- 本篇深度不深
redis缓存的使用极大提升了应用程序的性能和效率,特别是查询方面,但同时也会有一些问题,其中最严重的就是数据一致性的问题。
严格来讲,这个问题无解,如果对数据一致性要求很高,就不应该用缓存
另外就是面试常问的,缓存穿透,缓存雪崩,缓存击穿,这些指代什么,已经如何去解决。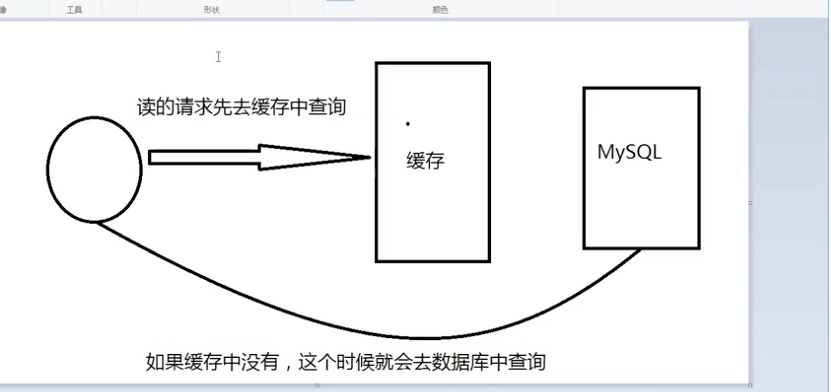
缓存穿透 主要原因,查不到
概念
布隆过滤器是一种数据结构,随多有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层数据库的查询压力
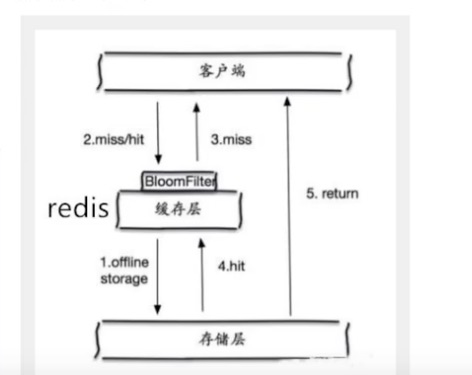
- 但是这种方式存在问题
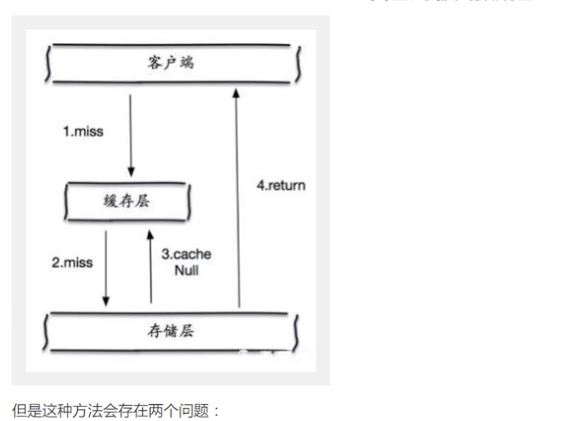
- 如果空值能够被缓存起来,就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键
即使对空值设定了过期时间,还是会存在缓冲层和存储层的数据会有一段时间窗口不一致,这对需要保持一致性的业务会有影响
缓存击穿 主要原因,查的太多了
概念
从缓存层面来看,没有设置过期时间,所以不会出现热点key 过期后产生的问题
加互斥锁
分布式锁: 使用分布式锁,保证对于每个key同时只有一个线程去查询后段服务,其他线程没有获得分布式锁的权限,因此需要等待即可,这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验非常大
缓存雪崩
概念
- 指在某一个时间段,缓存集中过期失效,redis宕机
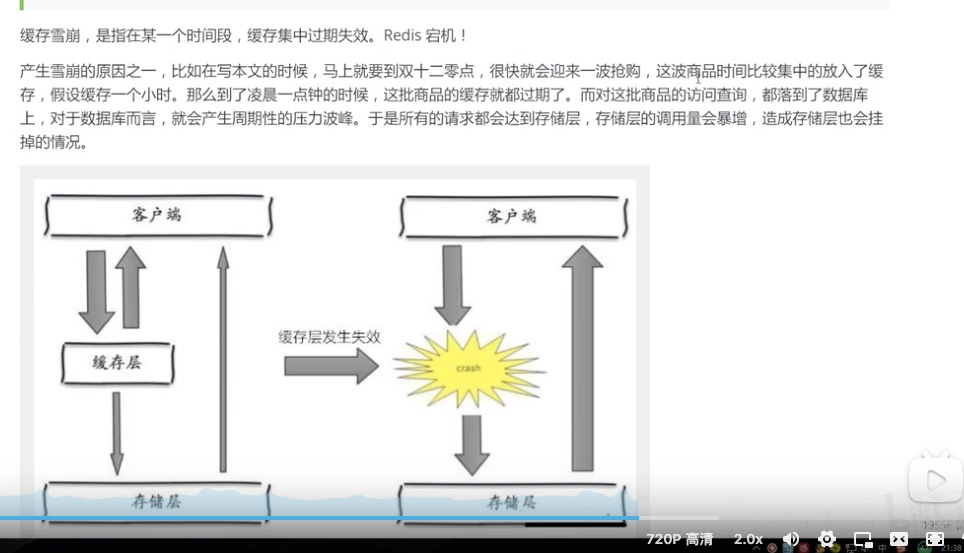
集中过期其实不是非常致命,最致命的是缓存服务器的某个节点宕机或者断网,因为自然形成的雪崩,一定是在某个时间段集中创建缓存,这个时候db也是可以顶住的。无非是对db造成周期性压力而已。
而缓存服务节点的宕机,对数据库服务器造成的压力是不可与之的,很有可能瞬间吧db压垮
解决方案
redis高可用

若有收获,就点个赞吧
0 人点赞
