树形 DP
在之前的 二叉树 中就提到过树形 DP 的套路,这本章中会详细分析
树形 DP 套路使用前提:
如果题目求解目标是 S 规则,则求解流程可以定成以每一个节点为头节点的子树在 S 规则下的每一个答案,并且最终答案一定在其中
步骤:
- 以某个节点 X 为头节点的子树中,分析答案有哪些可能性,并且这种分析是以 X 的左子树、X 的右子树和 X 整棵树的角度来考虑可能性的
- 根据 步骤1 的可能性分析,列出所有需要的信息
- 合并 步骤2 的信息,对左树和右树提出同样的要求,并写出信息结构
- 设计递归函数,递归函数是处理以 X 为头节点的情况下的答案。
包括设计递归的 basecase,默认直接得到左树和右树的所有信息,以及把可能性做整合,并且要返回 步骤3 的信息结构这四个小步骤
二叉树节点间的最大距离
从二叉树的 节点a 出发,可以向上或者向下走,但沿途的节点只能经过一次,到达 节点b 时路径上的节点个数叫作 a 到 b 的距离。那么二叉树任何两个节点之间都有距离,求整棵树上的最大距离。
思路:
对于节点 X 来说,最大距离可以分为两种情况:
- X 不参与,最大距离 = X 的左子树的最大距离 或者 右子树最大距离

- X 参与,最大距离 = 左子树高度 + 右子树高度 + 1
import com.example.test.base.datastructrue.tree.Node;public class TreeMaxDistance {static Node a;static Node b;static int getMaxDistance(Node head) {return process(head).maxInstance;}static class ReturnType {int maxInstance;int height;public ReturnType(int maxInstance, int height) {this.maxInstance = maxInstance;this.height = height;}}static ReturnType process(Node cur) {if (cur == null) return new ReturnType(0, 0);ReturnType leftData = process(cur.left);ReturnType rightData = process(cur.right);// x 不参与int instance1 = Math.max(leftData.height, rightData.height);// x 参与int instance2 = leftData.height + rightData.height + 1;int maxInstace = Math.max(instance1, instance2);int height = Math.max(leftData.height, rightData.height);return new ReturnType(maxInstace, height + 1);}public static void main(String[] args) {/*** 1* / \* 2 3* / \* 4 5* /* 6*/Node node1 = new Node(1);Node node2 = new Node(2);Node node3 = new Node(3);Node node4 = new Node(4);Node node5 = new Node(5);Node node6 = new Node(6);node1.left = node2;node1.right = node3;node2.left = node4;node2.right = node5;node4.left = node6;System.out.println(getMaxDistance(node1));}}
结果
5
派对的最大快乐值
员工信息的定义如下:
class Employee{public int happy; // 这名员工可以带来的快乐值List<Employee> subordinates; // 这名员工有哪些直接下级}
公司的每个员工都符合 Employee 类的描述。整个公司的人员结构可以看作是一棵标准的、没有环的多叉树。树的头节点是公司唯一的老板。除老板之外的每个员工都有唯一的直接上级。叶节点是没有任何下属的基层员工(subordinates 列表为空),除基层员工外,每个员工都有一个或多个直接下级。
这个公司现在要办 party,你可以决定哪些员工来,哪些员工不来。但是要遵循如下规则。
- 如果桅个员工来了,那么这个员工的所有直接下级都不能来
- 派对的整体快乐值是所有到场员工快乐值的累加
- 你的目标是让派对的整体快乐值尽量大
给定一棵多叉树的头节点 boss,请返回派对的最大快乐值。
思路:
对于节点 X 来说,快乐值可以分为两种情况:
- X 去 party,最大快乐值 = X 的快乐值 + 子节点不来的情况下孙节点的最大快乐值
- X 不去 party,最大快乐值 = 所有子节点的最大快乐值
import java.util.ArrayList;import java.util.List;public class MaxHappiness {static class Employee {public int happy; // 这名员工可以带来的快乐值List<Employee> subordinates; // 这名员工有哪些直接下级public Employee(int happy) {this.happy = happy;this.subordinates = new ArrayList<>();}}static int getMaxHappiness(Employee boss) {return process(boss).happy;}static Employee process(Employee e) {if (e == null) return new Employee(0);int happy1 = e.happy;List<Employee> list = new ArrayList<>();// 自己参加for (Employee employee : e.subordinates) {happy1 += employee.subordinates.stream().map(sube -> process(sube)).mapToInt(sube -> sube.happy).sum();}// 自己不参加int happy2 = e.subordinates.stream().map(sube -> process(sube)).mapToInt(sube -> sube.happy).sum();Employee res = new Employee(Math.max(happy1, happy2));return res;}public static void main(String[] args) {/*** 10* / | \* 3 20 40* / | / \* 60 3 5 6*/Employee boss = new Employee(10);Employee e11 = new Employee(3);Employee e12 = new Employee(20);Employee e13 = new Employee(40);List<Employee> bossList = new ArrayList<>();bossList.add(e11);bossList.add(e12);bossList.add(e13);boss.subordinates = bossList;Employee e21 = new Employee(60);Employee e22 = new Employee(3);Employee e23 = new Employee(5);Employee e24 = new Employee(6);List<Employee> e11List = new ArrayList<>();e11List.add(e21);List<Employee> e12List = new ArrayList<>();e12List.add(e22);List<Employee> e13List = new ArrayList<>();e13List.add(e23);e13List.add(e24);e11.subordinates = e11List;e12.subordinates = e12List;e13.subordinates = e13List;System.out.println(getMaxHappiness(boss));}}
结果
120
Morris 遍历
一种遍历二叉树的方式,并且时间复杂度 ,额外空间复杂度
,额外空间复杂度 。
。
之前的二叉树的遍历(递归和非递归遍历)额外空间复杂度都是 。递归遍历和非递归遍历在本质上是一样的,递归就是把内存空间作为栈的非递归操作。
Morris 遍历通过利用原树中大量空闲指针的方式,达到节省空间的目的。如果遍历的树禁止做修改,那么就不能使用 Morris 遍历了。
Morris遍历细节
假设来到当前节点 cur ,开始时 cur 来到头节点位置
- 如果
cur没有左孩子,cur向右移动cur = cur.right - 如果
cur有左孩子,找到左子树上最右的节点mostRight:- 如果
mostRight的右指针指向空,让其指向cur,然后cur向左移动cur = cur.left - 如果
mostRight的右指针指向cur,让其指向null,然后cur向右移动cur = cur.right
- 如果
cur为空时遍历停止
具体流程如下,看不清可以放大看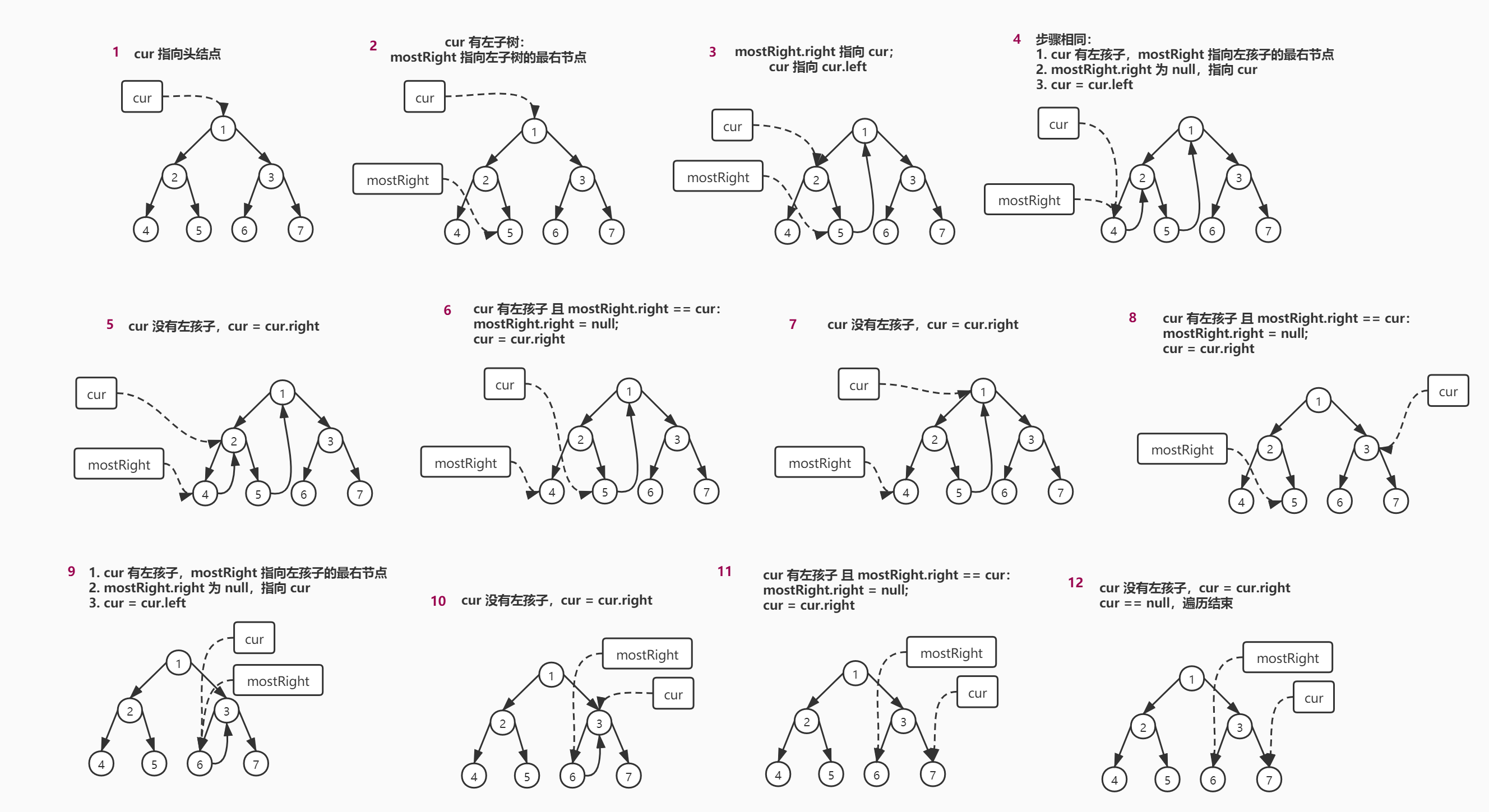
import com.example.test.base.datastructrue.tree.Node;
public class Morris {
static void morris(Node head) {
Node cur = head;
while (cur != null) {
System.out.println(cur.value);
if (cur.left != null) {
// 左子树的最右节点
Node mostRight = cur.left;
while (mostRight.right != null && mostRight.right != cur) {
mostRight = mostRight.right;
}
if (mostRight.right == null) {
mostRight.right = cur;
cur = cur.left;
continue;
} else { // mostRight.right == cur
mostRight.right = null;
}
}
cur = cur.right;
}
}
public static void main(String[] args) {
Node node1 = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
Node node4 = new Node(4);
Node node5 = new Node(5);
Node node6 = new Node(6);
Node node7 = new Node(7);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
morris(node1);
}
}
结果
1
2
4
2
5
1
3
6
3
7
Morris遍历的实质
建立一种机制,对于没有左子树的节点只到达一次,对于有左子树的节点会到达两次
之前的二叉树遍历,如中序遍历:
public static void middleOrder(Node tree) {
// 第一次进入方法
if (tree == null) return;
middleOrder(tree.left); // 第二次进入方法
System.out.print(tree.value + "\t");
middleOrder(tree.right); // 第三次进入方法
}
都会达到同一个方法(节点)三次,Morris 遍历只会到达两次
其他顺序的遍历
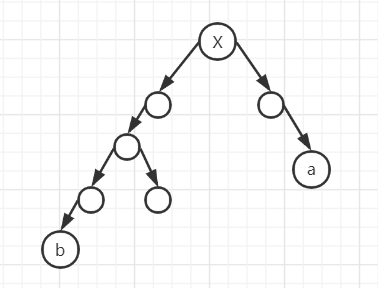
如下图一棵树:
Morris 序:1,2,4,2,5,1,3,6,3,7
前序:1,2,4,5,3,6,7
Morris 序
- 遍历一次的节点直接打印
- 遍历两次的节点只打印第一次遍历
中序:4,2,5,1,6,3,7
Morris 序
- 遍历一次的节点直接打印
- 遍历两次的节点只打印第二次遍历
后序:4,5,2,6,7,3,1
Morris 序改造后序遍历,需要从遍历逻辑上做修改:
- 对于能遍历到两次的节点,第二次遍历到自己时,逆序打印自己左树的右边界
- 上面步骤完成后,逆序打印整棵树的右边界
代码实现:
import com.example.test.base.datastructrue.tree.Node;
public class OtherTraversal {
/**
* 前序遍历,第二次遍历不打印。
* 即:只需要打印
* - 第一次来到 cur 时
* - 左子树为 null 时
*/
static void preOrder(Node head) {
Node cur = head;
while (cur != null) {
if (cur.left != null) {
// 左子树的最右节点
Node mostRight = cur.left;
while (mostRight.right != null && mostRight.right != cur) {
mostRight = mostRight.right;
}
if (mostRight.right == null) {
// 第一次来到 cur
System.out.print(cur.value + "\t");
mostRight.right = cur;
cur = cur.left;
continue;
} else { // mostRight.right == cur
// 第二次来到 cur
mostRight.right = null;
}
} else {
// 左子树为 null
System.out.print(cur.value + "\t");
}
cur = cur.right;
}
System.out.println();
}
/**
* 中序遍历,对于遍历两次的节点只打印第二次遍历。
* 即:只需要打印
* - 第二次来到 cur 时
* - 左子树为 null 时
*/
static void midOrder(Node head) {
Node cur = head;
while (cur != null) {
if (cur.left != null) {
// 左子树的最右节点
Node mostRight = cur.left;
while (mostRight.right != null && mostRight.right != cur) {
mostRight = mostRight.right;
}
if (mostRight.right == null) {
// 第一次来到 cur
mostRight.right = cur;
cur = cur.left;
continue;
} else { // mostRight.right == cur
// 第二次来到 cur
mostRight.right = null;
}
}
System.out.print(cur.value + "\t");
cur = cur.right;
}
System.out.println();
}
/**
* 后序遍历
* 对于能遍历到两次的节点,第二次遍历到自己时,逆序打印自己左树的右边界
* 上面步骤完成后,逆序打印整棵树的右边界
*/
static void postOrder(Node head) {
Node cur = head;
while (cur != null) {
if (cur.left != null) {
// 左子树的最右节点
Node mostRight = cur.left;
while (mostRight.right != null && mostRight.right != cur) {
mostRight = mostRight.right;
}
if (mostRight.right == null) {
// 第一次来到 cur
mostRight.right = cur;
cur = cur.left;
continue;
} else { // mostRight.right == cur
// 第二次来到 cur
mostRight.right = null;
printEdge(cur.left);
}
}
cur = cur.right;
}
printEdge(head);
System.out.println();
}
// 逆序打印 node 的右边界
static void printEdge(Node node) {
Node tail = reverseEdge(node);
Node cur = tail;
while (cur != null) {
System.out.print(cur.value + "\t");
cur = cur.right;
}
reverseEdge(tail);
}
// 反转链表
static Node reverseEdge(Node node) {
Node pre = null;
Node next = null;
while (node != null) {
next = node.right;
node.right = pre;
pre = node;
node = next;
}
return pre;
}
public static void main(String[] args) {
Node node1 = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
Node node4 = new Node(4);
Node node5 = new Node(5);
Node node6 = new Node(6);
Node node7 = new Node(7);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
System.out.println("前序遍历:");
preOrder(node1);
System.out.println("中序遍历:");
midOrder(node1);
System.out.println("后序遍历:");
postOrder(node1);
}
}
结果
前序遍历:
1 2 4 5 3 6 7
中序遍历:
4 2 5 1 6 3 7
后序遍历:
4 5 2 6 7 3 1
Morris 遍历的应用
判断一棵树是否是二叉搜索树:
- 方法一:在 二叉树中 的实现
- 方法二:中序遍历中,值时递增的
可以使用 Morris 遍历改为中序遍历,然后判断值是否是递增即可
static boolean isBST(Node<Integer> head) {
Node<Integer> cur = head;
int preValue = Integer.MIN_VALUE;
while (cur != null) {
if (cur.left != null) {
// 左子树的最右节点
Node mostRight = cur.left;
while (mostRight.right != null && mostRight.right != cur) {
mostRight = mostRight.right;
}
if (mostRight.right == null) {
mostRight.right = cur;
cur = cur.left;
continue;
} else { // mostRight.right == cur
mostRight.right = null;
}
}
if (preValue < cur.value) {
preValue = cur.value;
} else {
return false;
}
cur = cur.right;
}
return true;
}
树形 DP VS Morris 遍历
Morris遍历只会到达同一个节点两次
树形 DP 会到达同一个节点三次
public static ReturnType process(Node<Integer> node) {
if (basecase) {
// 这里看情况返回 null 或者 new ReturnType(……)
return null;
}
// 向左子树要信息
ReturnType leftData = process(node.left); // 第一次
// 向右子树要信息
ReturnType rightData = process(node.right); // 第二次
// 根据 leftData 和 rightData 来获取当前节点信息
// 第三次
return new ReturnType(……);
}
也就是说,如果在分析问题后发现,必须要做第三次信息的强整合才能解决,那么树形 DP 就是最优解。否则 Morris 遍历就是最优解,因为 Morris 遍历是无法做到第三次回到节点的

若有收获,就点个赞吧
0 人点赞
