岛问题
一个矩阵中只有 0 和 1 两种值,每个位置都可以和自己的上、下、左、右四个位置相连,如果有一片 1 连在一起,这个部分叫做一个岛,求一个矩阵中有多少个岛?
【举例】
001010111010100100000000
这个矩阵中有三个岛
思路:
- 设计一个感染方法(
infect(int i, int j)),该方法的作用是将传入的[i,j]以及所有和[i,j]相连的 1 都修改为 2 - 遍历矩阵,每次遍历到 1 就执行 infect,0、2 就跳过
- 执行了多少次 infect 方法就有几个岛
import java.util.LinkedList;
import java.util.Queue;
public class Islands {
static int countIslands(int[][] matrix) {
if (matrix == null || matrix[0] == null) return 0;
int count = 0;
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[i].length; j++) {
if (matrix[i][j] == 1) {
infect(i, j, matrix);
count++;
}
}
}
return count;
}
static void infect(int i, int j, int[][] matrix) {
Queue<int[]> queue = new LinkedList<>();
queue.add(new int[]{i, j});
while (!queue.isEmpty()) {
int[] index = queue.poll();
i = index[0];
j = index[1];
matrix[i][j] = 2;
if (i - 1 >= 0 && matrix[i - 1][j] == 1) { // 上
queue.add(new int[]{i - 1, j});
}
if (i + 1 < matrix.length && matrix[i + 1][j] == 1) { // 下
queue.add(new int[]{i + 1, j});
}
if (j - 1 >= 0 && matrix[i][j - 1] == 1) { // 左
queue.add(new int[]{i, j - 1});
}
if (j + 1 < matrix[i].length && matrix[i][j + 1] == 1) { // 右
queue.add(new int[]{i, j + 1});
}
}
}
public static void main(String[] args) {
int[][] matrix = new int[][]{
new int[]{0, 0, 1, 0, 1, 0},
new int[]{1, 1, 1, 0, 1, 0},
new int[]{1, 0, 0, 1, 0, 0},
new int[]{0, 0, 0, 0, 0, 0}
};
System.out.println(countIslands(matrix));
}
}
结果
3
当然,infect 方法也可以使用递归调用,但是效率会低一些。如下:
static void infect(int i, int j, int[][] matrix) {
if (i < 0 || i >= matrix.length || j < 0 || j >= matrix[0].length || matrix[i][j] != 1) return;
matrix[i][j] = 2;
infect(i + 1, j, matrix);
infect(i - 1, j, matrix);
infect(i, j + 1, matrix);
infect(i, j - 1, matrix);
}
如果这个矩阵非常大,如何提升效率呢?
进阶:如何设计一个并行算法解决这个问题
并查集
主要用于解决一些元素分组的问题。它管理一系列不相交的集合:
- 判断某两个元素是否在同一个集合中 isSameSet/find
- 合并不同的集合 union
使用场景:
在倚天屠龙记中:
- 明教:张无忌、殷天正、杨逍、范遥
- 天鹰教:殷天正、殷野王、殷素素
- 武当:张三丰、张翠山、宋远桥
- 峨眉:周芷若、灭绝师太
问题:
- 张无忌和杨逍是否在同一势力中?
- 天鹰教要合并到明教中,要如何操作?
如果使用 Map:
- isSameSet 很快,只需判断 contains 就可以判读出是否包含
- union 慢,需要循环遍历一个集合加入另一个
如过使用 链表:
- isSameSet 慢,需要循环遍历链表来判断是否包含另一个集合
- union 很快,只需要将一个链表的尾节点指向另一个头结点即可
那能找到或者设计一个 isSameSet 和 union 都很快的结构么?
存在元素 a、b、c、d、e、f,每个元素都在一开始都指向自己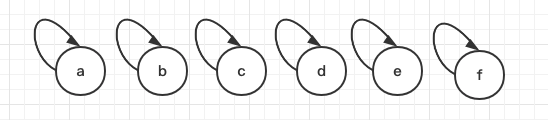
a union b,将 b 的顶端元素指向 a 的顶端元素,将 b 指向 a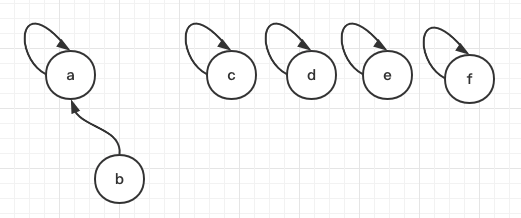
执行 a union c,d union e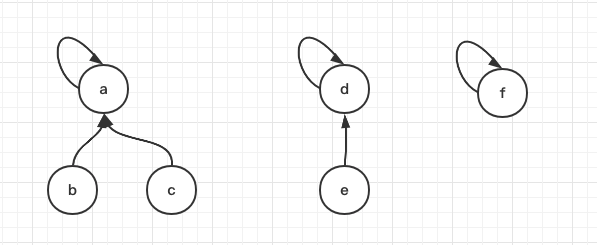
这样如果需要判断 b、c 是在同一集合中,如果 b、c 元素顶端元素相同就说明了在同一集合中,顶端元素就是该集合的代表元素
接着执行 d union f,a union d
代码实现如下:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Stack;
public class UnionFind {
public static class Element<V> {
public V value;
public Element(V value) {
this.value = value;
}
}
public static class UnionFindSet<V> {
// <value, value对应的元素>
public Map<V, Element<V>> elementMap;
// <元素,该元素的父节点>
public Map<Element<V>, Element<V>> fatherMap;
// <代表元素,代表元素下有多少个元素>
public Map<Element<V>, Integer> sizeMap;
public UnionFindSet(List<V> list) {
this.elementMap = new HashMap<>();
this.fatherMap = new HashMap<>();
this.sizeMap = new HashMap<>();
for (V v : list) {
Element<V> element = new Element<>(v);
elementMap.put(v, element);
fatherMap.put(element, element);
sizeMap.put(element, 1);
}
}
public boolean isSameSet(V a, V b) {
if (elementMap.containsKey(a) && elementMap.containsKey(b)) {
return findHead(elementMap.get(a)) == findHead(elementMap.get(b));
}
return false;
}
public void union(V a, V b) {
if (elementMap.containsKey(a) && elementMap.containsKey(b)) {
Element<V> aHead = findHead(elementMap.get(a));
Element<V> bHead = findHead(elementMap.get(b));
if (aHead == bHead) {
Element<V> big = sizeMap.get(aHead) > sizeMap.get(bHead) ? aHead : bHead;
Element<V> small = big == aHead ? bHead : aHead;
fatherMap.put(small, big);
sizeMap.put(big, sizeMap.get(big) + sizeMap.get(small));
sizeMap.remove(small);
}
}
}
private Element<V> findHead(Element<V> e) {
Stack<Element> stack = new Stack<>();
// 找到最顶端的元素
while (fatherMap.get(e) != e) {
e = fatherMap.get(e);
stack.push(e);
}
// 这里将所有的元素都指向了顶端元素,使整个链扁平化
while (!stack.isEmpty()) {
fatherMap.put(stack.pop(), e);
}
return e;
}
}
}
说明:在 findHead 方法中,会将所有的元素都指向了顶端元素,使整个链扁平化。这样做的主要目的是:扁平化后的元素都直接指向了代表元素,下次查询遍历的次数减小到 1。
岛问题的并行方案
思路:利用并查集来并行解决岛问题
存在如下矩阵: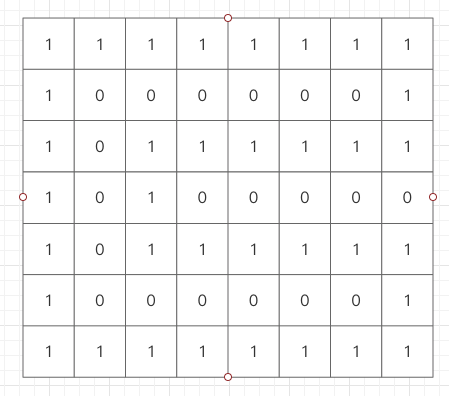
使用 2 个 CPU 的方案,左边 CPU1 处理,右边 CPU2 处理
在两个 CPU 上分别执行 infect 方法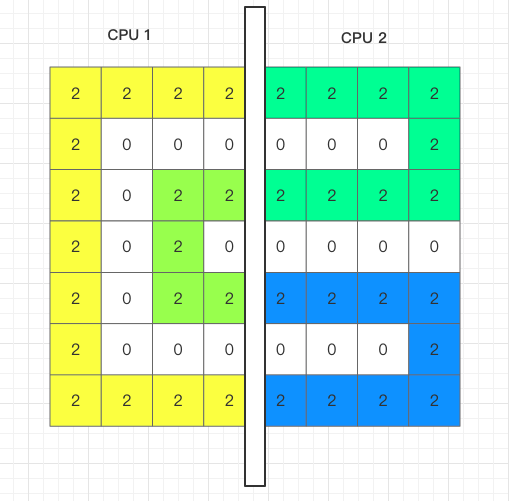
这样,在 CPU1 和 CPU2 上分别就有了两个岛
记录下每个岛开始感染的点以及在 CPU 边界上的点
对于 CPU1 就有了
- 集合A {[0, 0], [0, 3], [6, 3]}
- 集合B {[2, 2], [2, 3], [4, 3]}
对于 CPU2 就有了
- 集合C {[0, 4], [2, 4]}
- 集合D {[4, 4], [6, 4]}
共有 2 + 2 = 4 个岛
得到这些集合后开始对两个CPU的结果进行 union 合并,合并条件为:如果两个CPU边界点都是 2 就合并,并且岛的数量 -1。步骤为:
- [0, 3] [0, 4] 相邻,集合A、C合并为 {A, C},岛数量为 3

- [2, 3] [2, 4] 相邻,集合 {A, C}、B合并为 {A, C, B},岛数量为 2

- [4, 3] [4, 4] 相邻,集合 {A, C, B}、D合并为 {A, C, B, D},岛数量为 1

- [6, 3] [6, 4] 相邻,但是这两个点已经是在同一个集合中,它们的代表点都是 [0,0],最终岛数量为 1

如果是多台电脑多个 CPU就可以将矩阵分成多个,每个结果再进行 union 合并
如:3台电脑,CPU 数量分别为 8、8、4。也可以做数据分割后统计结果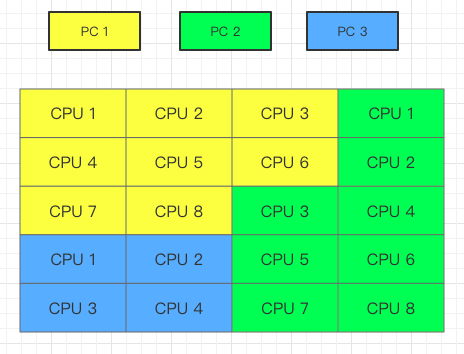

若有收获,就点个赞吧
0 人点赞
