:::info
💡 根据 遗忘曲线:如果没有记录和回顾,6天后便会忘记75%的内容
读书笔记正是帮助你记录和回顾的工具,不必拘泥于形式,其核心是:记录、翻看、思考
:::
| 书名 | Maching Learning Design Patterns |
|---|---|
| 作者 | Valliappa Lakshmanan,Sara Robinson & Michael Munn |
| 状态 | 阅读中 |
| 简介 | Solutions to Common Challenges in Data Preparation, Model Building, and MLOps(Maching Learning Operations) |
思维导图
用思维导图,结构化记录本书的核心观点。

Common Challenges in Maching Learning
Data Quality
Maching Learning models are only as reliable as the data used to train them.
Maching Learning models are often referred to as “garbage in, garbage out”
reproducibility
读完该书后,受益的核心观点与说明…
Data Drift
Data Drift refers to the challenge of ensuring your machine learning models stay relevant, and that model predictions are an accurate reflection of the environment in which they’re being used.
- News Article Headlines Classification———— Data Updating & Model Updating
classify news article headlines into categories like “politics”, “business” and “technology”. If you train and evaluate your model on historical news articles from the 20th century, it likely won’t perform as well on current data.
To solve for these drift above on, it’s important to continually update your training dataset, retrain your model, and modify the weight your model assigns to particular groups of input data.
- Predict Likelihood Of A Storm In A Given Area ————Data Feature Available & Updating
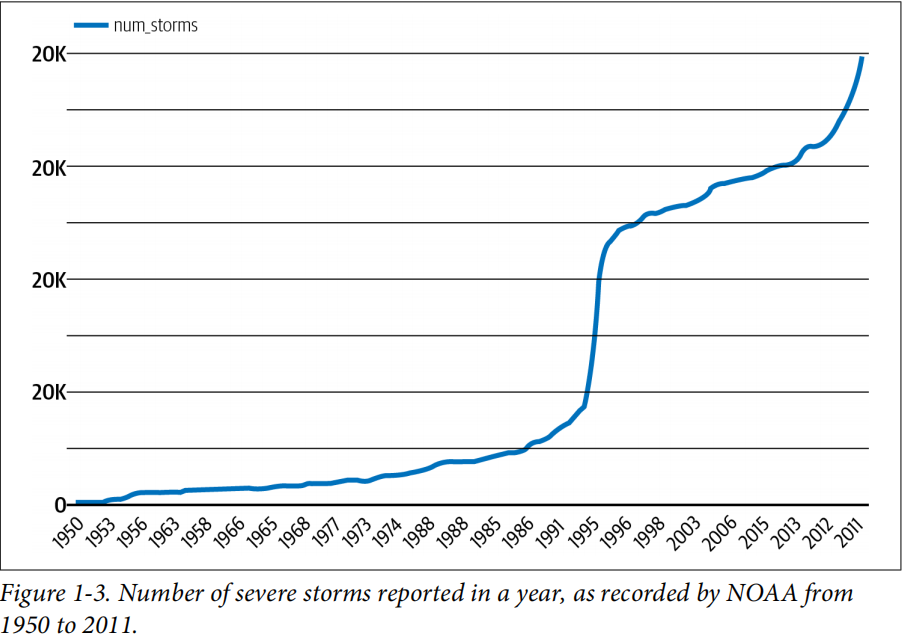
a less-obvious example of drift. The NOAA(美国气象) dataset of severe storms in BigQuery. If we were training a model to predict the likelihood of a storm in a given area, we would need to take into account the way weather reporting has changed over time. From this trend, we can see that training a model on data before 2000 to generate predictions on storms today would lead to inaccurate predictions.
another factors would effect the data. For instance, the technology for observing storms has improved over time, such as the introduction of weather radars in 1990s. So the newer data contains more information about data feature, and a data feature available in today’s data may not been observed(available) in 1950s.
Section , “Design Pattern 23: Bridged Schema” on page 266 provides a way to handle data‐
sets in which the availability of features improves over time.
Scale(缩放)
The challenge of scaling is present throughout many stages of a typical maching learning workflow. You’ll likely encounter scaling challenges in data collection and preprocessing, training and serving.
It is often the job of data engineers to build out data pipelines that can scale to handle datasets with millions of rows.
The type and size will effect the infrastructure(like GPUs) for your epecific training job. Image models, for instance, typically require much more training infrastructure than models trained entirely on tabular(表格的) data.
Multiple Objectives(组织内关与模型的多方需求)
Many team across an organization will make use of the model in some way. Inevitably, these teams may have different ideas of what defines a successful model.
When defining the goals for your model, it’s important to consider the needs of different teams across an organization, and how each team’s needs relate back to the model.Find areas of compromise(妥协) in order to optimally balance these multiple objectives.
书摘

若有收获,就点个赞吧
0 人点赞
