到 queue 中所有元素弹出,就完成了遍历
```java
public static void traversal(Node head) {
if (head == null) return;
Queue<Node> queue = new LinkedList<>();
queue.add(head);
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.print(cur.value + "\t");
if (cur.left != null) queue.add(cur.left);
if (cur.right != null) queue.add(cur.right);
}
System.out.println();
}
能否在得到一个二叉树的宽度?
思路:
需要的变量:
- 一个 map 记录每个节点对应的是在第几层的
- 一个记录当前遍历到第几层的
int level - 一个记录当前层级宽度的
int levelWidth - 一个记录最大宽度的
int maxWidth - 一个队列
步骤:
- 将头节点放入队列
- 开始遍历树
- 通过 map 获取当前节点是在第几层级 curLevel
- 如果 curLevel == level,说明该节点是当前遍历的层级,该层级节点数 +1, 即
levelWidth ++; - 如果 curLevel != level,说明一件开始遍历下一层级,当前层级宽度 levelWidth 已经统计完成,需要做的操作有
- 比较是否需要更新最大宽度
maxWidth = Math.max(maxWidth, levelWidth) - 当新的层级宽度置为 1,
levelWidth = 1 - 遍历层级加一,
level++
- 比较是否需要更新最大宽度
- 如果 curLevel == level,说明该节点是当前遍历的层级,该层级节点数 +1, 即
- 将当前节点的左右子节点放到队列中,并且存放到 map 中记录层级为下一层
以上过程可以获取到的有:
- 最大宽度
maxWidth - 最大深度
level - 每一层的宽度
level - 优先遍历(层序遍历) ```java import java.util.HashMap; import java.util.LinkedList; import java.util.Map; import java.util.Queue;
public class MaxWidth {
public static int getMaxWidth(Node head) {
if (head == null) return 0;
// 记录节点对应的层级
Map<Node, Integer> map = new HashMap<>();
// 当前遍历的层级
int level = 1;
// 当前层级的宽度
int levelWidth = 0;
// 最大宽度
int maxWidth = 1;
map.put(head, level);
Queue<Node> queue = new LinkedList<>();
queue.add(head);
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.print(cur.value + "\t");
// 当前节点对应的层级
Integer curLevel = map.get(cur);
if (curLevel == level) {
levelWidth++;
} else {
// 说明一件开始遍历下一层级,当前层级宽度 levelWidth 已经统计完成
maxWidth = Math.max(maxWidth, levelWidth);
levelWidth = 1;
level++;
}
if (cur.left != null) {
queue.add(cur.left);
map.put(cur.left, level + 1);
}
if (cur.right != null) {
queue.add(cur.right);
map.put(cur.right, level + 1);
}
}
System.out.println();
return maxWidth;
}
public static void main(String[] args) {
/**
* 0
* / \
* 1 2
* / \
* 3 4
* / / \
* 6 5 8
* \
* 7
*/
Node head = new Node(0);
Node node1 = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
Node node4 = new Node(4);
Node node5 = new Node(5);
Node node6 = new Node(6);
Node node7 = new Node(7);
Node node8 = new Node(8);
head.left = node1;
head.right = node2;
node1.left = node3;
node3.left = node6;
node6.right = node7;
node2.right = node4;
node4.left = node5;
node4.right = node8;
System.out.println(getMaxWidth(head));
}
}
结果
0 1 2 3 4 6 5 8 7
3
也可以有更简单些的做法:直接对记录节点对应层级的哈希表进行统计,得到每层对应的节点数<br />虽然代码看起来多了,但是不用处理那么多的变量了
```java
public static int getMaxWidth(Node head) {
if (head == null) return 0;
// 记录节点对应的层级
Map<Node, Integer> nodeLevelMap = new HashMap<>();
int level = 1;
nodeLevelMap.put(head, level);
Queue<Node> queue = new LinkedList<>();
queue.add(head);
while (!queue.isEmpty()) {
Node cur = queue.poll();
// 当前节点对应的层级
Integer curLevel = nodeLevelMap.get(cur);
if (curLevel != level) {
// 已经遍历到下一层
level++;
}
if (cur.left != null) {
queue.add(cur.left);
nodeLevelMap.put(cur.left, level + 1);
}
if (cur.right != null) {
queue.add(cur.right);
nodeLevelMap.put(cur.right, level + 1);
}
}
// 统计每个层级的节点数
Map<Integer, Integer> levelCountMap = new HashMap<>();
for (Map.Entry<Node, Integer> entry : nodeLevelMap.entrySet()) {
Integer value = entry.getValue();
if (!levelCountMap.containsKey(value)) {
levelCountMap.put(value, 0);
}
levelCountMap.put(value, levelCountMap.get(value) + 1);
}
int maxWidth = -1;
for (Map.Entry<Integer, Integer> entry : levelCountMap.entrySet()) {
maxWidth = Math.max(maxWidth, entry.getValue());
}
return maxWidth;
}
不使用 map 的思路:
使用到的变量/容器:
- 一个队列
queue:用于层级遍历 int maxWidth:记录最大宽度int curWidth:当前层级宽度Node curEnd:当前层级最后一个节点Node nextEnd:下一层级最后一个节点
步骤:遍历树,在遍历中执行
- 弹出当前节点时,先将当前节点的左右子节点依次放入 queue 中,每放入一个子节点就将
nextEnd更新。(因为本层最后一个节点被弹出了后,下一层的最后一个节点一定是本层的某个子节点,也就是说nextEnd必定为下一层的最后一个节点) - 判断当前节点是否是本层的最后一个节点:
不是最后一个节点,本层宽度 curWidth ++
是最后一个节点,需要:
- 更新最大宽度
- 将本层最后一个节点
curEnd指向下一层最后一个节点nextEnd 重置
curWidth为 1public static int getMaxWidth(Node head) { if (head == null) return 0; // 最大宽度 int maxWidth = 1; // 当前层级最后一个节点 Node curEnd = head; // 下一层级最后一个节点 Node nextEnd = null; // 当前层级宽度 int curWidth = 1; Queue<Node> queue = new LinkedList<>(); queue.add(head); while (!queue.isEmpty()) { Node cur = queue.poll(); if (cur.left != null) { queue.add(cur.left); nextEnd = cur.left; } if (cur.right != null) { queue.add(cur.right); nextEnd = cur.right; } if (cur == curEnd) { // 已经遍历到当前层级最后一个 maxWidth = Math.max(maxWidth, curWidth); curEnd = nextEnd; curWidth = 1; } else { curWidth++; } } return maxWidth; }相关实现判断
判断一棵树是否是搜索二叉树?
搜索二叉树:左子节点的值全部小于父节点,右子节点的值全部大于父节点
思路:左 < 中 < 右 使用中序遍历来判断
判断一棵树是否是完全二叉树?
完全二叉树:若设二叉树的深度为 n,除第 n 层外,其它各层 (1~n-1) 的结点数都达到最大个数,第 n 层所有的结点都连续集中在最左边,这就是完全二叉树。
思路:
每层都是满的使用层级遍历,如果遇到以下情况就不是完全二叉树:
- 某个节点有右子节点没有左子节点
- 在满足 1 的条件下,如果遇到了第一个节点的子节点不全,那么后续的所有的节点都不会有子节点(这个节点在 n-1层,是最后一个有子节点的节点)
判断一棵树是否是满二叉树?
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。
思路1:最大深度为 n,节点数为  个,获取最大深度和节点总数看是否符合条件
个,获取最大深度和节点总数看是否符合条件
思路2:参考上面判断完全二叉树逻辑,在遍历每层时判断本层节点数量是否是上层的 2 倍
判断一棵树是否是平衡二叉树?
平衡二叉树:任意节点的子树的高度差都小于等于1
思路:
要满足是平衡二叉树就需要同时满足以下条件:
- 左子树是平衡二叉树
- 右子树是平衡二叉树
| 左树高度 - 右树高度 | <= 1
public class IsBalancedTree { public static boolean isBalancedTree(Node head) { return process(head).isBalanced; } /** * 返回数据结构 */ public static class ReturnType { // 是否平衡 public boolean isBalanced; // 树高度 public int height; public ReturnType(boolean isBalanced, int height) { this.isBalanced = isBalanced; this.height = height; } } public static ReturnType process(Node node) { if (node == null) return new ReturnType(true, 0); ReturnType leftData = process(node.left); ReturnType rightData = process(node.right); // 当前树高度 int height = Math.max(leftData.height, rightData.height) + 1; // 是否是平衡树 boolean isBalanced = leftData.isBalanced && rightData.isBalanced && Math.abs(leftData.height - rightData.height) <= 1; return new ReturnType(isBalanced, height); } }以上可以总结出二叉树DP(动态规划)的一些套路:如果可以分别向左右子树去要一些信息就能得出结论,统一可以以下的模板来解决
public class xxxClass { public static boolean isXXX(Node head) { return process(head).isXXX; } /** * 返回数据结构 */ public static class ReturnType { // 具体要想左右子树获取的信息 public ReturnType(……) { // 全参构造 } } public static ReturnType process(Node<Integer> node) { if (node == null) { // 这里看情况返回 null 或者 new ReturnType(……) return null; } ReturnType leftData = process(node.left); ReturnType rightData = process(node.right); // 根据 leftData 和 rightData 来获取当前节点信息 return new ReturnType(……); } }例如上面判断一棵树是否是搜索二叉树也可以使用这个套路:
左子树是 BST 树
- 右子树是 BST 树
- 左子树的最大值 < 当前节点 && 右子树的最小值 > 当前节点
综上,向左右子树获取的信息有
- 树的最大值
- 树的最小值
当前树是否是搜索二叉树
public class IsBST { public static boolean isBST(Node head) { return process(head).isBST; } /** * 返回数据结构 */ public static class ReturnType { // 是否是搜索二叉树 public boolean isBST; // 树最大值 public int max; // 树最小值 public int min; public ReturnType(boolean isBST, int max, int min) { this.isBST = isBST; this.max = max; this.min = min; } } public static ReturnType process(Node<Integer> node) { if (node == null) return null; ReturnType leftData = process(node.left); ReturnType rightData = process(node.right); int max = node.value; int min = node.value; if (leftData != null) { max = Math.max(max, leftData.max); min = Math.min(min, leftData.min); } if (rightData != null) { max = Math.max(max, rightData.max); min = Math.min(min, rightData.min); } // 是否是平衡树 boolean isBST = true; if (leftData != null && (!leftData.isBST || leftData.max >= node.value)) { isBST = false; } if (rightData != null && (!rightData.isBST || rightData.min <= node.value)) { isBST = false; } return new ReturnType(isBST, max, min); } }
公共祖先节点
给定两个二叉树的节点 nodeA 和 nodeB,找到他们的最低公共祖先节点
方法一:
- 遍历树,将所有节点和该节点的父节点保存到哈希表中
- 将哈希表中所有 nodeA 的父节点放到 set 中
- 遍历 nodeB 的所有父节点,如果在 set 中存在,该节点就是最低公共祖先节点 ```java import java.util.HashMap; import java.util.HashSet; import java.util.Set;
public class LowestAncestor {
public static Node lowestAncestor1(Node head, Node nodeA, Node nodeB) {
HashMap<Node, Node> fatherMap = new HashMap<>();
fatherMap.put(head, head);
process(head, fatherMap);
Set<Node> set = new HashSet<>();
Node cur = nodeA;
while (cur != fatherMap.get(cur)) {
set.add(cur);
cur = fatherMap.get(cur);
}
set.add(head);
cur = nodeB;
while (cur != fatherMap.get(cur)) {
if (set.contains(cur)) return cur;
cur = fatherMap.get(cur);
}
return head;
}
public static void process(Node head, HashMap<Node, Node> fatherMap) {
if (head == null) return;
fatherMap.put(head.left, head);
fatherMap.put(head.right, head);
process(head.left, fatherMap);
process(head.right, fatherMap);
}
public static void main(String[] args) {
/**
* a
* / \
* b c
* /
* e
* / \
* j f
* / \
* h g
*/
Node a = new Node("a");
Node b = new Node("b");
Node c = new Node("c");
Node d = new Node("d");
Node e = new Node("e");
Node f = new Node("f");
Node g = new Node("g");
Node h = new Node("h");
Node j = new Node("j");
a.left = b;
a.right = c;
b.left = d;
d.left = e;
e.right = f;
e.left = j;
f.right = g;
f.left = h;
System.out.println(lowestAncestor1(a, d, g));
System.out.println(lowestAncestor1(a, j, h));
}
}
方法二:这个思路画个图看会好点,不画图说不清,具体思路略……
```java
public static Node lowestAncestor(Node head, Node nodeA, Node nodeB) {
if (head == null || head == nodeA || head == nodeB) {
return head;
}
Node left = lowestAncestor(head.left, nodeA, nodeB);
Node right = lowestAncestor(head.right, nodeA, nodeB);
if (left != null && right != null) {
return head;
}
return left != null ? left : right;
}
方法三:使用 DP 套路:如果某个节点的已经满足了既存在 nodeA 又存在 nodeB 就返回
public static Node lowestAncestor(Node head, Node nodeA, Node nodeB) {
return process(head, nodeA, nodeB).node;
}
public static class ReturnType {
boolean existA;
boolean existB;
Node node = null;
public ReturnType(boolean existA, boolean existB) {
this.existA = existA;
this.existB = existB;
}
}
public static ReturnType process(Node head, Node nodeA, Node nodeB) {
if (head == null) {
return new ReturnType(false, false);
}
ReturnType leftData = process(head.left, nodeA, nodeB);
if (leftData.node != null) return leftData;
ReturnType rightData = process(head.right, nodeA, nodeB);
if (rightData.node != null) return rightData;
boolean existA = leftData.existA || rightData.existA || head == nodeA;
boolean existB = leftData.existB || rightData.existB || head == nodeB;
if (existA && existB) {
ReturnType returnType = new ReturnType(true, true);
returnType.node = head;
return returnType;
}
return new ReturnType(existA, existB);
}
后继节点
在二叉树中找到一个节点的后继节点
现有一种新的二叉树节点类型如下:
public class Node {
int value;
Node left;
Node right;
Node parent;
public Node() {}
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
}
该结构比普通二叉树节点结构多了一个指向父节点的parent指针。
假设有一标 Node 类型的节点组成的二叉树,树中每个节点的 parent 指针都正确地指向自己的父节点,头节点的 parent 指向 null。
只给一个在二叉树中的某个节点 node,请实现返回 node 的后继节点的函数。
在二叉树的中序遍历的序列中,node 的下一个节点叫作 node 的后继节点。
思路:这里提供了父节点指针,也就不用中序遍历就可以找到后继节点,假设 node 和它的后继节点距离为 k,最少只需要 k 次就可以找到后继节点
- node 有右子树,后继为右子树上的最左子节点
node 无右子树,就向上找父节点,直到找到 node 是父节点的左子树,后继节点就是该父节点;如果 node 是整棵树的最右子节点那就会找到根节点,此时后继节点为 null
public class SeccessorNode { public static Node getSeccessorNode(Node node) { if (node == null) return null; if (node.right != null) { return getLeftMost(node.right); } else { Node parent = node.parent; while (parent != null && parent.left != null) { node = parent; parent = node.parent; } return parent; } } private static Node getLeftMost(Node node) { if (node == null) return null; while (node.left != null) { node = node.left; } return node; } }序列化和反序列化
内存里的一棵树如何变成字符串形式,又如何从字符串变成还原?
思路:按照统一顺序遍历,如前序遍历,然后用特殊的符号来表示一个值的结束以及 null,例如树: 1 / \ null 2 / \ 3 null / \ null null 用,表示一个值的结束,# 表示 null 字符串: 1,#,2,3,#,#,#,```java import java.util.LinkedList; import java.util.Queue;
public class SerializeTree {
static String str = "";
public static String serializeTree(Node head) {
if (head != null) {
str += head.value + ",";
serializeTree(head.left);
serializeTree(head.right);
} else {
str += "#,";
}
return str;
}
public static Node deserializeTree(String str) {
if (str == null) return null;
String[] strNodes = str.split(",");
Queue<String> queue = new LinkedList<>();
for (String s : strNodes) {
queue.add(s);
}
return deserialize(queue);
}
private static Node deserialize(Queue<String> queue) {
String str = queue.poll();
if ("#".equals(str)) {
return null;
}
Node head = new Node(Integer.parseInt(str));
head.left = deserialize(queue);
head.right = deserialize(queue);
return head;
}
public static void main(String[] args) {
/**
* 1
* / \
* null 2
* / \
* 3 null
* / \
* null null
*/
Node node1 = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
node1.right = node2;
node2.left = node3;
String s = serializeTree(node1);
System.out.println(s);
Node head = deserializeTree(s);
System.out.println();
}
}
<a name="5OKuT"></a>
# 折纸问题
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。<br />此时折痕是凹下去的,即折痕突起的方向指向纸条的背面。<br />如果从纸条的下边向上方连续对折2次,压出折痕后展开,此时有三条折痕,从上到下依次是下折痕、下折痕和上折痕。<br />给定一个输入参数 N,代表纸条都从下边向上方连续对折 N 次。<br />请从上到下打印所有折痕的方向。<br />例如:
- N=1 时,打印:down
- N=2 时,打印:down down up
这个最好自己折一下纸,就会发现规律:<br />每次折纸都会出现在原先 down 的两侧会出现一个 down 和一个 up,并且左边为 down 右边为 up。即每次都会在当前节点下生成一个 down左子节点 up 右子节点<br />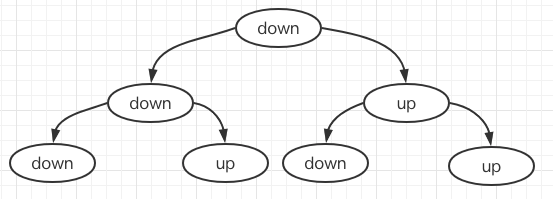
```java
public class PaperFolding {
public static void printAllFolds(int n) {
printProcess(1, n, true);
System.out.println();
}
private static void printProcess(int i, int n, boolean down) {
if (i > n) return;
printProcess(i + 1, n, true);
System.out.print((down ? "dwon" : "up") + "\t");
printProcess(i + 1, n, false);
}
public static void main(String[] args) {
printAllFolds(1);
printAllFolds(2);
printAllFolds(3);
printAllFolds(4);
}
}

若有收获,就点个赞吧
0 人点赞
