Multi-Similarity Loss with General Pair Weighting for Deep Metric Learning
引言
作者首先介绍了部分DML的概念以及其作用,而后对于目前学界的部分进展进行了总结。
作者认为目前的DML算法都是在样本对的基础上,在嵌入空间中计算样本对之间的余弦相似度,这也就是所谓的“基于对“的DML。作者认为这种方法普遍存在一些问题,主要是多项式级别的样本对个数是冗余的、携带较少信息的,这也就将导致DML模型在随机采样时会受限制于这些冗余的样本对,这将导致收敛速度降低与性能退化。
作者认为,现在的诸多DML算法即使出发点不同,具体实现的思路也不同,但是都是向着一个共同的目标来做的,那就是尽可能采样那些有信息量的数据对,但是识别携带大量信息的数据对是很困难的毕竟负样本对的数量会随着数据集的扩大而平方增长。
因此,作者试图去推导出一种一般数据对加权的公式,主要包括加权模式和限制条件,也就是文中的GPW框架。作者发现这些权重的计算主要由相似度决定,包括自相似度和相对相似度,后者主要由其他数据对决定。并且现有的绝大多数方法仅仅考量了部分相似度,因此作者结合GPW框架,将所有的相似度均纳入考量范畴,提出了多相似度的损失函数。
General Pair Weighting(GPW)
首先进行一些约定:
 是一个实例的向量,因此可以获得实例矩阵
是一个实例的向量,因此可以获得实例矩阵 ,以及分别对应
,以及分别对应个样本的一个标签向量
。实例
将投影到一个
维度的空间中,投影的函数为
 ,这里
,这里是一个参数由
表示的神经网络。因此,可以进一步定义两个样本间的相似度为
%2Cf(xj%3B%5Ctheta)%3E#card=math&code=S%7Bi%2Cj%7D%3A%3D%3Cf%28xi%3B%5Ctheta%29%2Cf%28x_j%3B%5Ctheta%29%3E&id=g4gl9),这里的。这将产生一个
的相似度矩阵,其中
#card=math&code=%28i%2Cj%29&id=o8lQX)位置的元素就是。
当给出一个基于数据对的损失函数时可以被表示成
和
的函数:
#card=math&code=L%28S%2Cy%29&id=GlpeJ)。可以分别求出其在第
轮迭代过程中对于
的偏导:
%7D%7B%5Cpartial%20%5Ctheta%7D%7Ct%3D%5Cfrac%7B%5Cpartial%20L(S%2Cy)%7D%7B%5Cpartial%20S%7D%7C_t%5Cfrac%7B%5Cpartial%20S%7D%7B%5Cpartial%20%5Ctheta%7D%7C_t%5C%5C%3D%5Csum%7Bi%3D1%7D%5Em%5Csum%7Bj%3D1%7D%5Em%20%5Cfrac%7B%5Cpartial%20L(S%2Cy)%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7Ct%5Cfrac%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7B%5Cpartial%20%5Ctheta%7D%20%5Ctag%7B1%7D%0A#card=math&code=%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20%5Ctheta%7D%7Ct%3D%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S%7D%7C_t%5Cfrac%7B%5Cpartial%20S%7D%7B%5Cpartial%20%5Ctheta%7D%7C_t%5C%5C%3D%5Csum%7Bi%3D1%7D%5Em%5Csum%7Bj%3D1%7D%5Em%20%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7Ct%5Cfrac%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7B%5Cpartial%20%5Ctheta%7D%20%5Ctag%7B1%7D%0A&id=hTVJL)
通过深度度量学习计算上述等式1即可优化模型的参数。事实上,等式1可以被转化成一个考虑数据对权重的新的形式
:
%3D%5Csum%7Bi%3D1%7D%5Em%5Csum%7Bj%3D1%7D%5Em%5Cfrac%7B%5Cpartial%20L(S%2Cy)%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7C_t%20S%7Bi%2Cj%7D%20%5Ctag%7B2%7D%0A#card=math&code=F%28S%2Cy%29%3D%5Csum%7Bi%3D1%7D%5Em%5Csum%7Bj%3D1%7D%5Em%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7C_t%20S%7Bi%2Cj%7D%20%5Ctag%7B2%7D%0A&id=bZjyv)
在第轮迭代过程中对于
的梯度就是等式1,其中
%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7C_t#card=math&code=%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7C_t&id=yZEHS)是一个常数。
因为深度度量学习的中心思想就是让正例对更近,让反例对更远。对于一个基于对的损失函数而言可以根据正负样本对于进一步改写以分离正负样本的权重:
%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7C_tS%7Bi%2Cj%7D%2B%5Csum%7By_j%3Dy_i%7D%20%5Em%20%5Cfrac%7B%5Cpartial%20L(S%2Cy)%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7CtS%7Bi%2Cj%7D)%5C%5C%3D%5Csum%7Bi%3D1%7D%5Em(%5Csum%7Byj%5Cneq%20y_i%7D%5Em%20%5Comega%7Bij%7DS%7Bij%7D-%5Csum%7Byj%3D%20y_i%7D%5Em%20%5Comega%7Bij%7DS%7Bij%7D)%20%5Ctag%7B3%7D%0A#card=math&code=F%3D%5Csum%7Bi%3D1%7D%5Em%28%5Csum%7By_j%5Cneq%20y_i%7D%5Em%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7CtS%7Bi%2Cj%7D%2B%5Csum%7By_j%3Dy_i%7D%20%5Em%20%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7CtS%7Bi%2Cj%7D%29%5C%5C%3D%5Csum%7Bi%3D1%7D%5Em%28%5Csum%7Byj%5Cneq%20y_i%7D%5Em%20%5Comega%7Bij%7DS%7Bij%7D-%5Csum%7Byj%3D%20y_i%7D%5Em%20%5Comega%7Bij%7DS_%7Bij%7D%29%20%5Ctag%7B3%7D%0A&id=hCm1G)
其中%7D%7B%5Cpartial%20S%7Bi%2Cj%7D%7D%7C_t%7C#card=math&code=%5Comega%7Bij%7D%3D%7C%5Cfrac%7B%5Cpartial%20L%28S%2Cy%29%7D%7B%5Cpartial%20S_%7Bi%2Cj%7D%7D%7C_t%7C&id=a7QlP)。
等式3中的可以被看作是针对数据对
#card=math&code=%28x_i%2Cx_j%29&id=Ahag4)的权重,这将等式1中的计算数据对的损失函数更加泛化为计算数据对的权重。
在这一框架下,Contrastive loss等损失函数都可以被改写成这样的形式,即针对负样本对与正样本对分别加权的形式。
Contrastive loss 与 Triplet loss均是针对正负样本使用相同的权值进行加权。
在Lifted Structure Loss中,在一整个批次上的损失函数如下:
其中是固定的margin
在等式4中,当一个返回的Hinge Loss数值非0时,针对数据对
的权重
可以通过
对于
的偏导获得:
等式5中可以看出正样本对的全职取决于相对相似度,这是由通过将其与同一个锚点的剩余的正样本相比较获得的:一个正样本对的同类正样本的相似度越高,其分配获得的权值越大;负样本亦是如此。
在Binomial Deviancce Loss中,使用了Softplus函数来代替Hinge loss:
%7D%5D%5C%7D%5Ctag%7B6%7D%0A#card=math&code=L%7B%5Ctext%7Bbinomial%7D%7D%3D%5Csum%7Bi%3D1%7D%5Em%20%5C%7B%5Cfrac%7B1%7D%7BPi%7D%5Csum%7Byj%3Dy_i%7D%5Clog%20%5B1%2Be%5E%7B%5Calpha%20%28%5Clambda%20-S%7Bij%7D%7D%5D%2B%5C%5C%5Cfrac%7B1%7D%7BNi%7D%5Csum%7Byj%5Cneq%20y_i%7D%5Clog%20%5B1%2Be%5E%7B%5Cbeta%28S%7Bij%7D-%5Clambda%29%7D%5D%5C%7D%5Ctag%7B6%7D%0A&id=p4w4B)
这里和
分别指代锚点
的正样本对与负样本对的数量。
均是超参数。针对
的权重
通过由损失函数对
求偏导获得:
%20%7D%7D%7B1%2Be%5E%7B%5Calpha%20(%5Clambda-S%7Bij%7D)%20%7D%7D%2C%5Cquad%20%5Cquad%20y_j%3Dy_i%20%5C%5C%5Comega%20%5E-%7Bij%7D%3D%5Cfrac%7B1%7D%7BNi%7D%5Cfrac%7B%5Cbeta%20e%5E%7B%5Cbeta%20(S%7Bij%7D-%5Clambda)%20%7D%7D%7B1%2Be%5E%7B%5Cbeta%20%20(S%7Bij%7D-%5Clambda)%20%7D%7D%2C%5Cquad%20%5Cquad%20y_j%5Cneq%20y_i%20%5Ctag%7B7%7D%0A#card=math&code=%5Comega%20%5E%2B%7Bij%7D%3D%5Cfrac%7B1%7D%7BPi%7D%5Cfrac%7B%5Calpha%20e%5E%7B%5Calpha%20%28%5Clambda-S%7Bij%7D%29%20%7D%7D%7B1%2Be%5E%7B%5Calpha%20%28%5Clambda-S%7Bij%7D%29%20%7D%7D%2C%5Cquad%20%5Cquad%20y_j%3Dy_i%20%5C%5C%5Comega%20%5E-%7Bij%7D%3D%5Cfrac%7B1%7D%7BNi%7D%5Cfrac%7B%5Cbeta%20e%5E%7B%5Cbeta%20%28S%7Bij%7D-%5Clambda%29%20%7D%7D%7B1%2Be%5E%7B%5Cbeta%20%20%28S_%7Bij%7D-%5Clambda%29%20%7D%7D%2C%5Cquad%20%5Cquad%20y_j%5Cneq%20y_i%20%5Ctag%7B7%7D%0A&id=byFOL)
这里可以看出binomial deviance loss是一种soft版本的contrastive loss,即加权版本的,会对反例对中有更高相似性的赋予更大的权重去优化。
Multi-Similarity Loss
Multi-Similarity
作者首先介绍了三种相似度的衡量方式,分别为Self-similarity 自相似度(S),Negative relative similarity负相对相似度(N),Positive relative similarity正相对相似度(P)。作者认为任何一种花里胡哨的基于数据对的方法都倾向于学习那些更有信息的数据,这可以通过GPW框架来衡量。
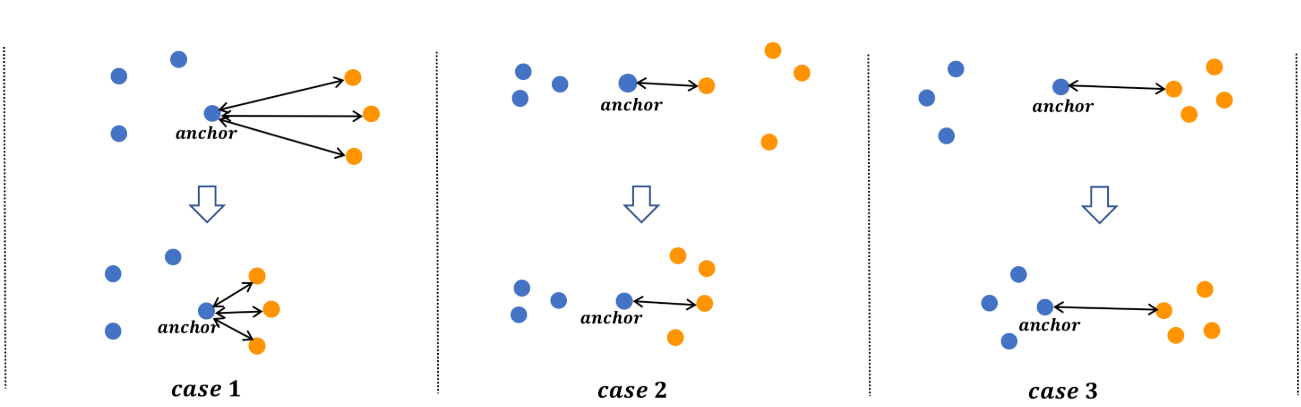
图1
自相似度是根据一个数据对本身计算获得的,是最重要的一种相似度。一个有着较大的余弦相似度的负样本对意味着很难将这一对数据中的不同的类别的两个样本相分离,这也就是我们所说的困难负样本对,当然对于模型学习如何分类也具有更大的信息价值。Contrastive loss 和 binomial deviance loss就是从这一点出发的。从图2中的case1可以看出,三个负样本对的权重当它们相聚更近时会增加。但很明显的,自相似度很难去完全描述一个嵌入空间中的样本分布,并且其他数据对的相关关系也会对相似度衡量带来影响。因此需要考虑同一个锚点的其他数据对的影响,这就需要定义相对相似度。
负相对相似度是通过计算相邻的负样本对的关系获得的。如图2中的case2,随着更多相邻的橙色样本(这里代表负样本)的靠近,这将导致这些相邻的负样本的和该锚点的自相似度会增大,这就减少了相对相似度,尽管该样本对本身的自相似度没有发生改变。Lifted structure loss就是基于这种考量的。
正相对相似度是通过理算同一个锚点的正样本对的关系来获得的。如图2中的case3所描述,当正样本距离锚点更近的时候,当前点对的权重也就会降低。Triplet loss就是基于这种想法的。

基于定义的三个相似性分析了许多现有的基于对的损失函数,并在表 1 中对它们进行了比较。可以发现,Lifted structure loss仅考虑负相对相似性,通过与负相邻对进行权重比较,当前样本对的权重不会发生改变。这也可以通过等式5看出,因为权重仅仅依赖于。显然,这样的相关样本(正或负)通常包含有意义的信息,对学习判别特征非常重要,但是是随机分布的,这可能会大大降低模型能力。虽然之前已经探索了基于每个个体相似性的加权或采样方法,但作者认为现有的方法都没有为充分利用所有三个相似性来分配权重。
因此,作者结合三种相似度提出了Multi-Similarity Loss。
Multi-Similarity Loss
作者认为仅仅依靠自相似度是不足以衡量样本对的信息丰度的,因此必须结合相对相似性来考量。作者因此集合前文的三种相似度提出了自己的MS Loss。MS Loss主要包括两个迭代的步骤(挖掘和权重分配):
- 带有大量信息的样本对首先通过相似度P,也就是正相对相似度来被采样
- 被选取的样本对使用相似度S与N(也就是自相似度和负相对相似度)一起来进行权重分配。
样本对挖掘
首先通过计算正相对相似度P来选择有信息量的样本对,因为这会衡量同一个锚点的负样本对的相对相似度:一个负样本对与最困难的正样本对(就是最低相似度的)相比较,一个正样本对和一个最难的负样本对比较(就是最大相似度的)。
假设是一个锚点,一个负样本对
将会被选择的条件是:
这里是一个给定的margin。
相似的,正样本对将会被选择的条件是:
针对一个锚点,我们制定它被选择的的正、负样本对集合分别为
和
。
这里的样本挖掘是由LMNN激发的,其中算法鼓励邻近的正样本点和锚点拥有相同的标签,符合不等式8的负样本被LMNN认为是“入侵者”。
样本对权重分配
在通过上文的挖掘机制选择的样本,通过相似度S与N来进行赋予权重。赋予权重的算法是收到Binomial deviance loss(使用相似度S)和lifted structure loss(使用相似度N)启发的。当选择一个负样本对的权重
的计算方式为:
%7D%2B%5Csum%7Bk%5Cin%20%20N_i%7De%5E%7B%5Cbeta(S%7Bik%7D-S%7Bij%7D)%7D%7D%5C%5C%3D%5Cfrac%7Be%5E%7B%5Cbeta%20(S%7Bij%7D-%5Clambda)%7D%7D%7B1%2B%5Csum%7Bk%5Cin%20%20N_i%7De%5E%7B%5Cbeta(S%7Bik%7D-%5Clambda)%7D%7D%20%5Ctag%7B10%7D%0A#card=math&code=w%5E-%7Bij%7D%3D%5Cfrac%7B1%7D%7Be%5E%7B%5Cbeta%20%28%5Clambda-S%7Bij%7D%29%7D%2B%5Csum%7Bk%5Cin%20%20N_i%7De%5E%7B%5Cbeta%28S%7Bik%7D-S%7Bij%7D%29%7D%7D%5C%5C%3D%5Cfrac%7Be%5E%7B%5Cbeta%20%28S%7Bij%7D-%5Clambda%29%7D%7D%7B1%2B%5Csum%7Bk%5Cin%20%20N_i%7De%5E%7B%5Cbeta%28S%7Bik%7D-%5Clambda%29%7D%7D%20%5Ctag%7B10%7D%0A&id=tcCDm)
同样的针对正样本对的权重
可以被计算为:
%7D%2B%5Csum%7Bk%5Cin%20%20P_i%7De%5E%7B%5Calpha(S%7Bik%7D-S%7Bij%7D)%7D%7D%20%5Ctag%7B11%7D%0A#card=math&code=%5Comega%5E%2B%7Bij%7D%3D%5Cfrac%7B1%7D%7Be%5E%7B%5Calpha%28%5Clambda-S%7Bij%7D%29%7D%2B%5Csum%7Bk%5Cin%20%20Pi%7De%5E%7B%5Calpha%28S%7Bik%7D-S_%7Bij%7D%29%7D%7D%20%5Ctag%7B11%7D%0A&id=Nrz3b)
其中的均是在Binomial deviance loss中的超参数。
在等式10中,负样本的权重是通过计算自相似度S:%7D#card=math&code=e%5E%7B%5Cbeta%20%28%5Clambda-S%7Bij%7D%29%7D&id=NlADx)和负相对相似度N:%7D#card=math&code=%5Csum%7Bk%5Cin%20%20Ni%7De%5E%7B%5Cbeta%28S%7Bik%7D-S_%7Bij%7D%29%7D&id=c4Xhi)来整体赋予的。正样本是同理。
最终,将这二者集成,会得到最终的MS Loss损失函数:
%7D%5D%5C%5C%2B%5Cfrac%7B1%7D%7B%5Cbeta%7D%5B1%2B%5Csum%7Bk%5Cin%20%20N_i%7De%5E%7B%5Cbeta(S%7Bik%7D-%5Clambda)%7D%5D%5C%7D%20%5Ctag%7B12%7D%0A#card=math&code=L%7BMS%7D%3D%5Cfrac%7B1%7D%7Bm%7D%5Csum%7Bi%3D1%7D%5Em%5C%7B%5Cfrac%7B1%7D%7B%5Calpha%7D%5Clog%5B1%2B%5Csum%7Bk%5Cin%20P_i%7De%5E%7B-%5Calpha%28S%7Bij%7D-%5Clambda%29%7D%5D%5C%5C%2B%5Cfrac%7B1%7D%7B%5Cbeta%7D%5B1%2B%5Csum%7Bk%5Cin%20%20N_i%7De%5E%7B%5Cbeta%28S%7Bik%7D-%5Clambda%29%7D%5D%5C%7D%20%5Ctag%7B12%7D%0A&id=ExK24)
使用梯度优化可以优化MS Loss损失函数。

若有收获,就点个赞吧
0 人点赞
