DOM简介
DOM
DOM 是 JavaScript 操作网页的接口,全称为“文档对象模型”(Document Object Model)
网页元素就是一棵树,其中文字元素也是节点
如何用JS来对这棵HTML树进行增删改查
——使用document对象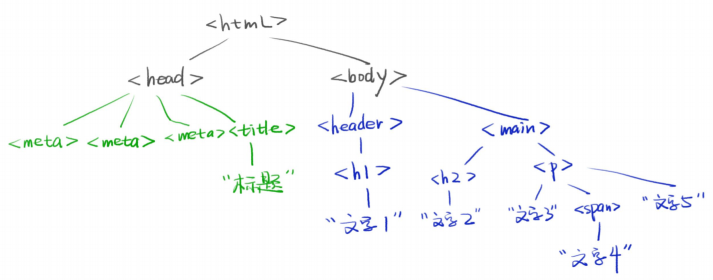
文档对象模型DOM是树形结构,就是倒过来的一棵树。其中document是根,根下面有若干节点,节点下面也有一些节点,每个节点是一个元素,元素有属性。
Node 节点
DOM 的最小组成单位叫做节点(node)。文档的树形结构(DOM 树),就是由各种不同类型的节点组成
节点有很多类型,比如:
- · 文档节点(document):9,对应常量Node.DOCUMENT_NODE
- · 元素节点(element):1,对应常量Node.ELEMENT_NODE
- · 文本节点(text):3,对应常量Node.TEXT_NODE
- · 注释节点(Comment):8,对应常量Node.COMMENT_NODE
我们可以用 document.nodeType`` 来判断一个节点的类型
Node 和 Elements的区别
元素Element是一个小范围的定义,节点Node包括元素Element
- 节点:构成html文档最基本单元,在DOM中所有事物都是节点
- 元素:页面所有标签由开始标签、结束标签以及标签之间的数据构成,元素节点可以包含很多节点
总结:元素是元素节点,是节点中的一种,且元素节点可以包含很多节点,元素就是标签,叫法不同而已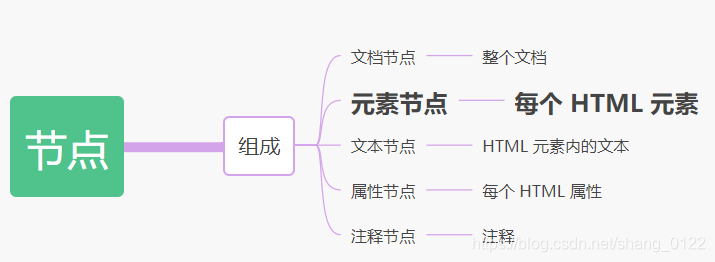
最常用的是标签,而标签也叫做元素

需要注意:
标签与标签之间的空格也是文本节点
节点树和元素树的关系:
节点树:
- 父子关系:
- parentNode, childNode, firstChild, lastChild
- 兄弟关系:
- previousSibling, nextSibling
- 父子关系:
元素树:
- 父子关系:
- parentElement, children, firstElementChild, lastElementChild
- 兄弟关系:
- previousElementSibling, nextElementSibling
- 父子关系:
[
](https://blog.csdn.net/CODING_1/article/details/78202693)
辨析:
childNodes:
返回值包含了元素节点和文本节点
children:
只返回元素节点
parentNode:
常用来获取某个元素的父节点. 把 parentNodes 理解为容器, 在容器中有个子节点
获取元素的API
什么是API
对应的函数里面提供的相应的方法,我们只要用js的语法去调用想要的功能就可以实现
访问任意元素的API
- window.id 或者直接 id
可以直接输入其id名(id是唯一的) IE才用:
- document.getElementByld(‘id名称’)
如果id和window上的全局属性重名时,只有用2才能找到 - document.getElementsByTagName(‘div’)[0]
注意有个’s’,找到所有标签名为 div 的元素,找到的所有div是一个整体数组,想要操作其中一个必须加上下标 - document.getElementsByClassName(‘class名称’)[0]
- document.getElementByld(‘id名称’)
常用:
document.querySelector('') //括号内必须使用字符串形式的选择器(可以是标签选择器),document.querySelectorAll('') 返回选择器(id选择器)或选择器组匹配的第一个HTMLElement对象document.querySelecetorAll('')[i] 或者一个数组对象 ,找不到匹配项,则返回null
- document.querySelector(‘#id名称’)
注意要加 #或者 . 格式同css调用选择器一样 ,这个div可以写得很复杂
如:document.querySelector(‘div>span:nth-child(2)’)
找一个div中的span,并且这个span是div的第二个儿子,CSS怎么写,这里就可以写
- document.querySelectorAll(‘.class名称’)[0]
按照条件找到第一个
访问特定元素的API
- 获取 html 元素
document.documentElement - 获取 head 元素
document.head - 获取 body 元素
document.body - 获取窗口(窗口不是元素)
window
虽然不是一个标签,但是有时候可以获取window然后添加一些全局的事件监听- window.onclick = () =>{console.log(‘点击’)}:点击页面监听
- 获取所有元素
document.all- 第6个falsy值(虽然是falsy值,但功能不受影响依旧能获取元素,只是可以用来区分IE)
[
](https://blog.csdn.net/qq_40282016/article/details/116176176)
div完整的6层原型链
eg. div的原型链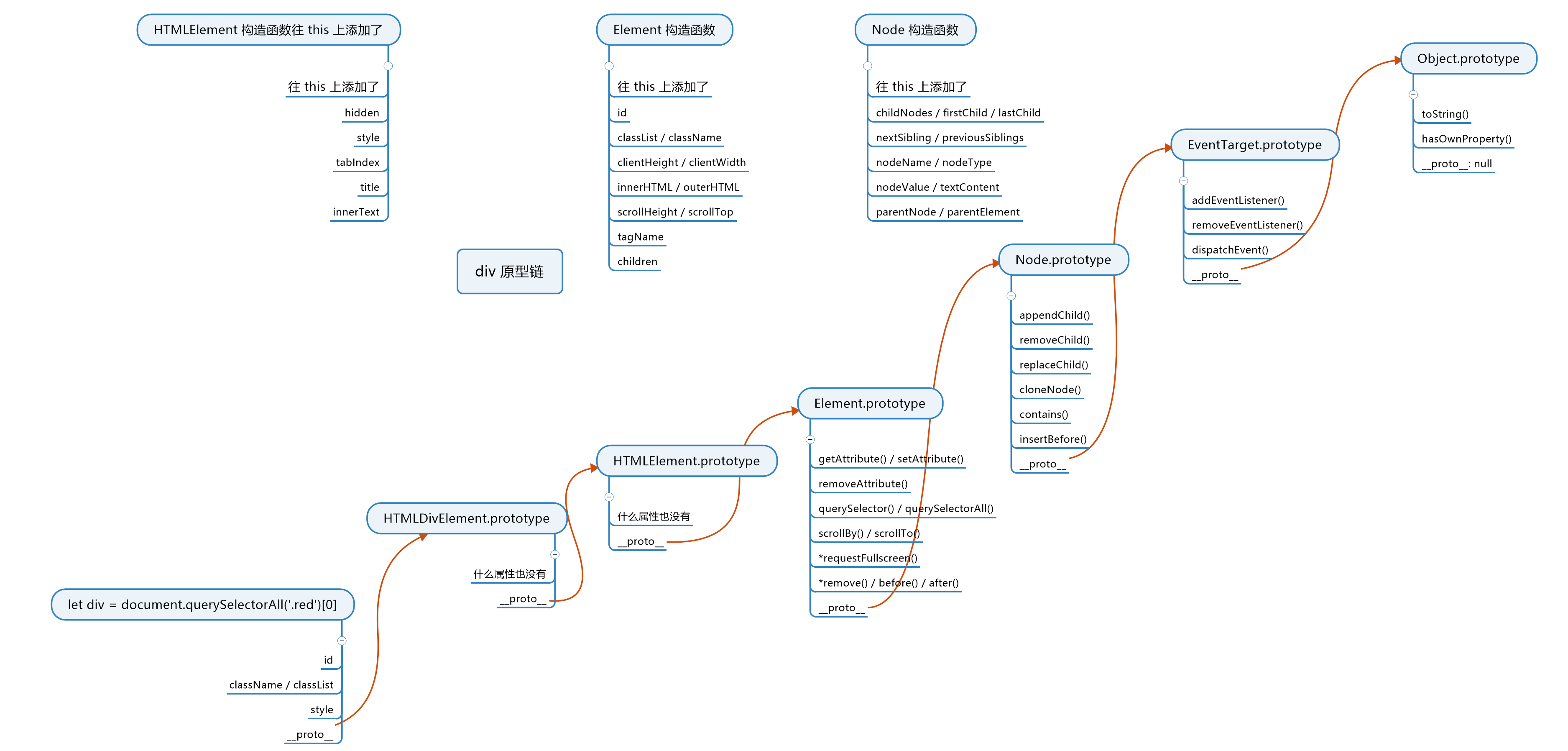
DOM增删改查
增
创建标签/文本节点:
let div1 = document.createElement('div') //创建一个标签节点,括号内放入标签名let text1 = document.createTextNode('你好') //创建一个文本节点
标签里插入文本:
div1.appendChild(text1)div1.innerText = '你好' 或者 div1.textContent = '你好'- 以上两个是不同的构造函数提供的属性,都可以用但不能混着用
注意:
不能用div1.appendChild('你好')
插入到页面:
因为我们创建的标签默认处于JS线程中(即JS内存中),必须把它插入到页面中(即树里),才能生效
document.body.appendChild(div)//或者已在页面中的元素.appendChild(div)
注意:由于树形结构的特点,每个子节点只能有一个父节点,即子节点能被覆盖
删
- 旧方法:
parentNode.removeChild(div1)只能找父亲删掉儿子,且括号内指定儿子——兼容IE - 新方法:
childNode.remove()——不能兼容IE- `若知道childNode可推出parentNode:childNode.parentNode ,反之亦然`- 删除节点只是删除树内的节点,其在JS内存中仍然存在,故**可恢复**- **完全消失:先移除remove()再使其等于null**
empty(node) { //删 除 所有儿子 (利用remove和while循环)const array = [];let x = node.firstChild;while (x) {array.push(dom.remove(node.firstChild));x = node.firstChild //由于childNode元素会实时变化,因为儿子会发生替位关系,故针对每个大儿子删除,使用while循环不添加计数器}return array}
改
改class:
div.className = 'red blue' //整体、全覆盖div.classList.add('red') //不会覆盖,而是续上div.classList.remove('red') //删除
改style:
div.style = 'width: 100px; color: blue;' //整体、全覆盖div.style.width = '200px' //记得写像素单位!
注意:
- 大小写问题(JS不支持有中划线的key,除非包在中括号内用字符串表示,较麻烦):故将中划线后的一个字母改成大写接上 即可,如:
div.style.backgroundColor = 'white'- 特例:改data-*属性:div.dataset.x = ‘frank’ (基本用不到,除非是库开发者)
改事件处理函数:
div.onclick 默认为 null
- 默认点击 div 不会有任何事情发生
- 但是如果你把 div.onclick 改为一个函数 fn
- 那么点击 div 的时候,浏览器就会调用这个函数
- 并且是这样调用的
fn.call(div,event):前面是触发元素的引用,后面接事件的所有详细信息- div 会被当做 this
- event 则包含了点击事件的所有信息,是浏览器用call传进来的,如坐标(在哪点的)
div.addEventListener
- 是上一个的升级版,onclick只能写一个函数,这个能写无数个(后面补充)
[
](https://blog.csdn.net/qq_40282016/article/details/116176176)
改内容:
改文本内容:
div.innerText = 'xxx'——IE支持div.textContent = 'xxx'—— Firefox和Chrome支持
两个几乎没区别,大部分浏览器现在均支持改 HTML 内容:
div.innerHTML = '<strong>重要内容</strong>'
如果里面的字符太多或者太复杂,容易把浏览器卡住,注意HTML全部大写改标签:
div.innerHTML = '' //先清空div.appendChild(div2)//再加内容
改父节点:
- newParent.appendChild(div)
- 会从原来的地方消失,并出现在新的父节点
查
读标准属性
直接使用对象的点语法来读:
obj[key], obj.key- bug注意:a标签的href属性用a.href 和 a.getAttribute(‘href’)得到的值不一样
div.classList / a.href :有些时候浏览器会默认添加一些前缀div.getAttribute(‘class’) / a.getAttribute(‘href’) :只会是href本身的值
- bug注意:a标签的href属性用a.href 和 a.getAttribute(‘href’)得到的值不一样
查爸爸
node.parentNode或者node.parentElement查爷爷
node.parentNode.parentNode查子代
node.childNodes或者node.children(优先使用children,不会计算文本节点如空格)- 当子代变化时,两者方法获取到的元素都会实时变化
- 除了使用
document.querySelectorAll('标签名'),不会实时变化
查兄弟姐妹
node.parentNode.childNodes后面还需要遍历数组排除自己和排除空格文本节点node.parentNode.children后面还需要遍历数组排除自己
查特定对象:
查看第一个儿子
node.children[0]
node.firstChild查看最后一个儿子
node.lastChild查看上一个哥哥/姐姐
node.previousSibling查看下一个弟弟/妹妹
node.nextSibling注意:以上查询时会有node和Element,两个结果可能不同,Element排除了空格文本节点
- 调用Element查询:举例:node.previousElementSibing
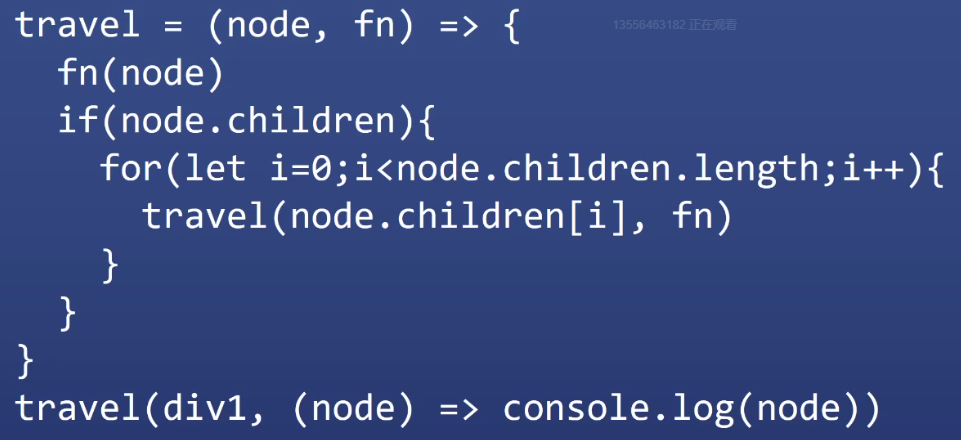
遍历一个 div 里面的所有元素
- 原理就和数据结构中遍历一棵树一样,因为DOM就是一棵树

若有收获,就点个赞吧
0 人点赞
