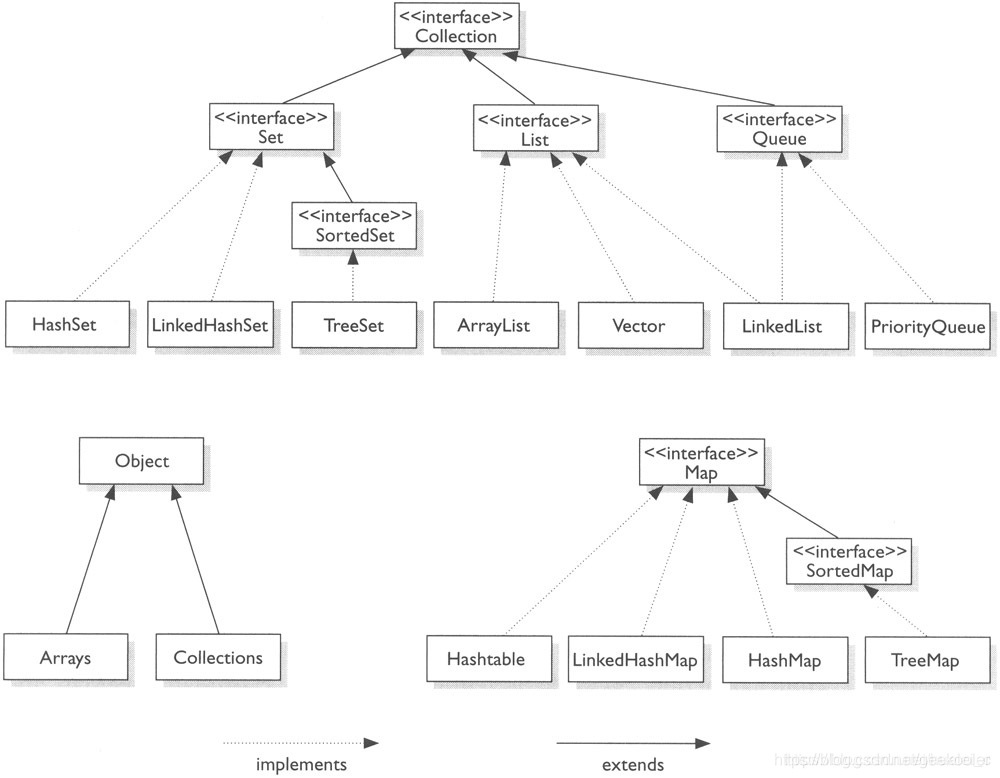
-
hashSet底层
底层 是以个 hashMap , 底层进行调用的为hashMap的构造器 ```java public class HashSet
extends AbstractSet implements Set , Cloneable, java.io.Serializable { static final long serialVersionUID = -5024744406713321676L; private transient HashMap
// Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object();
/**
- Constructs a new, empty set; the backing HashMap instance has
default initial capacity (16) and load factor (0.75). */ public HashSet() { map = new HashMap<>(); }
/**
- Constructs a new, empty set; the backing HashMap instance has
- the specified initial capacity and the specified load factor. *
- @param initialCapacity the initial capacity of the hash map
- @param loadFactor the load factor of the hash map
- @throws IllegalArgumentException if the initial capacity is less
- than zero, or if the load factor is nonpositive */ public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } 当然也支持自定义初始大小以及扩容系数,这些本篇后面会提到
<a name="DNWI7"></a># hashSet的add- 前面既然说过hashSet底层为hashMap 那么我们看一下常用方法的调用```javaprivate transient HashMap<E,Object> map;public boolean add(E e) {return map.put(e, PRESENT)==null;}可知调用的是map的put方法,那么这个map是从哪里来的?前面底层的代码中,有一个初map的定义,实际上还是hashMap,那么其实add方法底层是调用的hashMap的put方法,这点就没有什么疑问了
hashSet的add-hashMap的put
跟随上一个topic的节奏,下面我们进入hashMap的put方法去探究
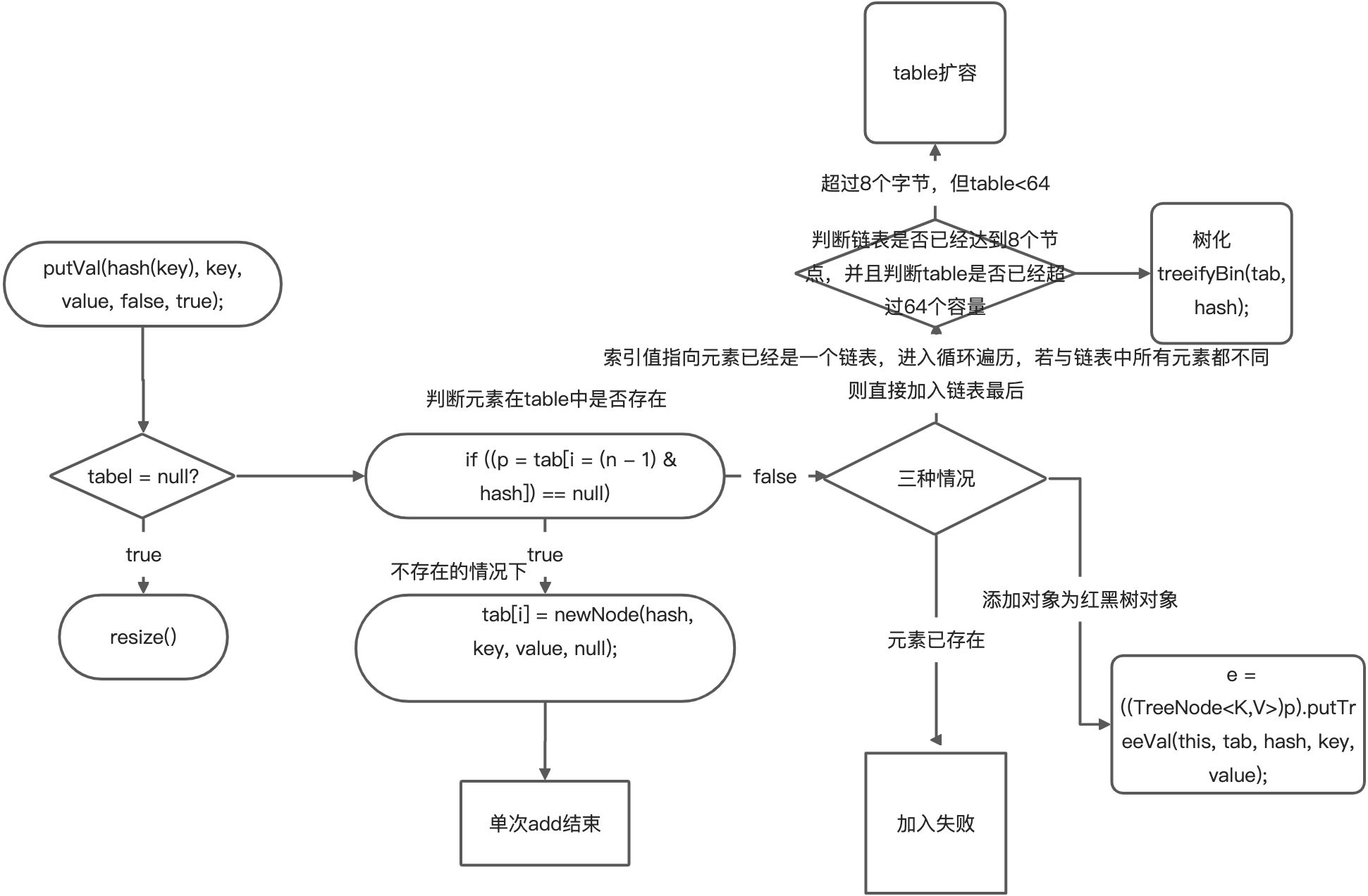
进入之前,首先看一下都传入put方法哪些参数 E e 其实就是我们进行add的元素 PRESENT 有点意思 其实是上面定义的一个对象常量,当作常量理解即可 // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); public boolean add(E e) { return map.put(e, PRESENT)==null; } ---------------- 来到 hashMap类下的put方法 K key 是什么? 是add进来的元素,只不过形参名字发生了变化 V value 是什么? 上面说的那个 PRESENT 常量 public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } ---------------- 然后接着追之前 有一个hash()方法,来看一眼 入参 为 add加入进来的元素对象, 如果为空就不进行运算,直接为0,否则拿到key的hashcode 按位异或 无符号位移16位 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } ----------------- ok 接下来我们要看 putVal方法了,这下才是难得地方 /** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table; 第一次添加 table 只被声明而未被赋值 /** * Implements Map.put and related methods. * * @param hash add元素经过hash算法取得的hash值 * @param key 要add的元素本身 * @param value PRESENT 常量 * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 这下面定义的是辅助变量 Node<K,V>[] tab; Node<K,V> p; int n, i; // 如果 table == null 或者 tab 的大小为0,则触发第一次扩容,扩容为16个空间的 node节点数组 if ((tab = table) == null || (n = tab.length) == 0) // 首先他会去判断table是否为空,table是hashMap中声明的一个数组 这个数组的元素为 Node<k,v>节点对象构成 // 第一次添加元素时 table 只被声明而未被赋值 table 为null 满足条件 ,直接进行扩容 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }hashMap初始化后的第一次扩容
第一次添加元素的时候的debug截图
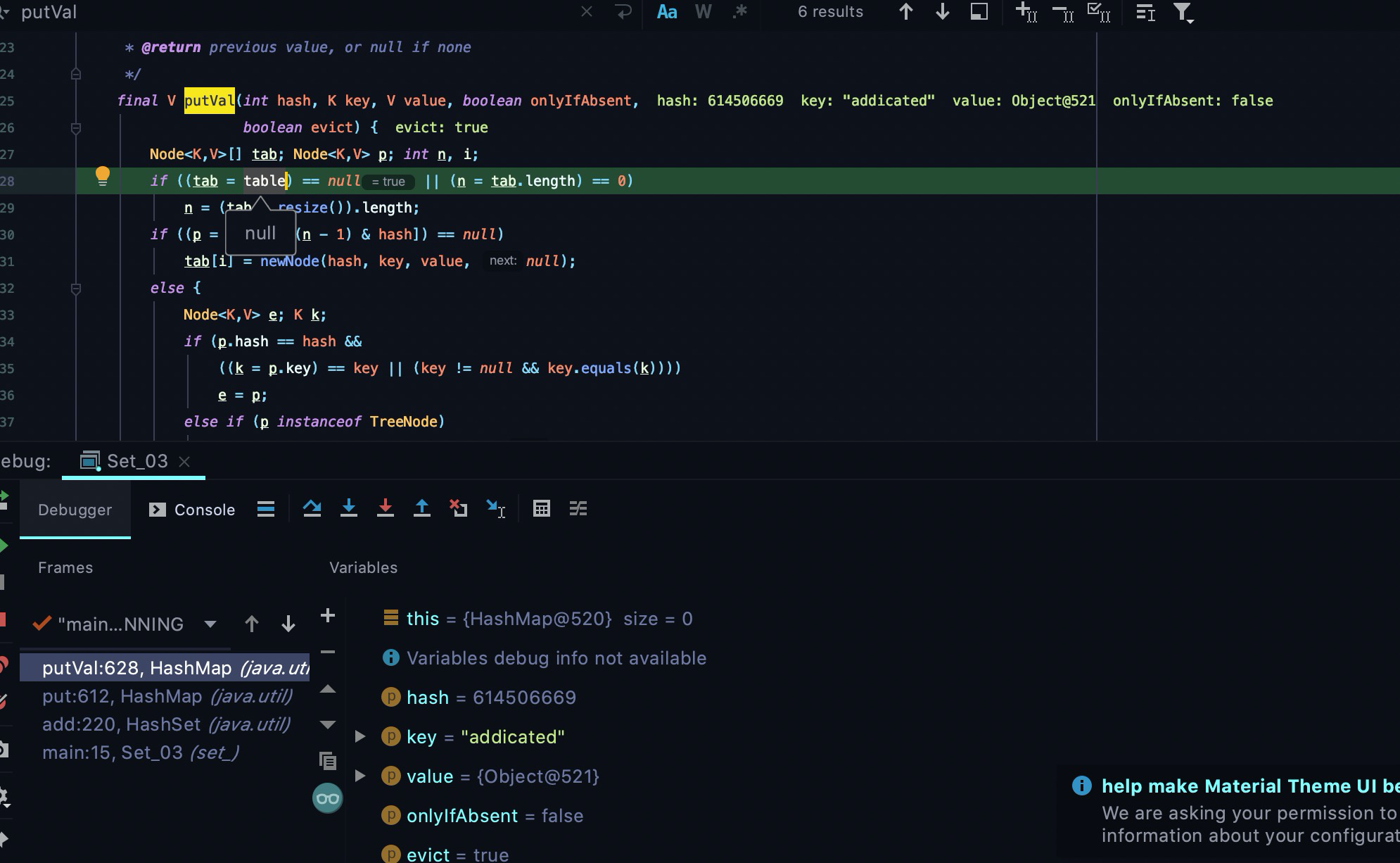 可以看到table为null,满足第一次添加元素扩容条件
可以看到table为null,满足第一次添加元素扩容条件- 往下走代码
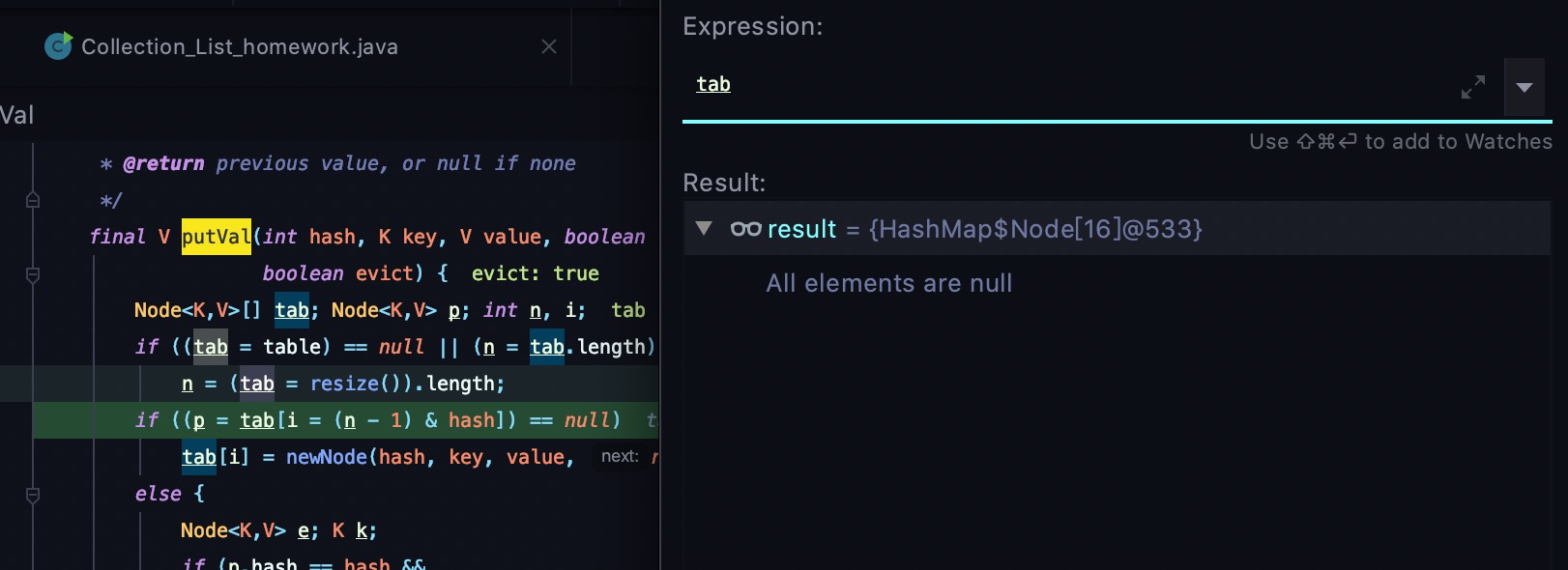
-
hashMap扩容添加table中已存在的元素
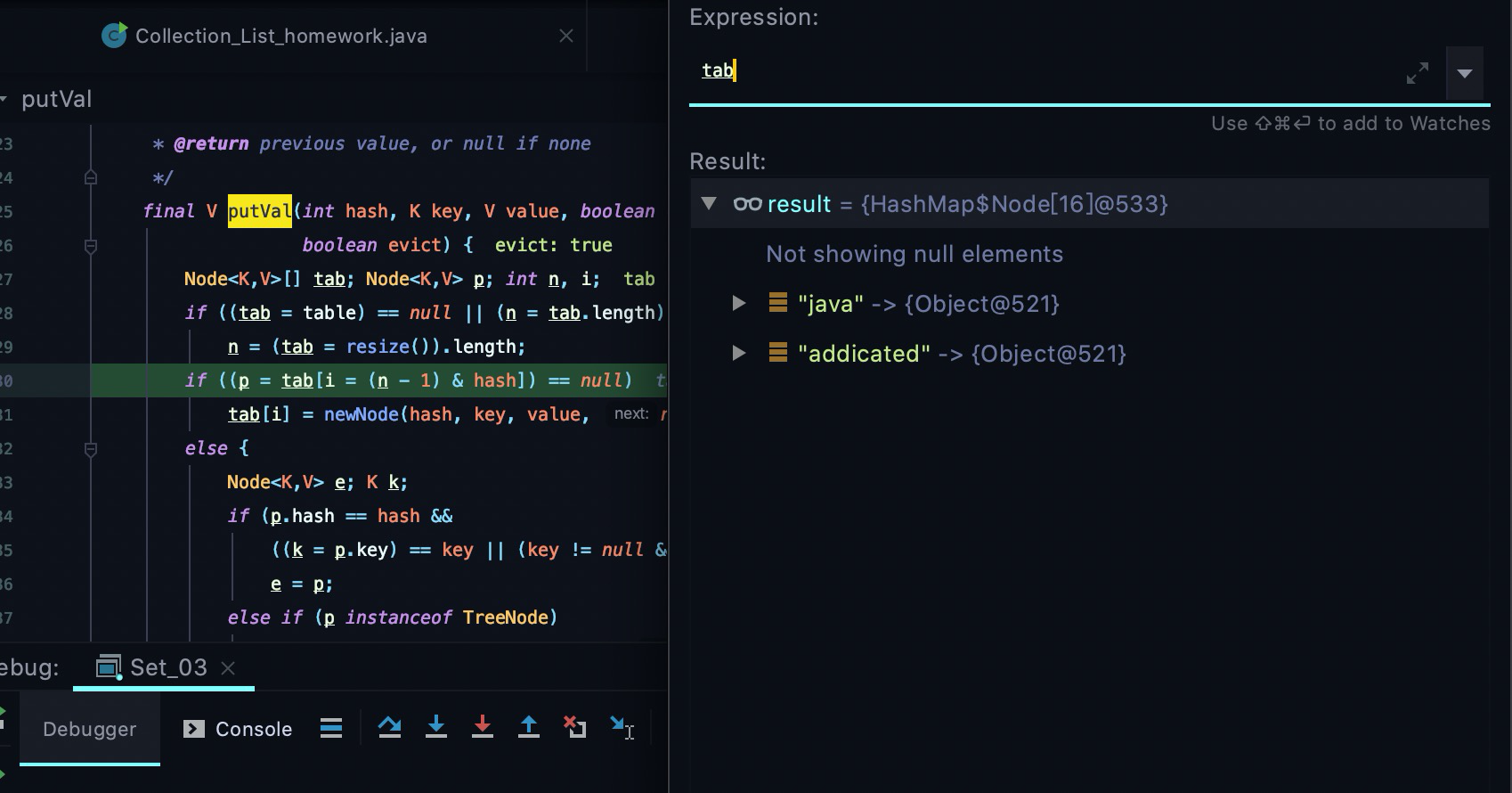
可以看到当前table中存在两个元素 java, addicated,然后我接着向里面添加addicated ,结论肯定是添加不了,但是我们需要关注发生了什么。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 1 根据key 得到hash 去计算该key应该存放到table表的的哪个索引位置 // 并把这个位置的对象 赋给p // 2 判断p 是否为null // 2。1 如果p为null 表示还没有存放过数据,就创建一个 Node(key="addicated",value=PRESENT) // 2。2 否则 就放在该位置 tab[i] = newNode(hash, key, value, null); // (n-1) & hash 这行代码先执行, n 为前面拿到的table长度,-1 取余hash得到索引 // 然后 tab[索引值] 拿到对应的 元素,如果元素不为空,则说明这个索引值下面已经存在元素 进入else分支 if ((p = tab[i = (n - 1) & hash]) == null) // 为空 则直接添加进去 tab[i] = newNode(hash, key, value, null); else { // 进入else 分支说明 p 当前索引存在元素 p, // 局部变量声明,未赋值为null Node<K,V> e; K k; // 如果当前索引位置对应的链表的第一个元素和 准备添加的key(元素)的hash值一样 // 并且满足 下面两个条件之一 // 1 。准备加入的key(元素) 和 p 指向的node节点的key 是同一个对象 // 2 。p指向的node节点 的key的equals() 和准备加入的key比较后相同 // 就不能加入, if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 再判断 p 是否为一颗红黑树, // 如果 p 是一颗红黑树,就调用 putTreeVal 来进行添加 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { w// 如果table对应索引位置,已经是一个链表,就使用for循环进行比较 // 1 依次和该链表的每一个元素比较后都不相同 , 则加入到该链表的最后 // 注意在吧元素添加到链表后,立即判断,该链表是否已经达到 8 个节点 // 如果达到就调用 treeif'yBin() 对当前这个链表进行树化 转换成红黑树 // 注意,在转成红黑树时,进行一个判断,如果该table数组的大小 < 64 则先进行扩容 //if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); // 只有上面条件不成立的时候,才进行树化,转换成红黑树。 // 2 依次比较的过程中,如果有相同的情况,就直接break for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) // size 是没加入一个节点 node size都会 ++ 不管是在 tab中还是在链表上 resize(); afterNodeInsertion(evict); // 这是一个空方法,主要是留给hashmap的子类来去实现 return null; // 返回一个空则代表添加成功了,否则则是失败 }hashSet 扩容与树化机制
hashSet底层是hashMap 第一次添加时,table数组扩容到16,
临界值(threshold) 是 16*加载因子 (loadFactor) 是0。75 =12- 如果table数组使用到了临界值 12 ,就会扩容到16__2 -32,新的临界值就是32 0。75
依次类推 java8中,如果一条链表元素个数到达 TREEIFY_THRESHOLD 默认为8
平切table的大小 >= MIN_TREEIFY_CAPACIty 默认64
就会进行树化,转换成红黑树,否则依然采用数组的扩容机制hashSet的扩容因子为什么是0.75f?
简单来说是为了防止元素发生碰撞,也就是发生重复导致性能,是一种时间与空间上的取舍。下见链接
https://www.cnblogs.com/DarrenChan/p/8854859.html
linkedHashSet
1 linkedHashSet 是hashSet的子类
2 linkedHashset底层是一个linkedHashMap 底层维护了一个数组 + 双向链表
3 linkedHashSet 根据元素的hashcode 值来决定元素的存储位置,同时使用链表维护元素的次序,使得元素看起来像是以插入顺序保存的
4 linkedHashSet不允许添加重复元素
说明
在linkedHashSet中维护了一个hash表和双向链表 linkedHashSet 有set和tail
每一个节点有 pre 和 next 属性,这样可以形成双向链表
在添加一个元素时,先求hash值,再求索引。确定该元素在hashtable的位置,然后添加的元素加入到双向链表(如果已经存在,则不添加,原则与hashset一致
这样的话 linkedHashSet 也能确保插入顺序和遍历顺序一致
�红黑树相关操作
还未学到,待续

若有收获,就点个赞吧
0 人点赞
