在本文中作者主要关注的是学习一个简单的、使用点乘的相似度函数,因为作者认为这不但可以节省计算量,也可以很适合图像检索的算法。前人在此方面的研究往往存在一个问题:在大规模嵌入的情况下容易过拟合。
为解决这一问题作者提出Boosting Independent Embeddings Robustly (BIER)模型。其主旨为将CNN中的嵌入层分割为几个互不重合的组,每个组有一个独立的、基于共享特征表示的度量学习网络。而这样的方法的正确率取决于这些独立的学习器的正确率以及它们之间的关系。理想的情况为每个学习器都具有较高的正确率且相互独立,因此这些学习器在测试集上相互独立的运作。
作者认为,在一个统一的特征表现上学习若干学习器是无效的,因为这些学习器学习的都是高度相关的嵌入特征。为此,作者的解决办法是使用一种类似在线梯度提升技术,每个学习器都将学习与前一个学习器不同的样本。同样的为了降低学习器彼此之间的相关性,作者为嵌入矩阵设计出了一种新的初始化方法,这种方法来源于旨在降低组件相关系数的优化方法。
为了提升效果,作者采用了一些技巧,包括:
- 在训练目标中整合权重初始化方法和辅助损失函数(增加正确率,减少训练时间,降低相关系数)
- 使用新的对抗损失函数学习在嵌入的对中学习对抗性回归(旨在学习嵌入之间的非线性变换来增加嵌入之间的相似度)
- 在嵌入和回归之间插入梯度回溯层(在反向传播时改变梯度的符号,在正向传播中起到恒等函数的作用)
Related Work
Metric Learning
在相关工作回顾部分,作者回顾了度量学习的内容,重点主要在基于Boosting的度量学习和基于CNN的度量学习。
在基于boosting的部分,弱学习器主要是学习一个度量,并最后集成为一个半正定矩阵。Kedem等人使用梯度提升树来进行度量学习,主要是学习一个非线性映射#card=math&code=f%28%5Ccdot%29&id=fi1ad)和一些回归树的集成,通过最小化LMNN损失和梯度提升框架。而作者等人提出的是在线的boosting方法,他们的弱学习器是基于共享CNN特征表现得全连接层,同时使用辅助损失函数来帮助度量集成的多样性。
在基于CNN的度量学习部分,基于CNN的方法学习一个非线性变换,将一个输入图片从k维转换到h维: 。这种映射可以通过在大规模识别的任务来预训练,而后在度量学习的数据集上细调。为了完成这种到d维向量空间的映射,需要在CNN的特征提取之后增加一个线性嵌入层:
。这种映射可以通过在大规模识别的任务来预训练,而后在度量学习的数据集上细调。为了完成这种到d维向量空间的映射,需要在CNN的特征提取之后增加一个线性嵌入层: 。因此度量学习的卷积神经网络学习一个距离函数:
。因此度量学习的卷积神经网络学习一个距离函数:%5E2%3D(%5Cphi(x)-%5Cphi(y))%5ETWW%5ET(%5Cphi(x)-%5Cphi(y)#card=math&code=d%28x%2Cy%29%5E2%3D%28%5Cphi%28x%29-%5Cphi%28y%29%29%5ETWW%5ET%28%5Cphi%28x%29-%5Cphi%28y%29&id=SCZEB),等价于
-%5Cphi(y))%5ETM(%5Cphi(x)-%5Cphi(y)#card=math&code=%28%5Cphi%28x%29-%5Cphi%28y%29%29%5ETM%28%5Cphi%28x%29-%5Cphi%28y%29&id=YcP29)。为了联合学习CNN和嵌入的参数,需要设计在图片样本对、三元组或者更多的组合上的特别的损失函数,比如Contrastive Loss。其他的方法采用了LMNN的方式和样本三元组,包括一个正样本对和一个负样本对。损失函数鼓励正样本对和负样本对的距离之间的margin。因此,与负图像对相比,正图像对在特征空间中彼此靠近彼此映射。
Boosting for CNNs
原本的Adaboost优化一个指数损失函数,后人在其基础上改进,可以优化任何可导的损失函数。而在Gradient Boosting中,连续的学习器被训练地和损失函数的负梯度拥有高度相关性。实时的方法一次训练一个样本并更新模型,离线的方法需要获取全部的数据集。
而在CNN的背景下,这些方法使用较少。很多方法仅仅是把CNN当作一个固定的特征提取器。而作者的方法是将事实的boosting整合进训练CNN的过程中。作者提出的方法在这方面有以下的特点:
- 相较于训练多个CNN的方法,作者仅仅训练一个CNN来训练在线的Boosting,并且类似Dropout共享用一个特征表示且不引入任何额外参数
- 使用包括线性分类器在内的多个神经元构成一个弱分类器
- 通过损失函数的负梯度对于下一个弱分类器的训练集重新赋予权值
初始化方法
有些方法使用随机的权重矩阵进行初始化。其它的一些方法逐层地贪婪地初始化:通过应用无监督特征学习,比如RBM,来寻找一个最小化重建错误的、学习了数据的整体模型的矩阵。作者的方法也是对于单个层无监督的预训练。,并且试图最小化特征组之间的相关系数。
对抗性损失函数
生成对抗网络主要有两个神经网络组成:一个生成器和一个鉴别器。鉴别器通过最小化损失函数来鉴别生成器生成的图片,生成器则试图去生成可以欺骗验证器的图片,这又是通最大化那个损失函数来实现。作者仅仅使用一个生成器来使用非线性的神经网络来将特征从一个学习器映射到另一个学习器上,并通过优化生成器来最大化嵌入之间的相似度。
Boosting a Metric Network
前任在CNN学习的过程中中没有使用Softmax损失函数,而是在最后一个隐层之后使用一个包含嵌入矩阵 的线性层来将隐层的
的线性层来将隐层的维转化为最终的
维嵌入。同时在训练的时候采用图像数据对或者三元组的方法。
而在作者的BIER中,作者学习的不是距离度量而是一个相似性度量:
%7D)%2Cf(x%5E%7B(2)%7D))%3D%5Cfrac%7Bf(x%5E%7B(1)%7D)%5ETf(x%5E%7B(2)%7D)%7D%7B%7C%7Cf(x%5E%7B(1)%7D)%7C%7C%5Ccdot%20%7C%7Cf(x%5E%7B(2)%7D)%7C%7C%7D%20%5Ctag%7B1%7D%0A#card=math&code=s%28f%28x%5E%7B%281%29%7D%29%2Cf%28x%5E%7B%282%29%7D%29%29%3D%5Cfrac%7Bf%28x%5E%7B%281%29%7D%29%5ETf%28x%5E%7B%282%29%7D%29%7D%7B%7C%7Cf%28x%5E%7B%281%29%7D%29%7C%7C%5Ccdot%20%7C%7Cf%28x%5E%7B%282%29%7D%29%7C%7C%7D%20%5Ctag%7B1%7D%0A&id=VQ3ff)
这个余弦相似度函数的优点为其取值范围是。
在BIER中,和LFSE一样都是一次抽取一个批次的图像,前向传播并在最后的loss层抽取数据对或者三元组,而后再反向传播。这样不用同时保留多个网络的架构,节省内存且计算更快。
作者一共考量了三种损失函数:
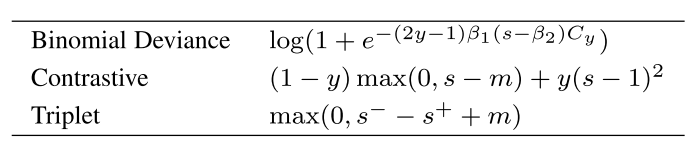
其中,%7D%2Cf(x%5E%7B(2)%7D))#card=math&code=s%3Ds%28f%28x%5E%7B%281%29%7D%2Cf%28x%5E%7B%282%29%7D%29%29&id=J47s1)是在图片
和
之间的相似度分数,
是样本对的标签(1表示相同,0表示不相同),
表示负样本对的分数,
表示正样本对的分数,
代表margin,针对contrastive loss和 triplet loss分别设定为0.5和0.01,
和
是变换参数,分别设定为2和0.5,
实用类平衡正负样本对的参数:
Binomial Loss尽管和Contrastive Loss更加相似,但是拥有一个更光滑的梯度:
Online Gradient Boosting CNNs for Metric Learning
为了让学习器更加多元,作者借鉴了梯度提升的思路。
针对一个损失函数#card=math&code=l%28%5Ccdot%29&id=pctA5),我们想要寻找一组弱学习器
%2Cf_2(x)%2C…%2Cf_M(x)%5C%7D#card=math&code=%5C%7Bf_1%28x%29%2Cf_2%28x%29%2C…%2Cf_M%28x%29%5C%7D&id=Eyno8)以及对应的boosting模型:
%7D%2Cx%5E%7B(2)%7D)%3D%5Csum%7Bm%3D1%7D%5EM%5Calpha_ms(f_m(x%5E%7B(1)%7D%2Cf_m(x%5E%7B(2)%7D)%20%5Ctag%7B3%7D%0A#card=math&code=F%28x%5E%7B%281%29%7D%2Cx%5E%7B%282%29%7D%29%3D%5Csum%7Bm%3D1%7D%5EM%5Calpha_ms%28f_m%28x%5E%7B%281%29%7D%2Cf_m%28x%5E%7B%282%29%7D%29%20%5Ctag%7B3%7D%0A&id=rSOZC)
其中%7D%2Cx%5E%7B(2)%7D)#card=math&code=F%28x%5E%7B%281%29%7D%2Cx%5E%7B%282%29%7D%29&id=egG9m)代表继承的输出,
是第m个学习器的权重。
为了在线训练,采用在线梯度提升学习算法,使用固定权值并将其内置于一个CNN中。为了避免训练多个boosting框架的CNN,将embeddin分为若干不重叠的组以减少计算时间,如下图所示:
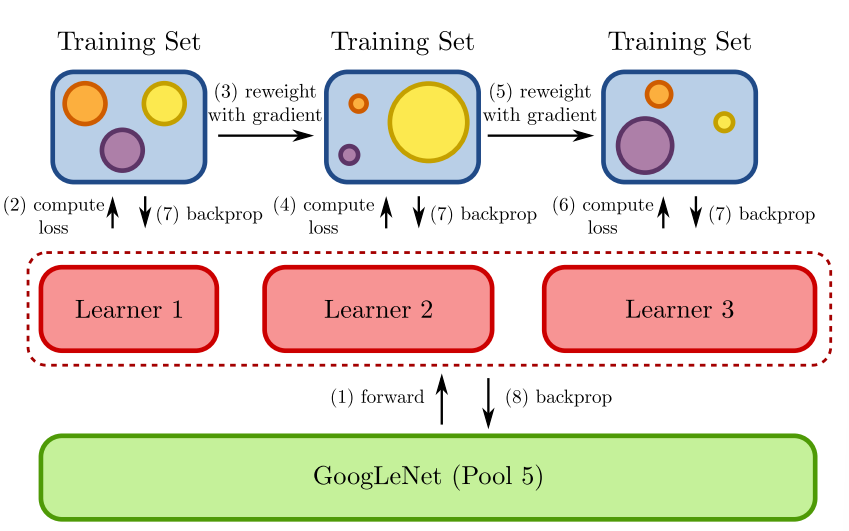
每一个组都是一个弱学习器,所有的弱学习器都共享相同的特征表示。在实验中主干使用预训练的ImageNet。
在训练过程中使用带有mementum的SGD。在前向传播中针对每一个输入样本和组计算相似分数。在反向传播中针对每个组反向传递重新设定权值的损失,第
个弱学习器针对第
个样本的的权重
由截止第
个弱学习器时集成的预测的损失函数的负梯度
#card=math&code=-l%27%28%5Ccdot%29&id=OLxY0)决定。因此每个学习器都更加关注之前的学习器错误分类的也就是梯度更大的样本。
由于每一个弱学习器相较于前一个弱学习器都学习了更加困难的样本,因此也会有更大的嵌入大小,因此第个学习器的权重
#card=math&code=%5Calpha%20m%3D%5Ceta_m%5Ccdot%20%5CPi%5EM%7Bn%3Dm%2B1%7D%281-%5Ceta_N%29&id=lF0cR),其中
。
而在测试的时候,每个弱学习器都会生成一个向量#card=math&code=f_m%28x%29&id=jlNIc)作为结果,而后对于这些向量L2正则化并根据权值
进行赋权。最终将这些向量拼接成一个特征向量
#card=math&code=f%28x%29&id=ThxVx),也就是针对图像
学习的嵌入。向量之间的距离可以有点乘计算,所以这向量的结果可以被搜索使用。
Diversity Loss Function
作者提及两个损失函数,都可以用作权重初始化或者作为训练时的辅助损失函数。在这里,两个损失函数的目的都是让集成学习更加多样化。
Activation Loss
Activation Loss直接作用于嵌入层的激活函数上。
指代分组(也就是弱学习器)的数量,
指代第
组的神经元的下标集合,
%7D%2C…%2Cx%5E%7B(N)%7D%5C%7D#card=math&code=X%3D%5C%7Bx%5E%7B%281%29%7D%2C…%2Cx%5E%7B%28N%29%7D%5C%7D&id=SSdWO)为训练集。
在用作辅助损失函数的时候,Activation Loss 和 度量损失函数(比如前文的Binomial Loss)一起使用。作者想要确保组间的激活函数相关性很低,比如使用下式来抑制:
%7D%7D(x%5E%7B(n)%7D)%3D%5Csum%7B%7Bk%5Cin%20G_i%7D%2C%7Bl%5Cin%20G_j%7D%7D(f_i(x%5E%7B(n)%7D)_k%5Ccdot%20f_j(x%5E%7B(n)%7D)_l)%5E2%20%5Ctag%7B4%7D%0A#card=math&code=L%7Bsup%7B%28i%2Cj%29%7D%7D%28x%5E%7B%28n%29%7D%29%3D%5Csum%7B%7Bk%5Cin%20G_i%7D%2C%7Bl%5Cin%20G_j%7D%7D%28f_i%28x%5E%7B%28n%29%7D%29_k%5Ccdot%20f_j%28x%5E%7B%28n%29%7D%29_l%29%5E2%20%5Ctag%7B4%7D%0A&id=qJDDg)
其中%7D)%3D%5Cphi(x%5E%7B(n)%7D)%5ETW_i#card=math&code=f_i%28x%5E%7B%28n%29%7D%29%3D%5Cphi%28x%5E%7B%28n%29%7D%29%5ETW_i&id=yfJBA)代表针对图片
%7D#card=math&code=x%5E%7B%28n%29%7D&id=Lv4P4)的第
个嵌入,这之中的
是嵌入矩阵
的第
个嵌入,
%7D)_k#card=math&code=f_i%28x%5E%7B%28n%29%7D%29_k&id=sxtQ4)代表
%7D)#card=math&code=f_i%28x%5E%7B%28n%29%7D%29&id=Actc0)的第
维。为了防止获得
的解,设置一个约束项:
%20%5Ctag%7B5%7D%0A#card=math&code=L%7Bweight%7D%3D%5Csum%7Bi%3D1%7D%5Ed%28w_i%5ETw_i-1%29%20%5Ctag%7B5%7D%0A&id=ZJSAs)
整合后获得Activation Loss:
%7D%7D(x%5E%7B(n)%7D)%2B%5Clambdaw%5Ccdot%20L%7Bweight%7D%5Ctag%7B6%7D%0A#card=math&code=L%7Bact%7D%3D%5Cfrac%7B1%7D%7BN%7D%5Csum%7Bn%3D1%7D%5EN%5Csum%7Bi%3D1%2Cj%3Di%2B1%7D%5EML%7B%7Bsup%7D%7Bi%28i%2Cj%29%7D%7D%28x%5E%7B%28n%29%7D%29%2B%5Clambda_w%5Ccdot%20L%7Bweight%7D%5Ctag%7B6%7D%0A&id=QhpyM)
其中是约束系数。
这相当于对嵌入进行强约束,即,对于给定的样本,只有单个嵌入应该是活跃的的,所有其他嵌入应接近零。
Adversarial Loss
作者希望增大特征向量之间的差异性。
通过一个生成器学习一个函数 ,使得从嵌入
,使得从嵌入到嵌入
之间的向量之间的相似度最大化,具体的做法为:
生成器将会最大化Adversarial Loss来最大化嵌入之间的相似度。而学习器试图通过最小化针对生成器的损失函数的方式来尽可能降低之间的相似性。
%7D%7D(x%5E%7B(n)%7D)%3D%5Cfrac%7B1%7D%7Bdj%7D%5Csum(f_i(x%5E%7B(n)%7D)%5Cbigodot%20g%7B(i%2Cj)%7D(fJ(x%5E%7B(n)%7D)))%5E2%20%5Ctag%7B7%7D%0A#card=math&code=L%7B%7Bsim%7D%7B%28i%2Cj%29%7D%7D%28x%5E%7B%28n%29%7D%29%3D%5Cfrac%7B1%7D%7Bd_j%7D%5Csum%28f_i%28x%5E%7B%28n%29%7D%29%5Cbigodot%20g%7B%28i%2Cj%29%7D%28f_J%28x%5E%7B%28n%29%7D%29%29%29%5E2%20%5Ctag%7B7%7D%0A&id=SAQ3D)
该损失函数可以因为一个的变化而变得很大,因此需要增加一个惩罚项:
%2B%5Csumi(%5Chat%7Bw_i%7D%5ET%5Chat%7Bw_i%7D-1)%5E2%2B%5Csum_i%7B(w_i%5ETw_i-1)%5E2%7D%20%5Ctag%7B8%7D%0A#card=math&code=L%7Bweight%7D%3D%5Cmax%20%280%2Cb%5ETb-1%29%2B%5Csum_i%28%5Chat%7Bw_i%7D%5ET%5Chat%7Bw_i%7D-1%29%5E2%2B%5Csum_i%7B%28w_i%5ETw_i-1%29%5E2%7D%20%5Ctag%7B8%7D%0A&id=GlabA)
其中和
都是
%7D(%5Ccdot)#card=math&code=g_%7B%28i%2Cj%29%7D%28%5Ccdot%29&id=bpyAq)的权重和偏置项,
表示
的第
行。
整合后获得:
%7D%7D(x%5E%7B(m)%7D)%2B%5Clambdaw%20%5Ccdot%20L%7Bweight%7D%20%5Ctag%7B9%7D%0A#card=math&code=L%7Badv%7D%3D%5Cfrac%7B1%7D%7BN%7D%5Csum%7Bn%3D1%7D%5EN%5Csum%7Bi%3D1%2Cj%3Di%2B1%7D%5EM-L%7B%7Bsim%7D%7B%28i%2Cj%29%7D%7D%28x%5E%7B%28m%29%7D%29%2B%5Clambda_w%20%5Ccdot%20L%7Bweight%7D%20%5Ctag%7B9%7D%0A&id=otlK3)
Optimizing Diversity Loss Functions
使用前述的损失函数对于嵌入矩阵进行初始化,而后训练。
或者将上述两个损失函数作为辅助损失函数在训练时应用。
Initialization Method
初始化就是寻找的估计,所以学习器需要在训练开始时就拥有较低的相关性。使用带有momentum的SGD优化:
其中的可以是Activation Loss或者Adversarial Loss中的一种。
Auxiliary Loss Function
当采取该种辅助方式时,CNN训练中的损失函数会变成:
系数控制了丰富度的范围,可以通过交叉验证来确认。

若有收获,就点个赞吧
0 人点赞
