Hyun Oh Song, Yu Xiang, Stefanie Jegelka, Silvio Savarese
摘要
学习样本对之间的距离度量对于视觉识别具有很重要的作用。在先前已经SOTA的成功的卷积神经网络的基础上,近期的工作在有针对性地训练神经网络来学习语义特征嵌入方面取得了很好的结果,所谓的语义特征嵌入在这里意味着相似的样例会被映射的彼此更加接近,而不相似的样例会被映射的彼此远离。在本文中,我们描述了一种可以通过将对间距离的向量在批次内日升值对兼具真的算法,该算法可以充分利用神经网络中批次训练的优势。这也使得算法可以通过优化一个在该提升问题上的新的结构化预测目标来学习SOTA的特征嵌入。除此之外,我们还采集了Stanford Online Products 数据集,这包括120000张、归属于23000类的在线商品的图片,可以被用来进行度量学习。我们在CUB-200-2011、CARS196和Stanford Online Products数据上结合GoogLeNet的实验都表现出了相较于目前现有的深度特征嵌入方法明显的改善,无论是在那个实验的嵌入大小。源代码和数据集可以通过 https://github.com/rksltnl/Deep-Metric-Learning-CVPR16 获得。
引言
比较并度量样例对之间的相似度是视觉识别和学习的核心要求。能够首先衡量给定的一对示例的相似程度使下述的学习问题变得更加简单。在给出下公司都函数的情况下,分类任务可以被简化为最近邻问题,聚类任务也将由于给出的相似度矩阵而更加简单。在这方面,度量学习和降维技术旨在学习语义距离度量和嵌入,以便将相似的输入对象映射到流形上的附近点,并将不同的对象相互映射开来。
更进一步地,“极限分类”(extreme classification)问题,也就是有及其多类别的分类问题最近吸引了学界关注。在这种情况下,出现了两个主要问题,这使得传统的分类方法实际上已经过时。首先,学习和推理复杂度与类数成线性关系的算法变得不切实际。其次,每一种类别的训练样本个数变得非常少。与传统的分类方法不同,度量学习在这种情形下变得十分合适,因为他具有学习距离度量的一般概念(与距离度量的类别概念相对应)的能力,并且它与在学习获得的度量空间上进行高效的最近邻推理相适应。
在SOAT的卷积神经网络的显著成功的背景下,近期的工作有针对性地训练了神经网络使用标签直接学习从输入图像到一个低维嵌入的非线性映射函数。在高层次上,这些嵌入被优化为将具有不同类别标签的示例彼此分开,并将来自相同类别的示例彼此推得更近。这些被针对性训练的网络模型的一个主要优点是它们联合学习了特征表示和语义上有意义的嵌入,而这些嵌入对类内变化具有鲁棒性。
但是,现有的方法不能充分利用网络的小批量随机梯度下降训练期间使用的训练批次。现有的方法首先随机选择样本对或者三元组来组成训练批次,并在训练批次内计算每一个样本对或者三元组的损失。而我们提出的方法则是将批次内的成对距离向量(#card=math&code=O%28m%29&id=er3l5)) 提升到成对距离矩阵(
#card=math&code=O%28m%5E2%29&id=FLTZR))。然后我们针对这个被提升的问题设计了一个新的结构化损失目标。实验表明,我们所提出的在提升问题上学习具有结构化损失目标的嵌入的方法,在使用 GoogLeNet的网络的所有实验嵌入维度上显着优于现有方法。
我们在CUB-200-2011、CARS196和自己收集的Stanford Online Products数据集上对方法进行评估。Stanford Online Products数据集拥有包括120000张、归属于23000类的在线商品的图片。据我们所知,就类别的数量和种类而言,该数据集是最大的公开可用数据集之一。 我们计划为研究社区继续维护并扩充该数据集。
本着类似通用度量学习的精神,即任务是学习相似性/距离的通用概念,我们构建了训练和测试划分,以便用于训练和测试的类集之间没有交集。我们发现,当使用我们提出的嵌入时,来自以前未见过的类别的图像的聚类质量(根据标准F1和NMI指标)和检索质量(根据标准Recall@K分数)明显更好。图 1 显示了使用提出的嵌入的Stanford Online Products数据集的一些示例检索结果。尽管我们对聚类和检索任务进行了实验,但本文的概念性贡献——将一批示例提升为密集的成对矩阵并定义结构化学习问题——通常适用于使用特征嵌入的各种学习和识别任务。

图1 使用所提出的嵌入在Stanford Online Products数据集上的示例检索结果。 第一列图片为查询图片。
相关工作
我们的工作主要与三个领域相关:(1)为了识别的深度度量学习,(2)结合卷积神经网络的深度特征嵌入,(3)零次学习与排列。
深度度量学习
Bromley等人为深度度量学习铺路,训练了 Siamese 网络进行签名验证。Chopra等人对网络进行了有区别的人脸验证训练。Chechik 等人使用三元组损失学习排名函数。Qian等人使用预先计算的激活特征,并通过距离度量学习特征嵌入进行分类。
结合SOTA的CNN的深度特征嵌入
Bell等人使用对比嵌入为了内部设计的视觉搜索学习了嵌入;FaceNet设计了三元组嵌入为了面部识别与验证学习了基于面容的嵌入。Li等人学习了一种由物体的三维形状与二维图像相结合的嵌入。与上述描述的方法不同的是,我们的方法计算一种新的结构化损失以及在提升稠密对间距离矩阵上的梯度来充分利用SGD的批次优势。
零次学习与排名
Forme,Soocher和Weston等人借助文本数据来训练可视化排名模型并限制零次学习的视觉预测。Wang等人学习了根据人类评分员对每个三元组的排名对输入的三元组数据进行排名,并发布了一个包含5033个三元组示例的三元组排名数据集。然而,该方法不能随训练数据的大小而扩展,因为与多类标签(即产品名称)相比,获得排名注释的成本非常高,而且该方法仅限于以三元组形式对数据进行排名。然而,该方法不能随训练数据的大小而扩展,因为与多类标签(即产品名称)相比,获得排名注释的成本非常高,而且该方法仅限于以三元组形式对数据进行排名。Lampert等人进行了结合训练和测试属性的零次学习(属性主要是物体的颜色与形状等)。另一方面,一些研究者对视觉识别进行零次学习,但依赖WordNet层次结构获取标签的语义信息。
论文的结构如下。在第3节中,我们首先简要回顾了最新的基于深度学习的嵌入方法。在第4节中,我们将描述如何引出这个问题并定义一个新的结构性损失。在第5节和第6节中,我们描述了实现细节和评估指标。我们在第7节中介绍了实验结果和可视化。
回顾
在这一部分,我们简短的回顾最近通过针对性训练网络来学习语义嵌入的工作。
Contrastive embedding
Contrastive embedding是在配对的数据对%5C%7D#card=math&code=%5C%7B%28xi%2Cx_j%2Cy%7Bij%7D%29%5C%7D&id=VVeHB)上训练的。对比训练最小化了同一类别的数据对之间的距离并惩罚小于
的边距的负样本对(也就是不同类别的数据对)。损失函数定义如下:
%7Dy%7Bi%2Cj%7DD%5E2%7Bi%2Cj%7D%2B(1-y%7Bi%2Cj%7D)%5B%5Calpha%20-D%7Bi%2Cj%7D%5D%5E2%2B%20%5C%5CD%7Bi%2Cj%7D%3D%7C%7Cf(xi)-f(x_j)%7C%7C_2%5Ctag%7B1%7D%0A#card=math&code=J%3D%5Cfrac%7B1%7D%7Bm%7D%5Csum%5E%7B%5Cfrac%7Bm%7D%7B2%7D%7D%7B%28i%2Cj%29%7Dy%7Bi%2Cj%7DD%5E2%7Bi%2Cj%7D%2B%281-y%7Bi%2Cj%7D%29%5B%5Calpha%20-D%7Bi%2Cj%7D%5D%5E2%2B%20%5C%5CD%7Bi%2Cj%7D%3D%7C%7Cf%28x_i%29-f%28x_j%29%7C%7C_2%5Ctag%7B1%7D%0A&id=qVBjW)
其中代表一个批次的图片样本的数量,
#card=math&code=f%28%5Ccdot%29&id=dqRj8)时从网络中获得特征嵌入,标签
表示数据对
#card=math&code=%28xi%2Cx_j%29&id=ZNHVb)是否是来自同一类比,#card=math&code=%5B%5Ccdot%5D_%2B%20%3D%20%5Ctext%7Bmax%7D%280%2C%5Ccdot%29&id=UJl2g)是一个Hinge Loss函数。请参阅原文了解更多细节。
Triplet embedding
Triplet embedding是在数据三元组%7D%2Cx_p%5E%7B(i)%7D%2Cx_n%5E%7B(i)%7D%20%5C%7D#card=math&code=%5C%7B%28x_a%5E%7B%28i%29%7D%2Cx_p%5E%7B%28i%29%7D%2Cx_n%5E%7B%28i%29%7D%20%5C%7D&id=eaqGk)上训练的,其中
%7D%2Cx_p%5E%7B(i)%7D)#card=math&code=%28x_a%5E%7B%28i%29%7D%2Cx_p%5E%7B%28i%29%7D%29&id=sZrFL)属于同一类别,
%7D%2Cx_n%5E%7B(i)%7D)#card=math&code=%28x_a%5E%7B%28i%29%7D%2Cx_n%5E%7B%28i%29%7D%29&id=Oz7NX)属于不同类别,
%7D#card=math&code=x_a%5E%7B%28i%29%7D&id=ZYH0p)被称为三原则的“锚”(anchor)。直觉上来说,训练过程鼓励网络去寻找一个在
%7D#card=math&code=x_a%5E%7B%28i%29%7D&id=TQZro)和
%7D#card=math&code=x_n%5E%7B%28i%29%7D&id=DHjEh)之间的距离大于
%7D#card=math&code=x_a%5E%7B%28i%29%7D&id=HSVNy)和
%7D#card=math&code=x_p%5E%7B%28i%29%7D&id=NCWIp)之间的距离加上一个间隔
的嵌入。损失函数定义如下:
-f(xi%5Ep)%7C%7C%20%5C%5CD%7Bia%2Cin%7D%3D%7C%7Cf(xi%5Ea)-f(x_i%5En)%7C%7C%20%5Ctag%7B2%7D%0A#card=math&code=J%3D%5Cfrac%7B3%7D%7B2m%7D%5Csum_i%5E%7Bm%2F3%7D%5BD%5E2%7Bia%2Cip%7D-D%5E2%7Bia%2Cin%7D%2B%5Calpha%5D%2B%20%5C%5C%20D%7Bia%2Cip%7D%3D%7C%7Cf%28x_i%5Ea%29-f%28x_i%5Ep%29%7C%7C%20%5C%5CD%7Bia%2Cin%7D%3D%7C%7Cf%28x_i%5Ea%29-f%28x_i%5En%29%7C%7C%20%5Ctag%7B2%7D%0A&id=eNcOZ)
各项定义与前文的Contrastive Embedding相似。请参阅原文了解更多细节。
Deep metric learning via lifted structured feature embedding
我们基于训练集中的所有正负样本对设计了一个损失函数:
%5Cin%20%5Chat%7Bp%7D%7D%5Ctext%7Bmax%7D(0%2CJ%7Bi%2Cj%7D)%5E2%20%5C%5CJ%7Bi%2Cj%7D%3D%5Cmax(%5Cmax%7B(i%2Ck)%5Cin%5Chat%7BN%7D%7D%5Calpha%20-%20D%7Bi%2Ck%7D%2C%5Cmax%7B(j%2Cl)%5Cin%5Chat%7BN%7D%7D%5Calpha%20-%20D%7Bj%2Cl%7D)%2BD%7Bi%2Cj%7D%20%5Ctag%7B3%7D%0A#card=math&code=J%3D%5Cfrac%7B1%7D%7B2%7C%5Chat%7Bp%7D%7C%7D%5Csum%7B%28i%2Cj%29%5Cin%20%5Chat%7Bp%7D%7D%5Ctext%7Bmax%7D%280%2CJ%7Bi%2Cj%7D%29%5E2%20%5C%5CJ%7Bi%2Cj%7D%3D%5Cmax%28%5Cmax%7B%28i%2Ck%29%5Cin%5Chat%7BN%7D%7D%5Calpha%20-%20D%7Bi%2Ck%7D%2C%5Cmax%7B%28j%2Cl%29%5Cin%5Chat%7BN%7D%7D%5Calpha%20-%20D%7Bj%2Cl%7D%29%2BD_%7Bi%2Cj%7D%20%5Ctag%7B3%7D%0A&id=jNUOc)
这里是训练集的一个正样本的集合,
是训练集的一个负样本的集合。该函数带来了两个挑战:
- 不光滑
- 评估它和计算次梯度都需要多次挖掘所有的示例对
我们使用两种办法解决这些挑战:
首先,我们优化一个光滑的上届来代替原函数。
其次,鉴于大型数据集较为频繁,我们使用随机方法。
然而,以前的工作通过随机均匀地绘制数据对或数据三元组来实现随机梯度下降,我们的方法在以下两个方面与上述方法区分:
- 我们的方法侧重那些“困难”的样本对,正如
的次梯度将使用那些接近的负样本对一样
- 它利用了一次采样中小批次的全部信息,而不仅仅是单个样本对。
图片2a与2b阐述了一个大小的样本批次在Contrastive 和 Triplet embedding中的效果,同一个批次中红色边代表正样本对,蓝色边代表都样本对。需要注意的是,向图中添加额外的顶点比添加额外的边要花费更多,因为向图中添加顶点会导致额外的I/O时间和/或存储开销
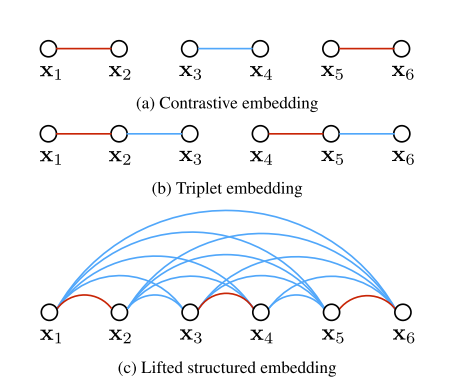
图2 带有6个数据样例的训练批次的插图。红边和蓝边分别表示相似和不同的示例。相反,我们的方法显式地考虑了批处理中的所有成对边。
为了充分利用一整个批次,一个关键的点子就是提高小批次的优化来使用在一个批次内的所有的#card=math&code=O%28m%5E2%29&id=mrYTA)个点对,而不是使用
#card=math&code=O%28m%29&id=gx8ak)个单独的点对。图2c说明了将训练批示例转换为完全连接的成对距离密集矩阵的概念。当给出一个批次的
维度的嵌入特征
,以及每个批次元素的平方形式的列向量:
%7C%7C%5E22%2C…%2C%7C%7Cf(x_m)%7C%7C%5E2_2%5D%5ET#card=math&code=%5Chat%7Bx%7D%3D%5B%7C%7Cf%28x_1%29%7C%7C%5E2_2%2C…%2C%7C%7Cf%28x_m%29%7C%7C%5E2_2%5D%5ET&id=m41EM),则更加密集的对剑距离平方矩阵可以由计算高效算出:
,其中-f(x_j)%7C%7C%5E2_2#card=math&code=D%7Bij%7D%5E2%3D%7C%7Cf%28x_i%29-f%28x_j%29%7C%7C%5E2_2&id=FKEvf)。但是需要注意的是,随机抽选的样本对之间的负边仅仅具有很少的信息,或者说,它们和那些更加突出、更加接近的“困难“的、被完全次梯度关注的近邻是不一样的。
因此,我们在选择彼此的时候不是完全随机的,而是整合那些重要样本的元素。我们随机抽取一些正样本,然后添加这些正样本的”困难“的近邻到这个小批次中。这种增强添加了次梯度将会使用的相关信息。图 3 说明了批次中一对正样本的挖掘过程,其中对于正样本中的每个图像,我们找到其接近”困难“负图像。需要注意的是我们的方法允许从左或右侧图片挖掘困难负样本,这和三元组的仅仅根据事先定义好的锚点定义负样本的结构是不同的。事实上,挖掘困难负边的过程等价于结构化预测环境下损失增强推理的计算。通过预先计算成对批次平方距离矩阵,可以有效地处理我们的损失增强推理。
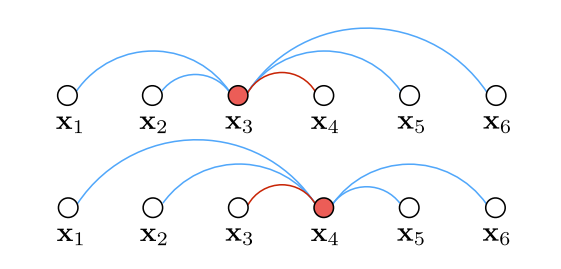
图3 针对每个正样本对的每个左右示例挖掘困难负边。
更进一步地,使用等式4中的嵌套max函数在实际中挖掘单一的最困难负样本将导致网络收敛于一个不佳的局部最优。因此我们使用一个光滑的上界))#card=math&code=%5Chat%7BJ%7D%28Df%28x%29%29%29&id=Bp3lY)进行优化。我们每个批次的损失函数定义如下:
%5Cin%20N%7Dexp%5C%7B%5Calpha%20-D%7Bi%2Ck%7D%5C%7D%2B%5Csum%7B(j%2Cl)%5Cin%20N%20%7Dexp%5C%7B%5Calpha%20-D%7Bj%2Cl%7D)%2BD%7Bi%2Cj%7D%20%5C%5C%20%5Chat%7BJ%7D%3D%5Cfrac%7B1%7D%7B2%7Cp%7C%7D%5Csum%7B(i%2Cj)%5Cin%20p%7D%5Cmax(0%2C%5Chat%7BJ%7D%7Bi%2Cj%7D)%5E2%20%5Ctag%7B4%7D%0A#card=math&code=%5Chat%7BJ%7D%7Bi%2Cj%7D%3Dlog%28%5Csum%7B%28i%2Ck%29%5Cin%20N%7Dexp%5C%7B%5Calpha%20-D%7Bi%2Ck%7D%5C%7D%2B%5Csum%7B%28j%2Cl%29%5Cin%20N%20%7Dexp%5C%7B%5Calpha%20-D%7Bj%2Cl%7D%29%2BD%7Bi%2Cj%7D%20%5C%5C%20%5Chat%7BJ%7D%3D%5Cfrac%7B1%7D%7B2%7Cp%7C%7D%5Csum%7B%28i%2Cj%29%5Cin%20p%7D%5Cmax%280%2C%5Chat%7BJ%7D%7Bi%2Cj%7D%29%5E2%20%5Ctag%7B4%7D%0A&id=M9dtt)
这里指的是该批次中正样本对的集合,
指的是该批次中负样本对的集合。输入特征嵌入的反向传播梯度可如算法1所示导出,其中对于距离的梯度可以被表示成:
其中。时一个指示函数,当其中的表达式为真输出1,都则输出0。如算法1和等式5、6和7所示,我们的方法为所有负样本对提供信息梯度信号,只要它们在任何正对的范围内(与仅更新最硬的负对相反),这将使得优化更加稳定。

算法1 反向传播梯度
说明完正式目标后,我们现在阐述并讨论一些contrastive和triplet embedding将失灵但我们提出的方法将成功学习的情况。图片4阐述了二维的、带有来自三个不同类别的样本的失败案例。Contrastive embedding(图片4a)在随机选取的负样本和其他类别的样本共线时将会失败。Triplet embedding(图片4b)在选取的负样本
在被选取的正样本
和锚点
的区域边界内时会失败。在这种案例中,contrastive和triplet embedding都会价格正样本对
#card=math&code=%28x_i%2Fx_a%29&id=sY5Xy)错误地推向第三个类别的样本所在的聚簇中。但是,在我们提出的方法中(图片4c),当给出一个足够多的样本
,在区域边界背的困难负样本(比如图片4c中的
)将会将正样本
推向正确的方向。
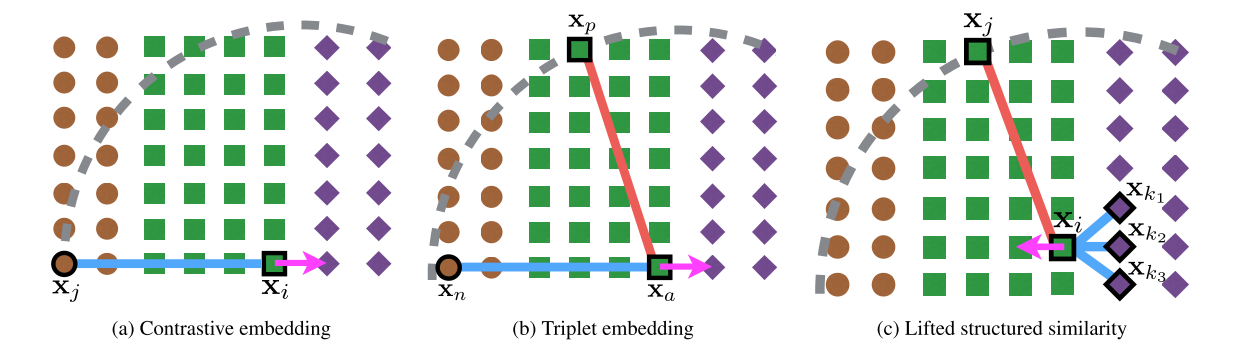
图4 随机采样训练批次的对比损失和三重损失的失败模式的说明。 棕色圆圈、绿色方块和紫色菱形代表三个不同的类别。 灰色虚线表示Hinge Loss中的边际界限(损失在界限外为零)。 品红色箭头表示正样本的负梯度方向。
实现细节
我们使用了Caffe包来训练和测试Contrastive embedding,Triplet embedding和我们的嵌入。所有实验的最大训练迭代设置为20000。边缘参数设置为1.0。针对Contrastive embedding我们的方法的批次大小设定为128,triplet embedding的批次大小设置为120。在训练过程中,所有卷积都使用在ImageNet ILSVRC上预训练的网络初始化,全连接层(也就是最后一层)的参数被随机设置。我们也针对随机初始化的全连接层的学习率乘以10以加速收敛。所有的训练与测试图片都被正则化至
。针对训练的数据增强,所有的图像都被随机裁剪为
并被随机水平镜像。同时在训练时,我们用尽了所有的正样本对并且随机采样了大约和正样本对数量相当的负样本对。
评估
在这个部分我们会简要的介绍在实验中评估的指标。针对聚类任务,我们使用和NMI指标。
指标计算正确率与召回率的调和平均数:
。归一化互信息(NMI)指标将聚类集合
和真实类别集合
作为输入,其中
代表其聚类簇为
的数据的集合,
表示真实类别标签为
的数据的集合。NMI由互信息和聚类的平均熵加上标签的熵的比值构成:
%3D%5Cfrac%7BI(%5COmega%3B%5Cmathbb%7BC%7D)%7D%7B2(H(%5COmega)%2BH(%5Cmathbb%7BC%7D))%7D#card=math&code=NMI%28%5COmega%2C%5Cmathbb%7BC%7D%29%3D%5Cfrac%7BI%28%5COmega%3B%5Cmathbb%7BC%7D%29%7D%7B2%28H%28%5COmega%29%2BH%28%5Cmathbb%7BC%7D%29%29%7D&id=yjI4x)。参与相关文献以了解更多细节。针对检索任务,我们使用Recall@K指标。每个测试图像请求从测试集中检索K个近邻,在这K个近邻中如果有一张图像和测试图像拥有相同类别就得1分,否则得0分。
实验
我们将展示在CUB200-2011,CARS196和我们自己的Stanford Online Products数据集上的实验,其中在Stanford Online Products数据集上我们使用前一半的数据用作训练集,后一半的数据用作测试集。在测试过程中,我们首先计算所有的测试图片在不同嵌入大小,包括64,128,256,512,上的嵌入。在聚类评估中,我们在训练集上运行采用对分发的Affinity Propagation聚类(AP)算法,其中的聚类个数被设置为训练集中的类别个数。最终的聚类的质量使用标准F1指标和NMI指标。针对搜索的评估,我们在K的对数空间中标准召回率Recall@K上进行。整个实验的主干网络是GoogLeNet。
消融研究:批次大小m的影响
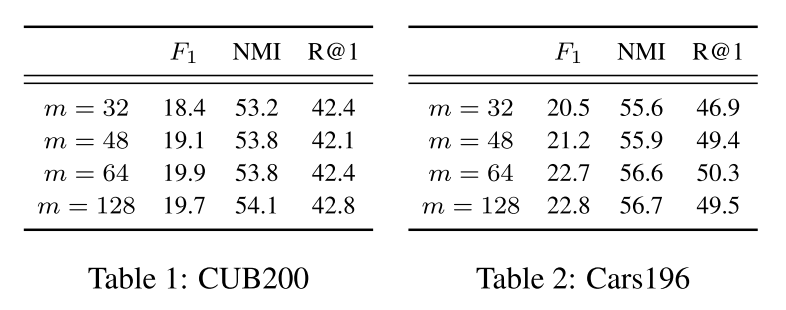
表格1与表格2展示了批次大小在CUB200-211和CARS196数据集上的表现,表格使用F1,NMI和R@1来描述。由于英伟达K80显存大小的限制,批次大小被限制在了128及以下。即便存在梯度的不稳定,最小的批次大小32依然保证了训练没有出现分歧。如表格1 和表格2 所示,计算我们提出的的平滑结构化估计在批量大小方面提供了稳定性。
CUB-200-2011
CUB-200-2011数据集中含有200各类别的鸟,一共有11788张图片。我们将前100个类别的、5864张鸟类图片用于训练,剩余的5924张图片用作测试。图5展示了采用对比损失、三元组损失、在ImageNet上使用来自预训练的GoogLeNet的pool5激活函数以及我们提出的方法在F1、NMI和Recall@K等指标上的定量聚类结果。我们的嵌入在所有的嵌入大小以及在标准F1、NMI和Recall@K等指标上都有很好的表现。CUB200-2011数据集的测试集划分的定性检索结果见补充资料。图7使用Barnes-Hut t-SNE可视化了我们64维嵌入上的结果。尽管 t-SNE 嵌入并不能直接转化为高维嵌入,但很明显相似类型的鸟类非常聚集在一起并且与其他物种分开。
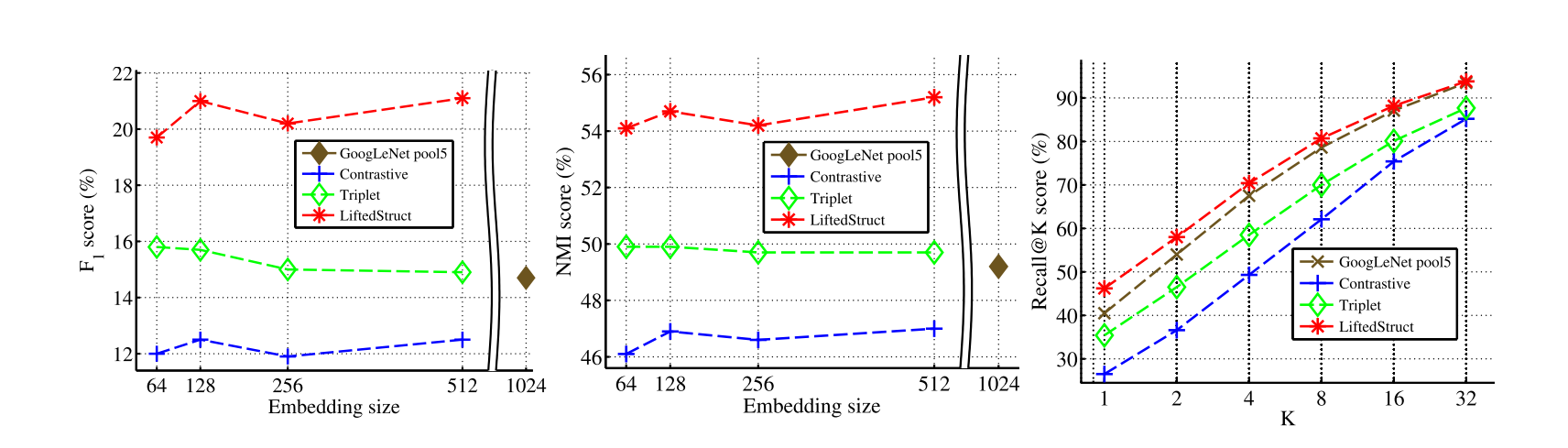
图5 在CUB-200-2011数据集上的标准F1、NMI和Recall@K指标表现
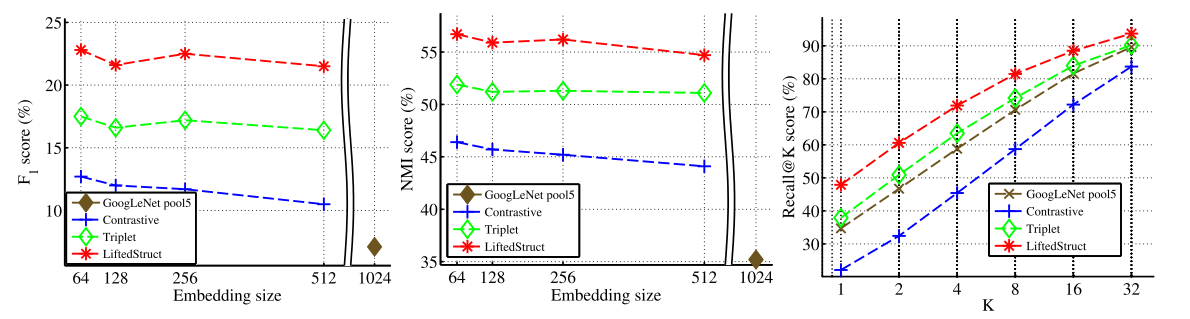
图6 在CARS196数据集上的标准F1、NMI和Recall@K指标表现
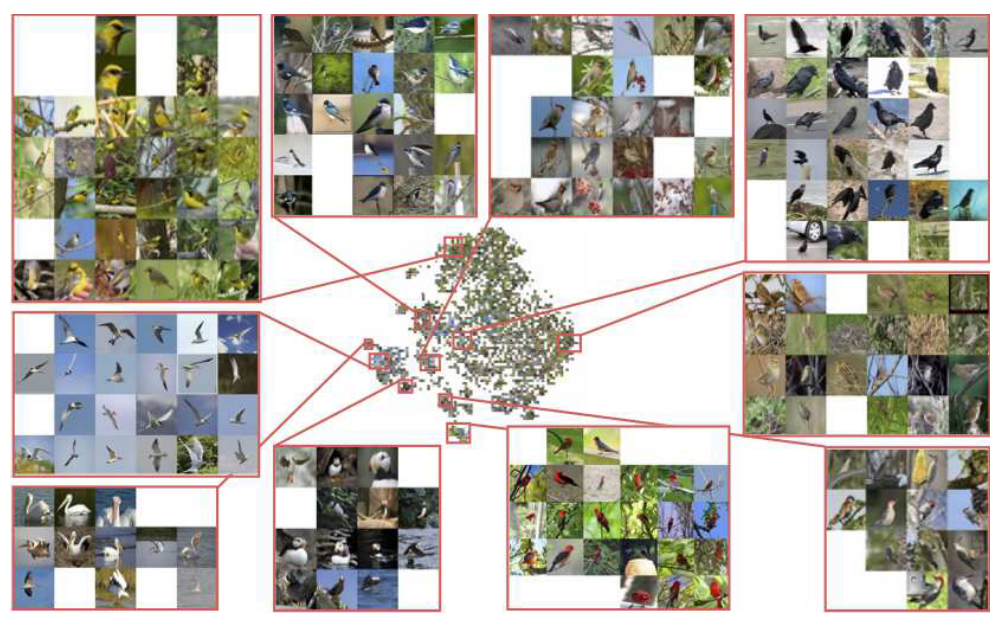
图7 CUB-200-2021 的64维嵌入 Barnes-Hut t-SNE可视化结果

图8 CARS196的64维嵌入Barnes-Hut t-SNE可视化结果
CARS196
CARS196数据集含有198个类别、16185张汽车的图片。我们将前98个类别的8054张图片用于训练,将其他的98个类别的8131张图片进行测试。图6展示了采用对比损失、三元组损失、在ImageNet上使用来自预训练的GoogLeNet的pool5激活函数以及我们提出的方法在F1、NMI和Recall@K等指标上的定量聚类结果。CARS196数据集的测试集划分的定性检索结果见补充资料。图8使用Barnes-Hut t-SNE可视化了我们64维嵌入上的结果。我们可以观察到,尽管存在显着的姿势变化和车身油漆的变化,嵌入还是将来自同一品牌汽车的图像聚集在一起。
Stanford Online Products 数据集
我们使用eBay.com的网络爬虫API来下载商品图片并过滤掉了重复的或者不相关的图片(比如关于联系电话和logo的图片)。经过该预处理的数据集包括120053张图片,其中有22634个在线商品,也就是类别。每个商品平均有5.3张图片。对于实验,我们拆分了11318 个类别的59551张图像用于训练,将11316 个类别的60502张图像拆分为测试集。图9展示了采用GoogLeNet的方法在F1、NMI和Recall@K等指标上的定量聚类结果。
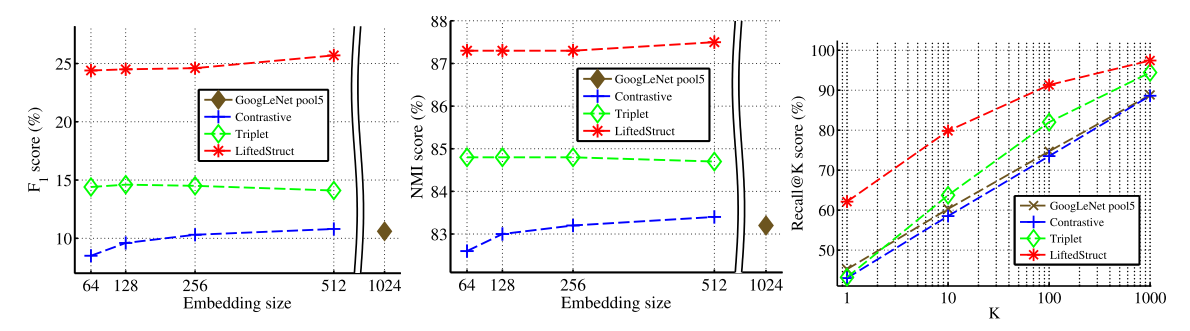
图9 在Stanford Online Products数据集上的标准F1、NMI和Recall@K指标表现
图10和图11显示一些示例查询和数据集上成功和失败案例的最近邻。尽管视角、配置和光照发生了巨大变化,但我们的方法可以成功地从同一类中检索示例,并且大多数检索失败来自相似产品之间的细微差异。请参阅补充材料来获取t-SNE可视化的嵌入结果。

图10 在Stanford Online Products数据集上的成功请求展示,基于512维的嵌入。 第一列中的图像是查询图像,其余的是五个最近邻。

图11 在Stanford Online Products数据集上的失败查询示例。 大多数失败是由于类似产品之间细微的细微差异。 第一列中的图像是查询图像,其余的是五个最近邻。
结论
我们描述了一种深度特征嵌入和度量学习算法,该算法在神经网络训练期间在批次内提升的成对距离矩阵上定义了一个新的结构化预测目标。 CUB-200-2011 、CARS196和Stanford Online Products数据集的实验结果在所有实验嵌入维度上都显示了最先进的性能。
致谢
我们感谢来自Stanford AI Lab-Toyota Center for Artificial Intelligence Research的ONR给予的#N00014-131-0761 and grant #122282支持。
参考文献
[1] S. Bell and K. Bala. Learning visual similarity for product design with convolutional neural networks. In SIGGRAPH, 2015. 1, 2, 3, 5
[2] Y. Bengio, J. Paiement, and P. Vincent. Out-of-sample extensions for lle, isomap, mds, eigenmaps, and spectral clustering. In NIPS, 2004. 1
[3] J. Bromley, I. Guyon, Y. Lecun, E. SŁckinger, and R. Shah. Signature verification using a “siamese” time delay neural network. In NIPS, 1994. 2
[4] G. Chechik, V. Sharma, U. Shalit, and S. Bengio. Large scale online learning of image similarity through ranking. JMLR, 11, 2010. 2
[5] S. Chopra, R. Hadsell, and Y. LeCun. Learning a similarity metric discriminatively, with application to face verification. In CVPR, June 2005. 2
[6] A. Choromanska, A. Agarwal, and J. Langford. Extreme multi class classification. In NIPS, 2013. 1
[7] T. Cox and M. Cox. Multidimensional scaling. In London: Chapman and Hill, 1994. 1
[8] I. S. Data. https://sites.google.com/site/imagesimilaritydata/, 2014. 2
[9] eBay Developers Program. http://go.developer.ebay.com/what-ebay-api, 2015. 6
[10] B. J. Frey and D. Dueck. apclusterk.m. http://[www.psi.toronto.edu/affinitypropagation/](http://www.psi.toronto.edu/affinitypropagation/) apclusterK.m, 2007. 5
[11] B. J. Frey and D. Dueck. Clustering by passing messages between data points. Science, 2007. 5
[12] A. Frome, G. S. Corrado, J. Shlens, S. Bengio, J. Dean, M. Ranzato, and T. Mikolov. Devise: A deep visual-semantic embedding model. In NIPS, 2013. 2
[13] J. Goldberger, S. Roweis, G. Hinton, and R. Salakhutdinov. Neighbourhood component analysis. In NIPS, 2004. 1
[14] R. Hadsell, S. Chopra, and Y. Lecun. Dimensionality reduction by learning an invariant mapping. In CVPR, 2006. 2, 3, 4, 5, 6
[15] H. Jegou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search. In PAMI, 2011. 5
[16] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093, 2014. 5
[17] T. Joachims, T. Finley, and C.-N. Yu. Cutting-plane training of structural svms. JMLR, 2009. 4
[18] T. I. Jolliffe. Principal component analysis. In New York: Springer-Verlag, 1986. 1
[19] J. Krause, M. Stark, J. Deng, and F.-F. Li. 3d object representations for fine-grained categorization. ICCV 3dRR-13, 2013. 1, 2, 5, 6, 8
[20] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. 1, 2
[21] C. H. Lampert, H. Nickisch, and S. Harmeling. Attributebased classification for zero-shot visual object categorization. In TPAMI, 2014. 2
[22] Y. Li, H. Su, C. Qi, N. Fish, D. Cohen-Or, and L. Guibas. Joint embeddings of shapes and images via cnn image purification. In SIGGRAPH Asia, 2015. 2, 3
[23] C. D. Manning, P. Raghavan, and H. Schtze. Introduction to Information Retrieval. Cambridge university press, 2008. 2, 5
[24] T. Mensink, J. Verbeek, F. Perronnin, and G. Csurk. Metric learning for large scale image classification: Generalizaing to new classes at near-zero cost. In ECCV, 2012. 2
[25] M. Palatucci, D. Pomerleau, G. E. Hinton, and T. M. Mitchell. Zero-shot learning with semantic output codes. In NIPS, 2009. 2
[26] Y. Prabhu and M. Varma. Fastxml: A fast, accurate and stable tree-classifier for extreme multi-label learning. In SIGKDD, 2014. 1
[27] Q. Qian, R. Jin, S. Zhu, and Y. Lin. Fine-grained visual categorization via multi-stage metric learning. In CVPR, 2015. 2
[28] M. Rohrbach, M. Stark, and B. Schiel. Evaluating knowledge transfer and zero-shot learn- ing in a large-scale setting. In CVPR, 2011. 2
[29] S. Roweis and L. Saul. Nonlinear dimensionality reduction by locally linear embedding. In Science, 290. 1
[30] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015. 5, 6
[31] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, 2015. 1, 2, 3, 4, 5, 6
[32] R. Socher, C. D. M. M. Ganjoo H. Sridhar, O. Bastani, and A. Y. Ng. Zero-shot learning through cross-modal transfer. In ICLR, 2013. 2
[33] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015. 1, 2, 5, 6, 8
[34] G. Taylor, R. Fergus, G. Williams, I. Spiro, and C. Bregler. Pose-sensitive embedding by nonlinear nca regression. In NIPS, 2010. 1
[35] I. Tsochantaridis, T. Hofmann, T. Joachims, and Y. Altun. Support vector machine learning for interdependent and structured output spaces. In ICML, 2004. 4
[36] L. van der maaten. Accelerating t-sne using tree-based algorithms. In JMLR, 2014. 6, 7
[37] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011. 1, 2, 5, 6, 8
[38] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu. Learning fine-grained image similarity with deep ranking. In CVPR, 2014. 2
[39] K. Q. Weinberger, J. Blitzer, and L. K. Saul. Distance metric learning for large margin nearest neighbor classification. In NIPS, 2006. 1, 2, 3, 4, 5, 6
[40] J. Weston, S. Bengio, and N. Usurer. Wsabi: Scaling up to large vocabulary image annotation. In IJCAI, 2011. 2

若有收获,就点个赞吧
0 人点赞
