Metric Learning Overview
Why metric learning is important
在文章的开头,作者首先陈述了度量学习的本质:
将数据映射到一个相似数据接近、不相似数据疏远的嵌入空间中
而后从这个目的出发,引出在度量学习中的两种常见损失:Embedding Loss和Classification Loss。
总的来说,Embedding Loss是作用在一个批次的数据之间的关系上,而Classification Loss时包含一个将嵌入空间转换成类别输出的向量的权重矩阵。Embedding Loss比较适合的场合是根据输入返回相似对象的搜索。而在给每个样本都分配标签、但可以度量数据之间的关系的情况下,Classification Loss就不合适了。
Embedding Losses
数据对和三元组是两种度量学习方法的根基。比如Contrastive Loss基于数据对来调整正负数据对之间的距离,Triplet Loss通过将锚点与正样本之间的距离优化小于锚点与负样本之间的距离和margin来实现分类。基于上述两种方式衍生出了很多其他的损失函数。
Classification Losses
Classification Losses是基于包含一个每一列和一个特定类别相关的权重矩阵上的。在绝大多数情况下,训练过程都包括将嵌入向量的权重和矩阵相乘来获得全连接层的输出,而后在这个输出的基础上增加损失函数。
Pair and triplet mining
Mining就是寻找最佳的数据对和三元组的过程,可以是离弦的也可以是在线的。离线方法在批次建立前被执行,因此每个批次就仅仅包含那些含有信息量最大的元素。而在线方法则是每个随机抽样的批次中来寻找有信息的元素。当然,也可以使用所有的数据对和三元组,但这也太占用内存了,同时过于简单的、包含信息少的数据对与三元组也会导致收敛较慢。因此还是需要选择最困难的正负样本的,但这样可能会引入噪声且可能导致仅仅收敛在局部最优。
Advanced training methods
有些网络使用了一些trick,比如GAN中的生成器,有些则使用层次类树来估计Triplet Loss中最佳的边界。集成学习也被多人使用。
Flaws in the existing literature
Unfair comparisons
有些研究更换了网络结构,比如一篇文章使用ResNet50去比较一个GoogLeNet,声称自己的算法有更好的效果,但其实这些效果是更换CNN主干获得的。其他的一种方式是使用更加精细的数据增强但在论文里闭口不提。其他的手段比如更换优化器和学习率也会提高正确率,也很难判断提升到底是不是算法本身的进步带来的。结果也没说明最终的结果的置信区间,对于最后的结果是否是平均表现、是否多次运行求平均闭口不提。
Weakness of commonly used accuracy metrics
比较常见的评价指标包括Recall@K, NMI和F1指标。但这些指标可能未必可以完全反映真实的情况。
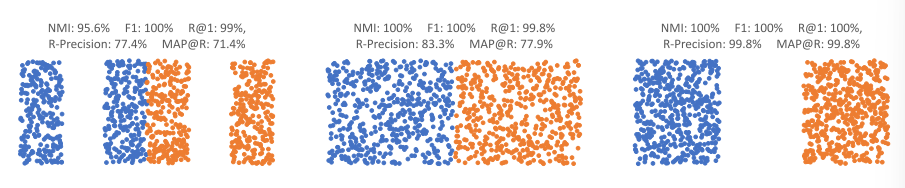
图一
在图一中表示的三种嵌入空间中,很明显最右侧的更佳,但是单单从指标来看,最右侧的和最左侧的结果在NMI,F1和R@1上基本相差无几。事实上F1和NMI在上述三种结果中的评价分数基本一致,同时它们要求对嵌入进行聚类,这引入了两个可变性因素:聚类算法的选择和聚类结果对初始化的敏感性。由于研究者知道聚类的真实个数,k-均值聚类是显而易见的选择,也是通常使用的方法。因此不同的聚类算法就会有不同结果。因此作者认为类似Recall@K这种直接作用于嵌入空间上的评价指标更加好。NMI也倾向于对具有多个类的数据集给予高分,而不顾模型的真实准确性如何。
Training with test set feedback
绝大多数研究都声称使用50%作为训练集和测试集划分的比例,但并没有留出验证集:测试集每个Epoch后会被测试,并且文章往往仅仅记录最好的一次的结果,同时这也意味着模型选择和超参数调整是根据测试集的表现来完成。有些文章也没有说明循环的次数,超参数的选择也依赖测试集上的验证结果。这样做的直接结果就是在测试集上的结果是过拟合的。
Proposed evalucation method
作者使用了pytorch和较为一致的和环境设定来进行实验评估。
在评估时使用的指标为Mean Average Precision at R(MAP@R):
%20%5Ctag%7B1%7D%20%0A#card=math&code=MAP%40R%3D%5Cfrac%7B1%7D%7BR%7D%5Csum_%7Bi%3D1%7D%5ERP%28i%29%20%5Ctag%7B1%7D%20%0A&id=nbYS5)
%3D%20%5Cend%7Bequation*%7D%20%0A%5Cbegin%7Bcases%7D%5Ctext%7Bprecision%20at%20%7Di%5Cquad%20%5Ctext%7Bif%20the%20ith%20retrieval%20is%20correct%7D%5C%5C0%5Cquad%5Ctext%7Botherwise%7D%5Cend%7Bcases%7D%20%5Ctag%7B2%7D#card=math&code=%5Cbegin%7Bequation%2A%7DP%28i%29%3D%20%5Cend%7Bequation%2A%7D%20%0A%5Cbegin%7Bcases%7D%5Ctext%7Bprecision%20at%20%7Di%5Cquad%20%5Ctext%7Bif%20the%20ith%20retrieval%20is%20correct%7D%5C%5C0%5Cquad%5Ctext%7Botherwise%7D%5Cend%7Bcases%7D%20%5Ctag%7B2%7D&id=zDOih)
为了寻找最好的超参数,使用50次贝叶斯优化迭代,每次迭代包括四折交叉验证。对于最佳超参数,加载每个训练集分区的最高精度检查点,并计算测试集的嵌入并进行L2正则化。
Conclusion
除了发现目前的研究存在的问题,作者认为的较好的方向是:
未来的工作可以探索最佳超参数与数据集或者架构组合之间的关系,以及不同损失表现相似的原因。 当然,追求最高的准确性是另一个研究方向。 如果遵循正确的机器学习,并以公平的方式与之前的工作进行比较,未来度量学习论文的结果将更好地反映现实,并且更有可能推广到其他高影响领域,如自监督学习 .

若有收获,就点个赞吧
0 人点赞
