特征嵌入是在表格类型的数据上训练神经网络最重要的一个步骤之一,但很遗憾的是它仅仅在NLP领域被重视。它在一些领域可以超过一些梯度加速算法比如XGBoost。
什么是特征嵌入
神经网络在处理稀疏的类别特征时往往会遇到困难。嵌入是一种减少这些特征来提高模型表现的方法。在讨论结构化的数据集之前,先来看看嵌入是怎样在NLP中被使用的。在NLP的处理中,人们往往面对的是拥有成千上万个词的词典。这些词典往往是采用one-hot编码来输入到模型中,这在数学上意味着每一个词都会拥有一个单独的列。当把一个词语喂给模型时,相应的列上显示1,其余列显示0。这将产生一个难以置信的巨大的数据输入,解决的办法则是嵌入。
嵌入本质上将根据训练文本对具有相似含义的单词进行分组并返回它们的位置。比如,“fun”,“happy”,“humor”将拥有相似的嵌入值。在实践中,神经网络在这些代表性特征上的表现要好得多。
在结构化的数据中采用嵌入
结构化的数据集往往拥有稀疏的类别特征。比如在下面的客户销售表中,有邮政编码和商店ID。
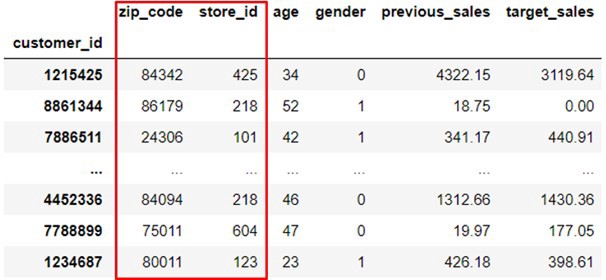
因为这些列可能有成百上千个不同的唯一值,所以使用它们会产生与上面 NLP 问题中提到的相同的性能问题。那么为什么不以同样的方式使用嵌入呢?
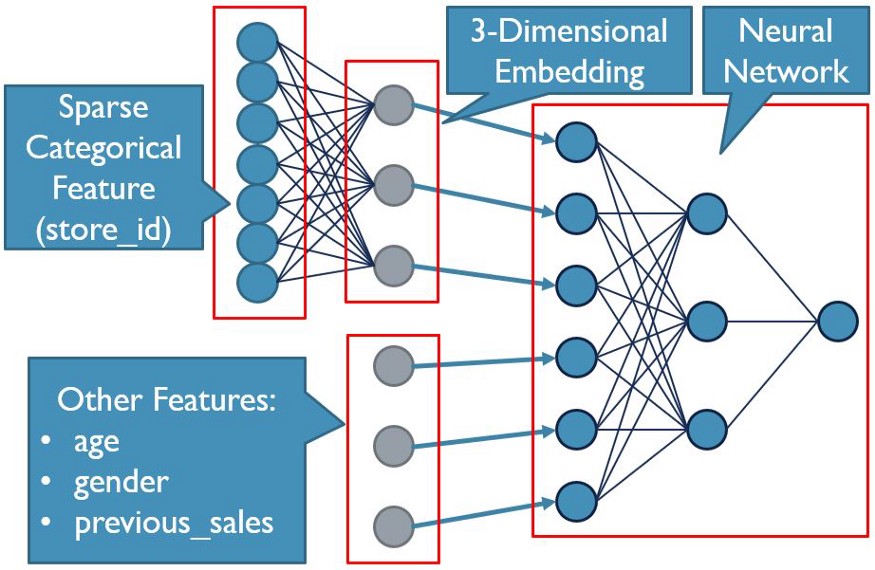
问题是,我们现在处理的功能不止一个。在这种情况下,我们不仅需要处理两个单独的稀疏分类列(邮政编码和商店 ID),还需要处理其他有影响力的数据,如销售总额。我们根本无法简单地直接将我们的特征输入到嵌入中。然而,我们可以在模型的第一层训练我们的嵌入,并在这些嵌入的旁边添加正常特征。这不仅将邮政编码和存储 ID 转换为有用的特征,而且现在其他有用的特征不会被成千上万的列冲淡。

若有收获,就点个赞吧
0 人点赞
