哈希函数
哈希函数(散列函数)能够将任意长度的输入值转变成固定长度的值输出,该值称为散列值,输出值通常为字母与数字组合。
哈希函数的特点:
- 输入域无穷大,输出域是范围固定。如 MD5 的输出域为
0 ~ 2^64-1,sha1 为0 ~ 2^128-1 - 只要输入值不变,那么输出的值也是唯一不变的。也就是说,产生的输出值不能试随机的
- 由于输入域无穷输出域范围固定,在输入足够多的情况下,不同的输入也会出现重复的输出值,被称为哈希碰撞。哈希碰撞要的几率要足够低
- 很好的离散性:输入值发生轻微改变输出值改变会非常大
- 很好的均匀性:输出值在输出域上分布的足够均匀
- 均匀性和离散性实际上是一致的,如果相似的输入值得到输出结果也是相似的,也就是在输出域上的分布比较集中,也不会有很好的均匀性
如果存在一个哈希函数 f 的输出域为 S,对输出值做 输出值 % m 操作,则结果也在 [0, m-1] 上均匀分布,即下图
40 亿
给定存放 40 亿个无符号正数的大文件,请使用最多 1 G 内存找到重复出现次数最多的数?
思路:
首先不考虑 40 亿的数量和 1G 内存的限制,如何来找到一堆数中重复最多的数?
一般情况下,我们会使用一个 HashMap 来统计每个数出现的次数,然后取出出现最多的数
然后加上限制条件:一条 HashMap 记录是由 一个 key 和 一个 value 组成的,一个 int key 占用 4B,一个 int value 占用 4B,即一条记录至少占用 8B(这里不考虑哈希表内部其他的数据结构的空间)1G = 1024 M = 1024*1024 K = 1024*1024*1024 B ,那么 1G 最多可以保存 1024*1024*1024/8 = 2^27 = 134217728 条数数据,40 亿个数如果有超过 134217728 个数是不同的,那 1G 内存就不够了。
解决方案:
遍历 40 亿大文件,实现一个哈希函数将输出值 out = num[i] % 100,根据结果把遍历的数据放到第 out 小文件中,这样原先的 40 亿大文件就会均匀的分布到 100 个小文件中,每个文件的数据量为四千万左右,且相同的数会被分片到同一个小文件中,对每个小文件进行统计保留统计结果最多就可以得到出现次数最多的数
伪代码实现:
import java.io.*;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;public class FourBillion {int getMax(File file) {int fileNum = 100;// 100 个小文件FileWriter[] minFiles = new FileWriter[fileNum];for (int i = 0; i < fileNum; i++) {try {minFiles[i] = new FileWriter(i + ".csv");} catch (IOException e) {if (minFiles[i] != null) {try {minFiles[i].close();} catch (IOException ioException) {ioException.printStackTrace();}}}}// 这里假定读取的是 csv 文件,按行读取try (BufferedReader reader = new BufferedReader(new FileReader(file))) {String row = null;while ((row = reader.readLine()) != null) {String[] strArr = row.split(",");for (String s : strArr) {// 放到小文件中int i = hash(Integer.parseInt(s)) % fileNum;minFiles[i].write(s + ",");}}} catch (IOException e) {e.printStackTrace();}// 关闭文件流for (FileWriter writer : minFiles) {if (writer == null) continue;try {writer.close();} catch (IOException e) {e.printStackTrace();}}List<Integer> byteList = new ArrayList<>();Map<Integer, Integer> timeMap = new HashMap<>();// 本次出现最多的数int maxTimeNum = -1;// 本次出现最多的次数int maxTime = -1;// 对每个小文件读取最大值for (int i = 0; i < fileNum; i++) {try (FileInputStream is = new FileInputStream(new File(i + ".csv"))) {int cur;while ((cur = is.read()) != -1) {if (44 != cur) { // 44 是逗号byteList.add(cur - 48);} else {doAction(byteList, timeMap);}}doAction(byteList, timeMap);// 只保留每个小文件出现次数最多的数据for (Map.Entry<Integer, Integer> entry : timeMap.entrySet()) {if (maxTime < entry.getValue()) {maxTimeNum = entry.getKey();maxTime = entry.getValue();}}timeMap.clear();timeMap.put(maxTimeNum, maxTime);} catch (IOException e) {e.printStackTrace();}}return maxTimeNum;}// 统计出现的次数private void doAction(List<Integer> byteList, Map<Integer, Integer> timeMap) {Integer num = parseToInt(byteList);if (!timeMap.containsKey(num)) {timeMap.put(num, 0);}timeMap.put(num, timeMap.get(num) + 1);byteList.clear();}// 将收集的一个数解析出来private static Integer parseToInt(List<Integer> byteList) {int num = 0;int size = byteList.size();for (int i = 0; i < size; i++) {num += byteList.get(i) * Math.pow(10, size - i - 1);}return num;}int hash(int num) {//TODO 这里是hash具体的实现 略return num;}}
哈希表
散列表(Hash table,也叫哈希表),是根据关键码值 (Key value) 而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数(哈希函数),存放记录的数组叫做散列表。
数据结构参考 Java 的 HashMap。
哈希表是用哈希函数来计算存放到表中的位置的(可以使用 hash结果 % 表长度 )。由于哈希表的长度不会很大,哈希表中一定会发生哈希碰撞,在 Java HashMap 中使用链地址发来解决。将相同哈希结果的记录组成链表保存到该位置。由于哈希函数的均匀性,每条链表基本上能保证均匀变长的
**
设计 RandomPool 结构
设计一种结构,在该结构中有如下三个功能:
- insert(key):将某个 key 加入到该结构,做到不重复加入
- delete(key):将原本在结构中的某个 key 移除
- getRandom():等概率随机返回结构中的任何一个key。
【要求】
Insert、delete 和 getRandom方法的时间复杂度都是 O(1)
思路:
使用两个 Map 分别记录
- <数据,顺序> keyIndexMap
- <顺序,数据> indexKeyMap
在 getRandom 时使用 Random 随机获取一个 [0, size - 1] 之间的数作为下标,从 indexKeyMap 获取 key
在删除时,keyIndexMap 正常删除,indexKeyMap 删除顺序后会造成 getRandom 方法获取到的值会有可能已经被删除了,那就把最后一个值放到该下标所在位置
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
public class RandomPool<E> {
private int size;
private Map<E, Integer> keyIndexMap;
private Map<Integer, E> indexKeyMap;
public RandomPool() {
this.size = 0;
this.keyIndexMap = new HashMap<>();
this.indexKeyMap = new HashMap<>();
}
@Override
public String toString() {
return "RandomPool{" +
"map=" + keyIndexMap.keySet() +
'}';
}
public void insert(E key) {
if (!keyIndexMap.containsKey(key)) {
keyIndexMap.put(key, size);
indexKeyMap.put(size, key);
size++;
}
}
public void delete(E key) {
if (keyIndexMap.containsKey(key)) {
Integer index = keyIndexMap.get(key);
keyIndexMap.remove(key);
indexKeyMap.put(index, indexKeyMap.get(size--));
indexKeyMap.remove(size);
}
}
public E getRandom() {
if (size == 0) return null;
int index = new Random().nextInt(size);
return indexKeyMap.get(index);
}
public static void main(String[] args) {
RandomPool<String> pool = new RandomPool<>();
pool.insert("A");
pool.insert("B");
pool.insert("C");
pool.insert("D");
System.out.println(pool);
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
pool.delete("C");
System.out.println(pool);
pool.delete("B");
System.out.println(pool);
}
}
结果
RandomPool{map=[A, B, C, D]}
D
C
A
C
RandomPool{map=[A, B, D]}
RandomPool{map=[A, D]}
布隆过滤器
主要是解决黑名单问题,爬虫的去重问题等
如黑名单系统,有100亿个 URL 黑名单,如何快速检索到一个 URL 是否在黑名单中?
假设每个 URL 最大为 64 bit,如果使用 HashMap,至少需要 6400 亿 bit ≈ 640 G,全部放到内存中肯定是不行的,如果将大部分数据放到硬盘中那每次查询的效率太低了
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比传统的List、Map 容器,布隆过滤器使用的空间会更少,查询效率更高,但缺点是返回的结果是概率性的。
如:访问的 URL 不在黑名单中,但是返回的结果是在黑名单中;但是如果 URL 在黑名单中,那么返回结果一定会是在黑名单中。可以通过人为设计来让布隆过滤器的“失误率”降低
要节省空间最好使用最小的单位 bit 来表示状态,代码如下:
// int = 8 * 4 = 32 bit
int a = 0;
// 能表示 32 bit * 10 = 320 bit
int[] arr = new int[10];
// 获取 第 178 个 bit 的状态
int i = 178;
// 计算出从哪个下标的 int 来找,每个 int 代表 32 bit,下标为 178/32
int numIndex = 178 / 32;
// 计算在这个 int 上第几个 bit
int bitIndex = 178 % 32;
// 获取第 178 的状态
int state = ((arr[numIndex] >> bitIndex) & 1);
// 把 178 位的状态改为 1
arr[numIndex] = arr[numIndex] | (1 << bitIndex);
// 把 178 位的状态改为 0
arr[numIndex] = arr[numIndex] & (~(1 << bitIndex));
布隆过滤器就是使用的 bit 位来计算,一个长为 m 的 bit 数组,有 k 个 hash 函数,假定 m = 10,k = 3,初始状态如下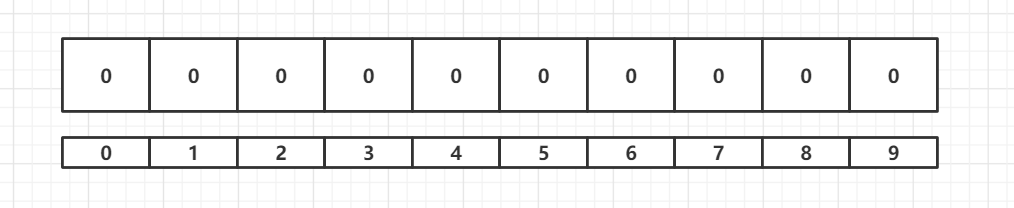
字符串“张三”经过 hash1、hash2、hash3的计算后进行 %m 后落到了数组1、3、5上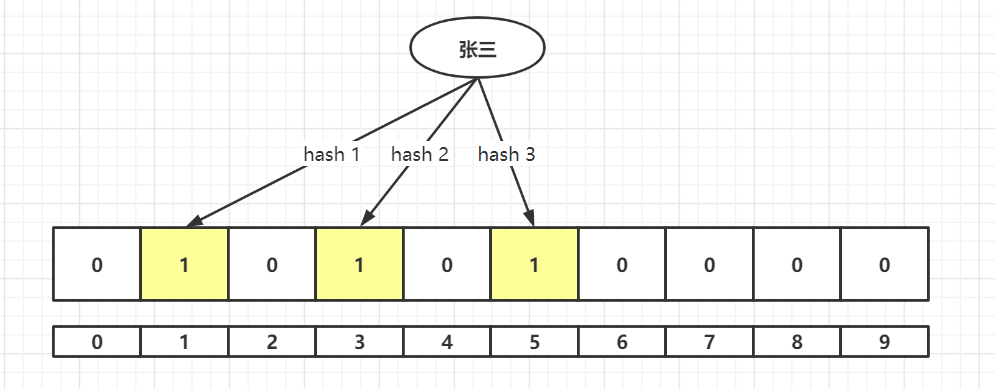
字符串“李四”经过 hash1、hash2、hash3的计算后进行 %m 后落到了数组3、6、9上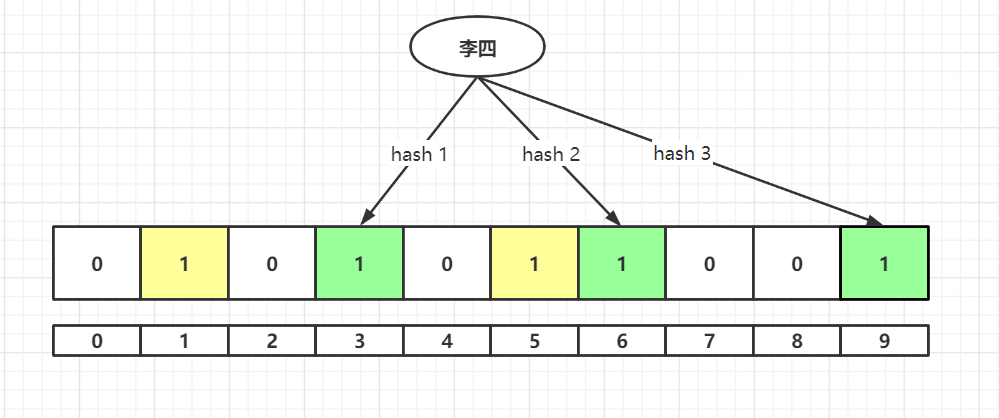
开始查询
- 需要查询字符串“王五”是否存在,经过 hash1、hash2、hash3的计算后进行
%m后落到了数组2、4、6上,而这个三个下标的数值不全为 1,则说明“王五”不存在; - 需要查询字符串“赵六”是否存在,经过 hash1、hash2、hash3的计算后进行
%m后落到了数组3、5、6上,而这个三个下标的数值全为 1,则说明“赵六”存在
但实际上“赵六”并不存在,属于误报,这也说明了布隆过滤器的概率性:如果布隆过滤器返回的结果是不存在,说明该值一定不存在;如果返回的是存在,该值不一定存在
**
影响布隆过滤器失误率的就是 hash 函数的个数 k,和位图长度 m
- m 的影响是最重要的,如果 m 够大,那么发生误报的几率就会足够小
- k 的也会有影响:k 相当于是对数据进行采样的次数,如果 k 太小采集的样本不够,如果过大就会导致失误率增大
那应该怎么选择 k、m呢?
对于样本量 n,失误率 p,需要空间 m 为  ,hash 函数数量 k 为
,hash 函数数量 k 为 
得到的结果 m 还需要除以 8,因为 m 是bit 长度,对于要求失误率为万分之一的样本量为 100 亿的数据来说,最后需要 26 G
对于已经确定的 样本量 n、hash 函数个数 k、空间 m,失误率 p 为 
一致性哈希
在 3 台服务器上分别部署了一个数据库服务,如果在数据库存储数据时只考虑让数据尽可能的均匀的分别到每个数据库中,你会怎么做?
一般情况下,根据数据的某个值作为 key 来划分,如用户的名字,进行 hash 得到的结果对 3 取模,然后将数据保存到改数据库中。
就能较好的使数据均匀分布,但是十分注重 key 的选择。如:保存用户,如果选择性别作为 key,因为性别只有男、女两种,hash 后就只有两种情况,也就是说最对使用两个数据库服务器
看似很好的完成了数据的均匀分布,但是这样会产生新的问题:假如 3 台数据库服务器还是压力太大,现在决定要加一台服务器数据要怎么做迁移?
对新的数据 hash 后取模 4 么?那么旧数据如何查询?如果对旧数据全部重新计算代价是否能接受?
网上已经有很多资料了,可以看看:一致性哈希算法原理
一致性哈希的问题:
- 在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题
- 一旦 增加/减少 一台机器,数据马上就会变得不均衡
以上两个问题都可以通过虚拟节点来解决:
使用的服务器并不是 3 个,而是对于每个服务器有 100 个虚拟节点 A [0, 99]、B [0, 99]、C [0, 99],对这些虚拟节点进行 hash 计算后均匀的分布到环上,保证了环上任意一段都存在了 A、B、C 的节点且每个节点的比例大致相同,即每个服务器都能拿到 1/3 的数据。此时,新增加了 D 服务器,而 D 服务器的 100 个虚拟节点会均匀分散到环上,也就是说 D 会从 A、B、C 上均匀的迁移一部分数据从而维持了数据均衡

若有收获,就点个赞吧
0 人点赞
