1.复杂度
算法是用于解决特定问题的一系列的执行步骤
使用不同的算法,解决同一个问题,效率可能会相差非常大
例如:求斐波那契额数 (注意:n是从0开始的)
/**
* 0 1 1 2 3 5 8 13 …
* 求斐波那契额数 函数表达式 f(n)=f(n-1)+f(n-2) n>2时 ; n<2时 f(1)=0 f(2)=1
* 使用递归算法,可以先求出函数表达式,直接套进去
*/
public static Integer fib1(Integer n) {if (n <= 1) {return n;}return fib1(n - 1) + fib1(n - 2);}
/**
* 0 1 1 2 3 5 8 13 …
* 使用for循环 n从0开始
*/
public static Integer fib2(Integer n) {if (n == 1) {return 0;}Integer first = 0;Integer second = 1;//第n个数等于需要加n-1次for (int i = 0; i < n - 1; i++) {int sum = first + second;first = second;second = sum;}return second;}
综上对比,当n的数量大的时候,for循环方式要快很多
如何评判一个算法的好坏?
如果单从执行效率上进行评估,可能会想到这么一种解决方案
比较不同算法对同一组输入的执行处理时间
这种方案也叫作:事后统计法
一般从以下维度来评估算法的优劣
正确性、可读性、健壮性(对不合理输入的反应能力)
时间复杂度(time complexity):估算程序指令的执行次数(执行时间)
空间复杂度(space complexity):估算所需占用的存储空间
大O表示法(Big O)
一般用大O表示法来描述复杂度,它表示的是数据规模n对应的复杂度
时间复杂度:
忽略常数、系数、低阶、
9 >>> O(1)
2n+3 >>> O(n)
n²+2n+6 >>>O(n²)
4n³+3n²+22n+100 >>>O(n³)
log5(n) >>>log(n)
常见复杂度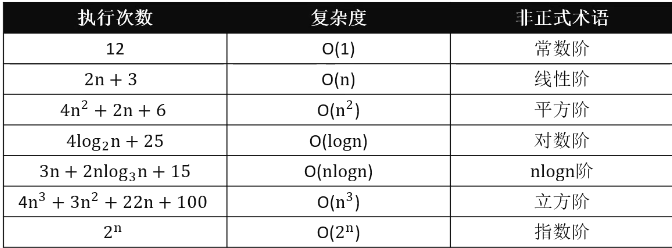
O(1)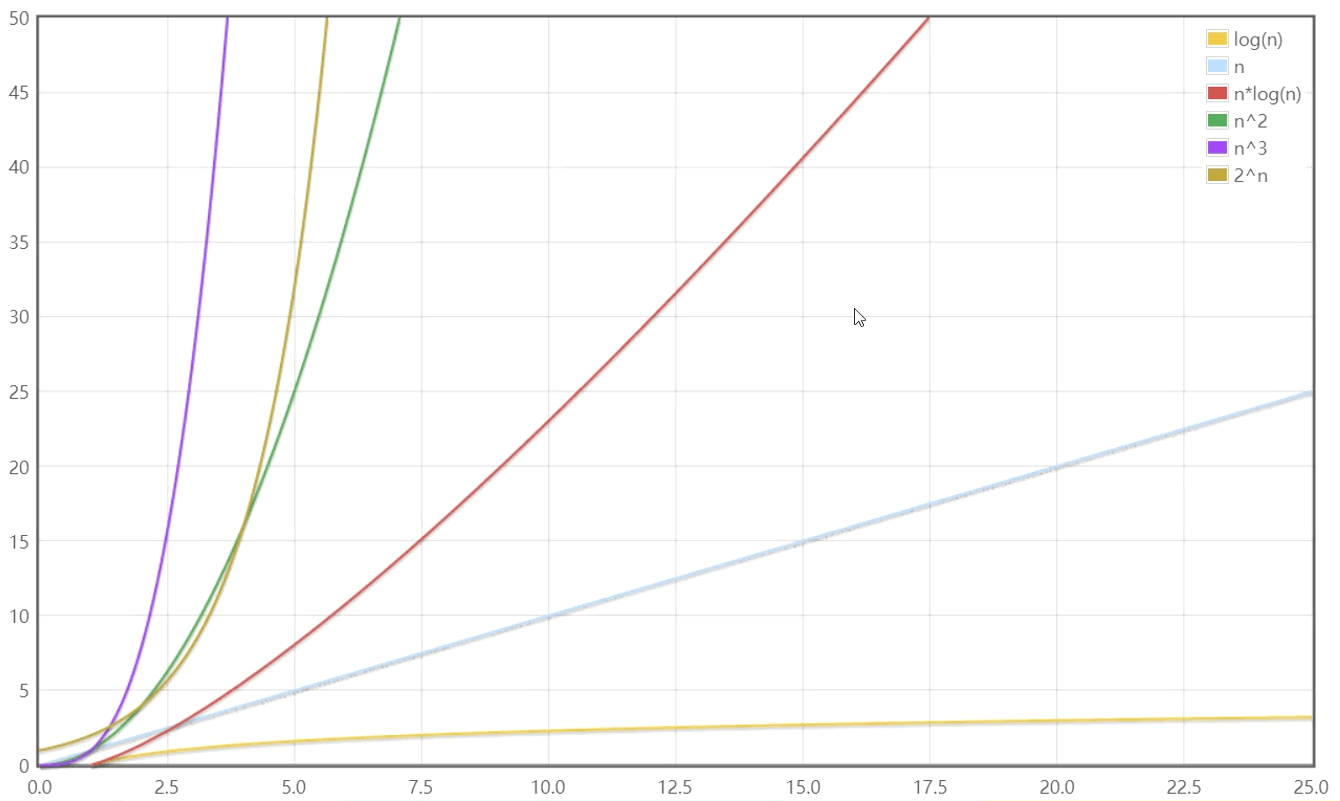 空间复杂福
空间复杂福
计算斐波那契数递归算法的时间复杂度:
例如:计算n=5的值
1+2+4+8=2^0+2^1+2^2+2^3=2^4-1=2^(n-1)-1
所以时间复杂度是O(2^n)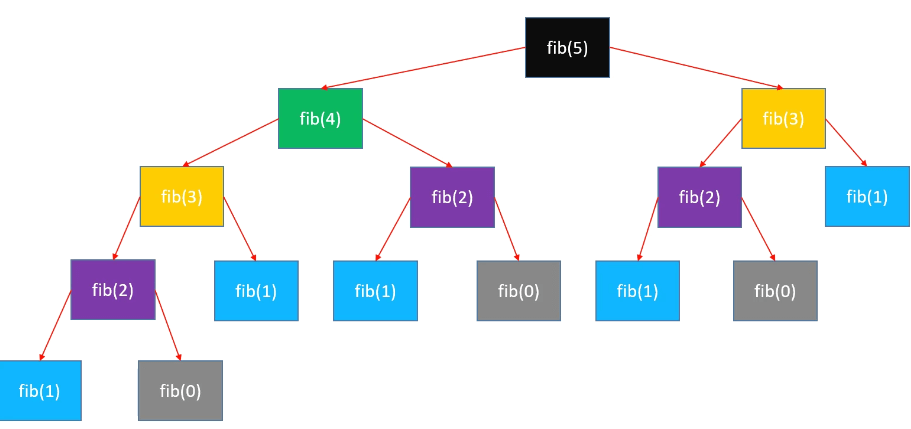
每次执行一次函数都是做一次加法,只需要计算调用多少次就行 有的时候算法之间的差距,往往比硬件方面的差距还要大
有的时候算法之间的差距,往往比硬件方面的差距还要大
算法优化的方向:
用尽量少的存储空间
用尽量少的执行步骤(执行时间)
根据情况可以空间换时间,时间换空间
多规模数据的情况
leetcode:一个用于练习算法的好网站
https://leetcode.com
https://leetcode-cn.com
2.动态数组
什么是数据结构?
数据结构是计算机存储,组织数据的方式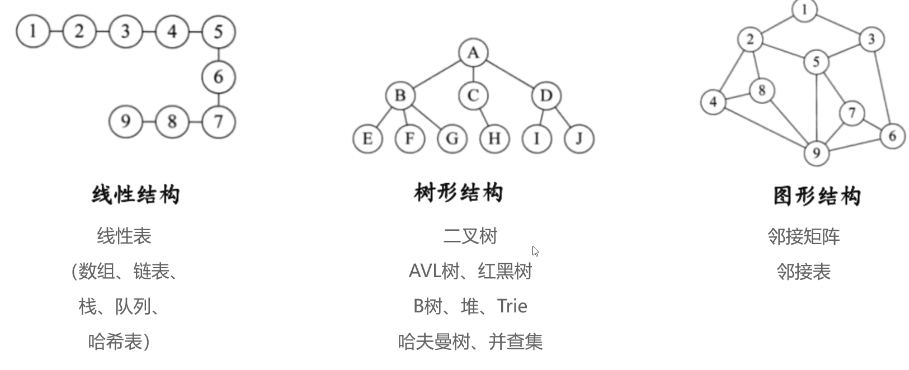
线性表是具有n个相同类型元素的有限序列(n>=0)
数组(Array)
数组是一种顺序存储的线性表,所有的元素内存地址都是连续的
int[] array =new int[]{11,22,33};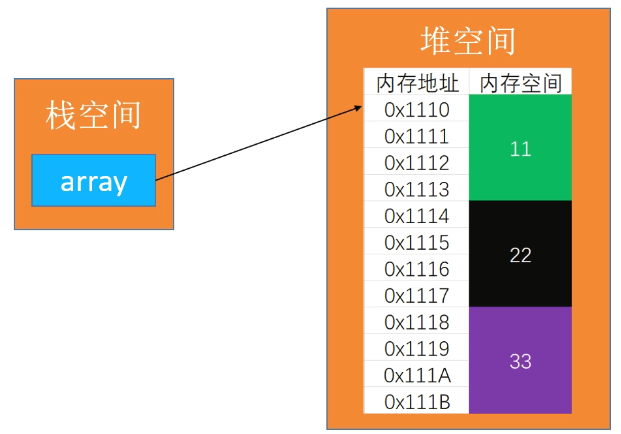
在很多变成语言中,数组都有个致命的缺点,无法动态修改容量,需要使用动态数组。
动态数组(Dynamic Array)接口设计:
需要的常量:size(数组长度)、elements(声明的数组)、数组默认长度等
add方法原理:
/*** 添加元素到尾部* @param element*/public void add(int element) {elements[size++] = element;}
remove方法原理:

/*** 移除该索引的元素* @param index* @return*/public int remove(int index) {if (index < 0 || index >= size) {throw new IndexOutOfBoundsException("Index:" + index + ",Size:" + size);}for (int i = index; i < size - 1; i++) {elements[i] = elements[i + 1];}size--;return 1;}
add根据索引插入数据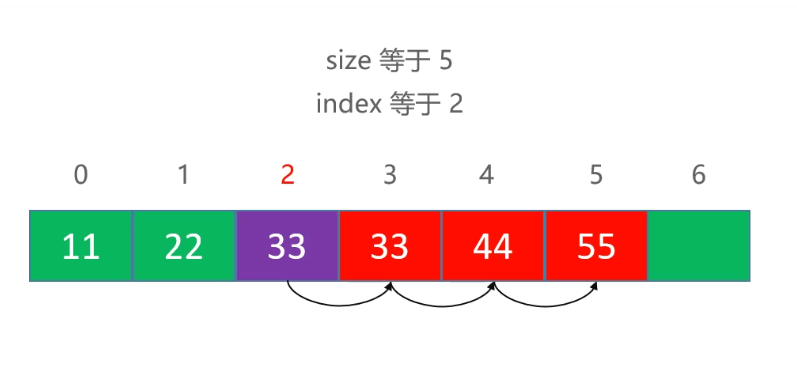
/*** 根据索引添加元素** @param element*/public void add(int index, int element) {if (index < 0 || index >size) {throw new IndexOutOfBoundsException();}for (int i = size; i > index; i--) {elements[i] = elements[i - 1];}elements[index] = element;size++;}
动态扩容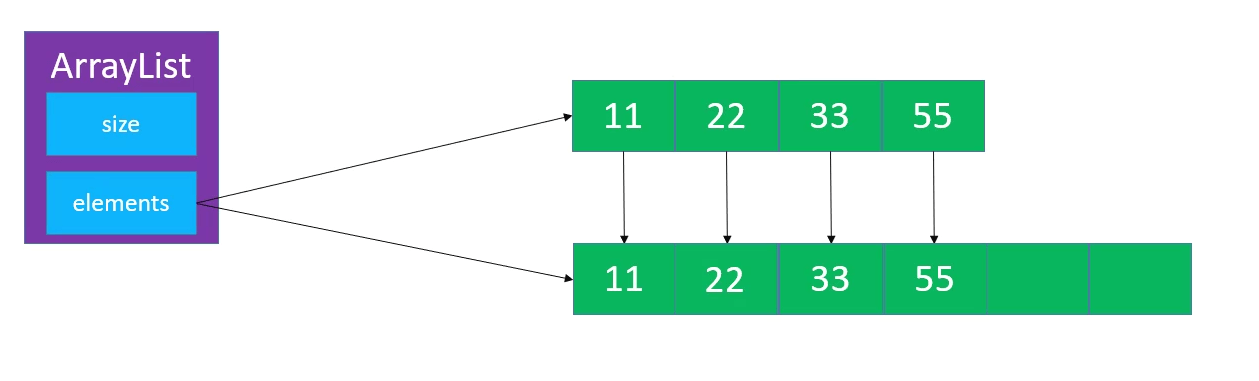
当数组的长度不足的时候,需要扩容,否则会报错,Arraylist扩容的长度为原长度的1.5倍
两个方法需要使用扩容:
在list后面添加数据:add(String element)
根据索引插入数据:add(int index,String element)
/*** 添加元素到尾部** @param element*/public void add(int element) {add(size,element);}/*** 根据索引添加元素* @param element*/public void add(int index, int element) {rangCheckForAdd(index);ensureCapacity(size+1);for (int i = size; i > index; i--) {elements[i] = elements[i - 1];}elements[index] = element;size++;}/*** 检查添加时候的索引判断,因为添加的时候索引可以等于list的长度* @param index*/private void rangCheckForAdd(int index){if (index < 0 || index > size) {throw new IndexOutOfBoundsException("Index:" + index + ",Size:" + size);}}/*** 数组扩容* @param capacity*/private void ensureCapacity(int capacity) {int oldCapacity = elements.length;if(oldCapacity>=capacity){ return;}int newCapacity=oldCapacity+(oldCapacity>>1);int[] newElements=new int[newCapacity];for (int i = 0; i < oldCapacity; i++) {newElements[i] = elements[i];}elements=newElements;}
动态数组加泛型
使用泛型技术可以让动态数组更加通用,可以存放任何数据类型
package com.ruoyi.Algorithms.f2动态数组;/*** 自己手动写一个动态数组*/public class ArrayList<E> {/*** 元素的数量*/private int size;/*** 所有的元素*/private E[] elements;private static final int DEFAULT_CAPACITY = 10;private static final int ELEMENT_NOT_FOUND = -1;/*** 构造方法初始化数组,如果小于10则为大小为10** @param capacity*/public ArrayList(int capacity) {capacity = Math.max(capacity, DEFAULT_CAPACITY);elements = (E[]) new Object[capacity];}/*** 构造方法初始化数组*/public ArrayList() {this(DEFAULT_CAPACITY);}/*** 添加元素到尾部** @param element*/public void add(E element) {add(size,element);}/*** 根据索引添加元素* @param element*/public void add(int index, E element) {rangCheckForAdd(index);ensureCapacity(size+1);for (int i = size; i > index; i--) {elements[i] = elements[i - 1];}elements[index] =element;size++;}/*** 数组扩容* @param capacity*/private void ensureCapacity(int capacity) {int oldCapacity = elements.length;if(oldCapacity>=capacity){ return;}int newCapacity=oldCapacity+(oldCapacity>>1);E[] newElements= (E[]) new Object[newCapacity];for (int i = 0; i < oldCapacity; i++) {newElements[i] = elements[i];}elements=newElements;}/*** 设置index位置的元素** @param index* @param element* @return*/public E set(int index, E element) {rangCheck(index);E oldelement = elements[index];elements[index] = element;return oldelement;}/*** 获取index位置的元素** @param index* @return*/public E get(int index) {if (index < 0 || index >= size) {throw new IndexOutOfBoundsException("Index:" + index + ",Size:" + size);}return elements[index];}/*** 移除该索引的元素** @param index* @return*/public int remove(int index) {rangCheck(index);for (int i = index; i < size - 1; i++) {elements[i] = elements[i + 1];}size--;return 1;}/*** 查看元素的索引** @param element* @return*/public int indexOf(E element) {for (int i = 0; i < elements.length; i++) {if (elements[i] == element) return i;}return ELEMENT_NOT_FOUND;}/*** 是否包含这个元素** @param element* @return*/public boolean contains(E element) {return indexOf(element) != ELEMENT_NOT_FOUND;}/*** 是否为空** @return*/public boolean isEmpty() {return size == 0;}/*** 清除所有元素** @return*/public void clear() {size = 0;}public int size() {return size;}/*** 打印数组的元素*/@Overridepublic String toString() {StringBuilder sb = new StringBuilder();sb.append("size=").append(size).append(",[");for (int i = 0; i < size; i++) {sb.append(elements[i]);if (i != size - 1) {sb.append(",");}}sb.append("]");return sb.toString();}/*** 检查范围* @param index*/private void rangCheck(int index){if (index < 0 || index >= size) {throw new IndexOutOfBoundsException("Index:" + index + ",Size:" + size);}}/*** 检查添加时候的索引判断,因为添加的时候索引可以等于list的长度* @param index*/private void rangCheckForAdd(int index){if (index < 0 || index > size) {throw new IndexOutOfBoundsException("Index:" + index + ",Size:" + size);}}}
对象数组
数组里面的空间都是连续的,不是存储的对象,而是存储的内存地址,
可以节省空间,当需要删除对象的时候,直接清空数组的引用就行了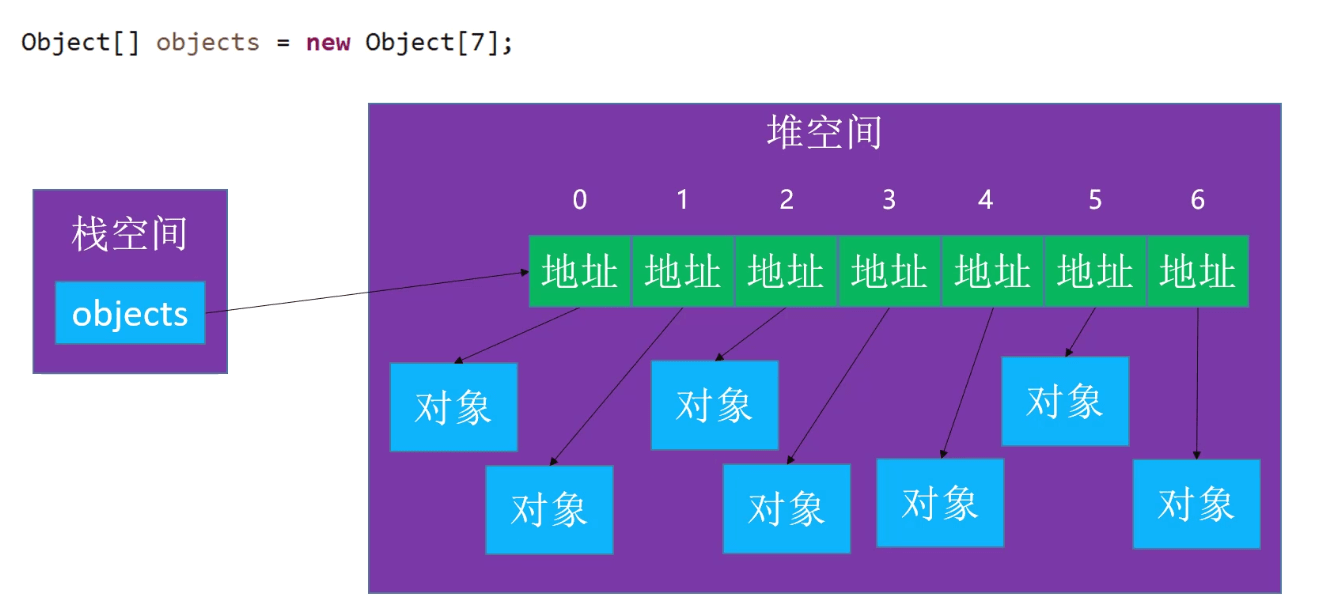
clear细节
如果像存int类型那样直接把size=0,是行不通的,因为这样清空之后继续add,原来的对象还是存在的,占内存的,会导致浪费内存。
/***清除所有元素*/public void clear(){for(int i=0;i<size;i++){elements[i]=null;}size=0;}
直接设置为空,jvm会销毁对象
remove需要注意的细节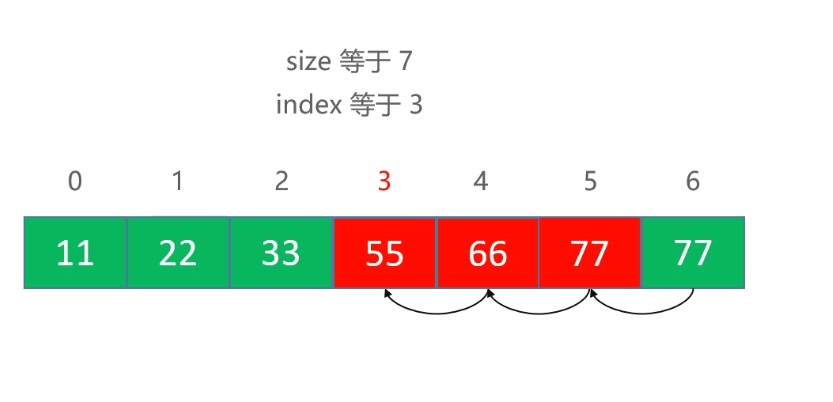
remove位置的值不需要清空,直接被后面的值覆盖,但是最后一个元素必须要清空,因为引用还存在
public E remove(int index) {rangCheck(index);E old=elements[index];for (int i = index; i < size - 1; i++) {elements[i] = elements[i + 1];}elements[--size]=null;//必须要清空最后一个return old;}
关于equals方法
比较的时候要注意用equals方法
/*** 查看元素的索引** @param element* @return*/public int indexOf(E element) {for (int i = 0; i < elements.length; i++) {if (elements[i].equals(element)) return i;}return ELEMENT_NOT_FOUND;}
null值的处理
添加的方法不用处理
indexof方法需要改变:
public int indexOf(E element) {if(){}for (int i = 0; i < elements.length; i++) {if (elements[i].equals(element)) return i;}return ELEMENT_NOT_FOUND;}
ArrayList源码分析
~
3.链表
1.简介
动态数组有一个明显的缺点,扩容的时候会导致内存浪费,导致很多内存用不上、
链表可以办到这一点,用多少内存就申请多少内存
链表是一种链式存储的线性表,所有元素的内存地址不一定是连续的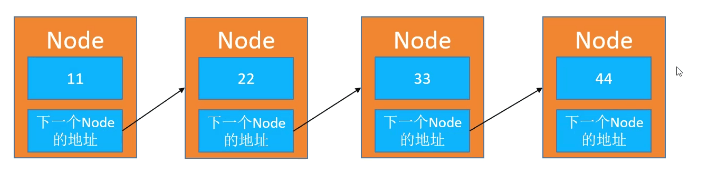
2.clear()清空元素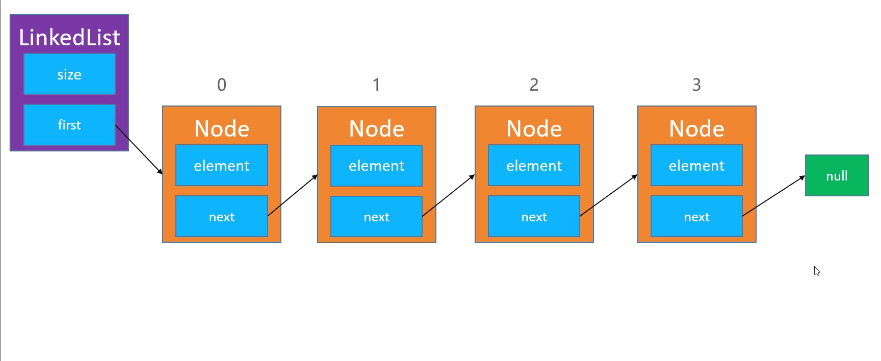
直接first=null,即可,让第一个节点为空,就无法继续寻找别的节点
3.添加元素
/*** 从该索引插入一个元素** @param index* @param element*/public void add(int index, E element) {if (index == 0) {first = new Node<>(element, first);} else {Node<E> prev = node(index - 1);prev.next = new Node<>(element, prev.next);}size++;}/*** 从后面插入一个元素** @param element*/public void add(E element) {// Node<E> node = node(size - 1);//获取最后一个元素// node.next = new Node<>(element, null);add(size,element);}
4.删除方法
/*** 删除一个元素* 返回被删掉的那个元素* @param index* @return E*/public E remove(int index) {E old;if (index == 0) {old=first.element;first = first.next;} else {Node<E> prev = node(index - 1);old= prev.next.element;prev.next = prev.next.next;}size--;return old;}
4.练习:删除链表中的节点_力扣:237题请编写一个函数,使其可以删除某个链表中给定的(非末尾)节点。传入函数的唯一参数为 要被删除的节点 。现有一个链表 — head = [4,5,1,9],它可以表示为:4—->5—->1—->9示例 1:输入:head = [4,5,1,9], node = 5输出:[4,1,9]解释:给定你链表中值为5的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9._
public class Exercises {public class ListNode {int val;ListNode next;ListNode(int x) {val = x;}}class Solution {public void deleteNode(ListNode node) {node.val=node.next.val;node.next=node.next.next;}}}
5.反转链表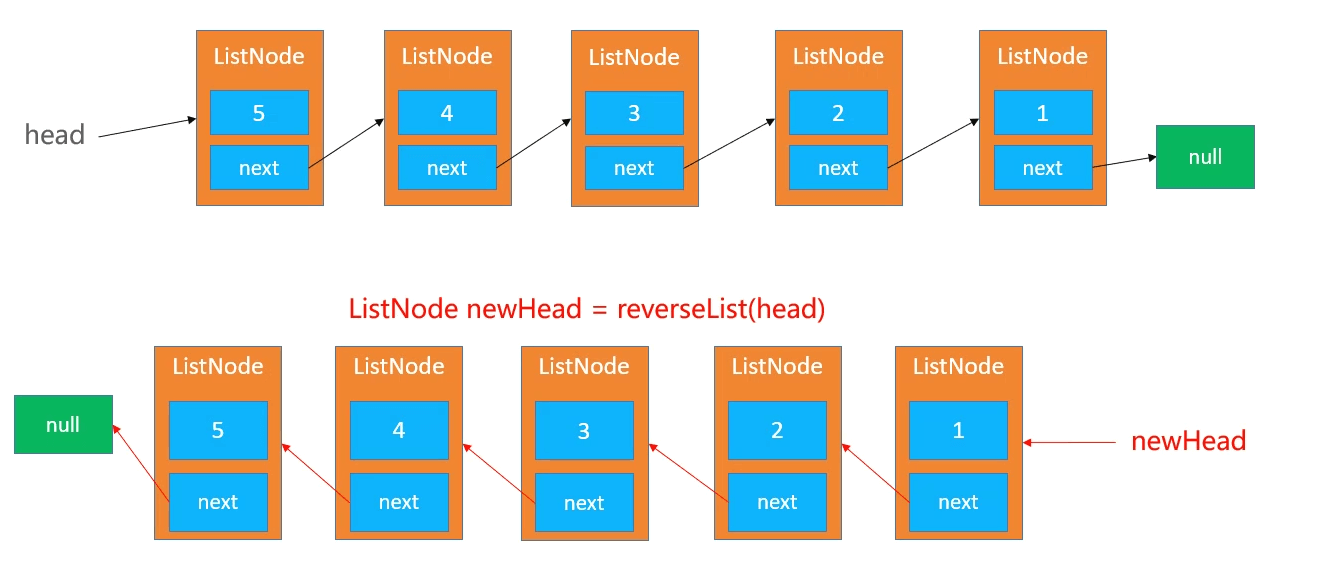
6.判断一个链表是否有环?
public boolean hasCycle(ListNode head) {if (head == null || head.next == null) {return false;}ListNode slow = head;ListNode fast = head.next;while (fast != null && fast.next != null) {slow = slow.next;fast = fast.next.next;if (slow == fast) {return true;}}return false;}
注意fast != null && fast.next != null两个不能省略其中一个;
否则会报空指针异常;
7.虚拟头结点
有的时候为了让代码更加精简,统一所有节点的处理逻辑,可以考虑加一个虚拟头节点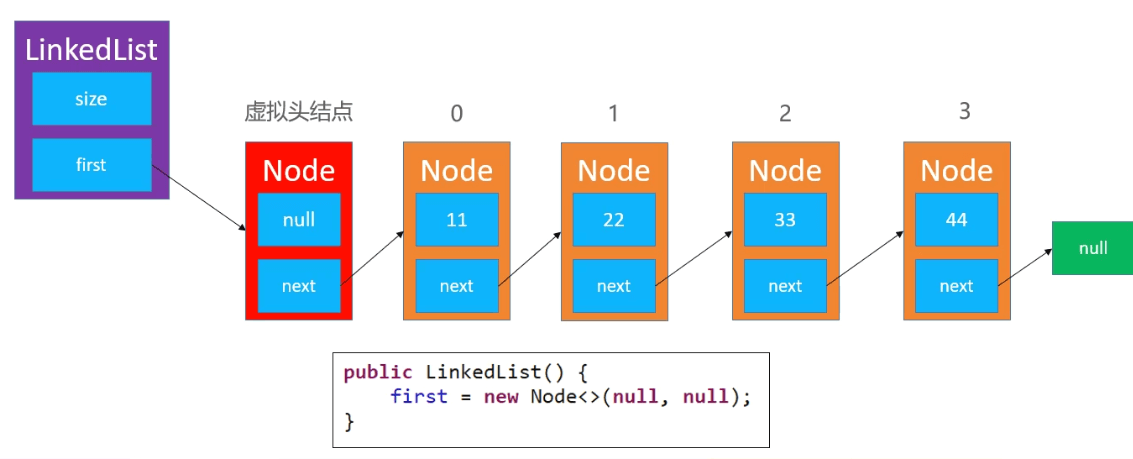
8.复杂度分析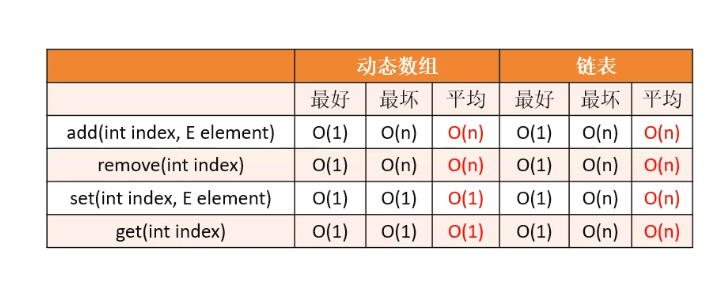
9.均摊复杂度
可以把扩容的那次操作的复杂度均摊到每次添加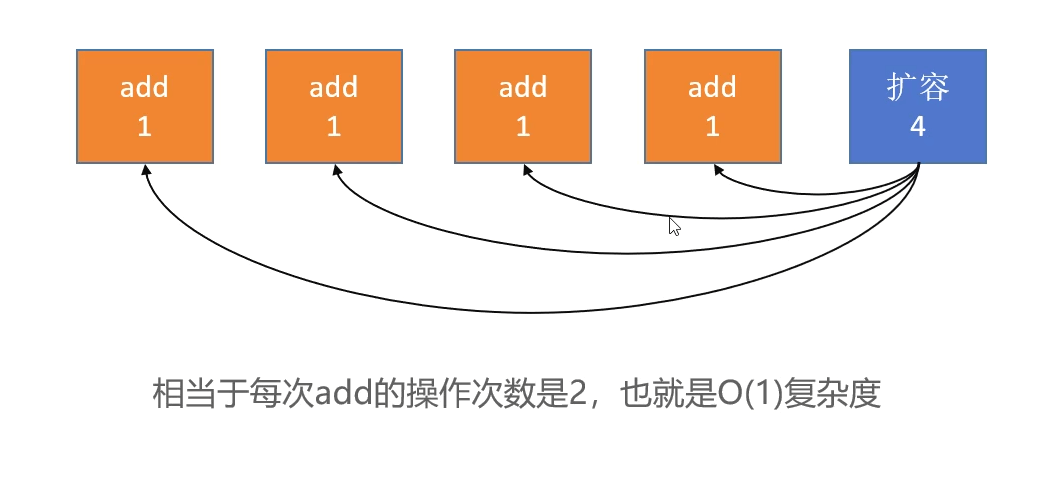
10.动态数组缩容
如果内存使用比较紧张,动态数组有比较多余的剩余空间,可以考虑进行缩容操作
/*** 进行缩容操作*/public void trim() {int capacity = elements.length;int newCapacity=capacity>>1;if (size>=(capacity)||capacity<=DEFAULT_CAPACITY) {//如果移除后的数组长度大于一半,并且数组的长度小于初始长度,无需操作return;}E[] newElements = (E[]) new Object[newCapacity];//新数组长度为原来的一半for (int i = 0; i < size; i++) {newElements[i] = elements[i];}elements = newElements;}
复杂度震荡:
如果扩容倍数、缩容时机设计不得当,有可能会导致复杂度震荡
扩大倍数和缩小倍数不要一样,否则在临界点进行添加操作或者删除操作都会导致,频繁扩容和缩容
11.双向链表
使用双向链表可以提升链表的综合性能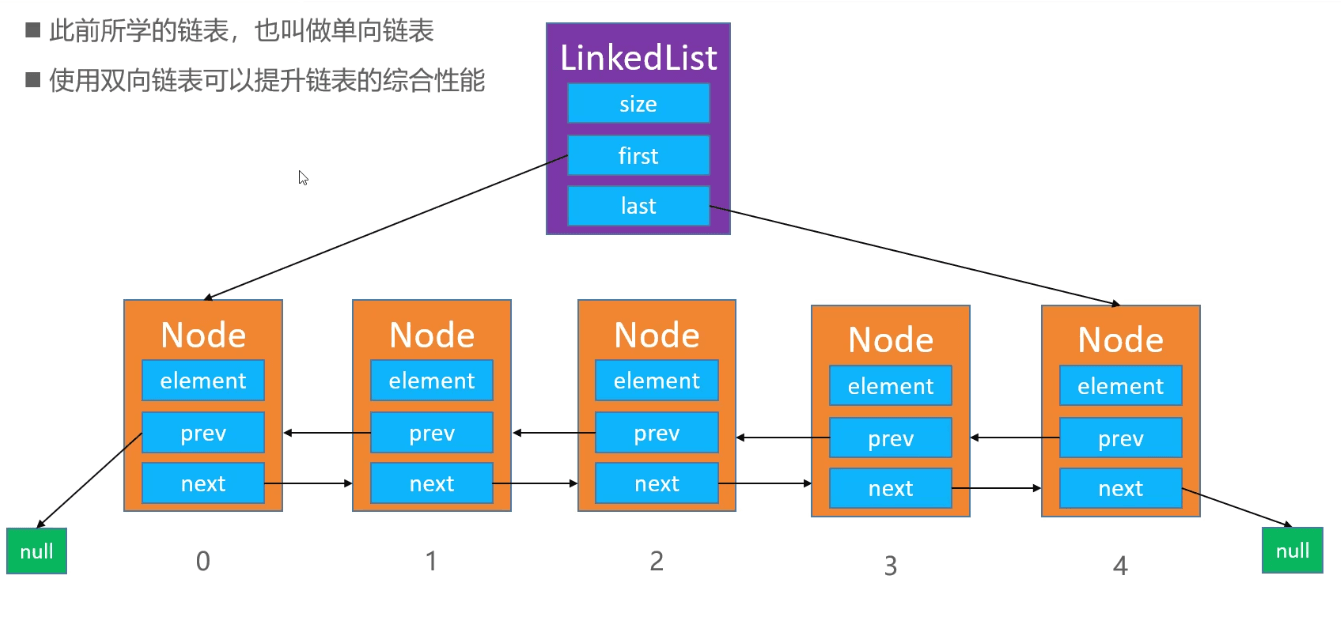
node方法:
/** 通过索引获得node节点**/private Node<E> node(int index) {rangCheck(index);if (index < (size >> 1)) { //如果索性小于长度的一半,就从头节点开始找Node<E> node = first;for (int i = 0; i < index; i++) {node = node.next;}return node;} else {//如果索引大于长度的一半,就从尾节点开始找Node<E> node=last;for (int i = size-1; i > index; i--) {node=node.prev;}return node;}}
clear方法:
public void clear() {size = 0;first = null;last = null;}
问题:first和last原来所指向的对象会被虚拟机回收吗?
答案:会被回收,因为在虚拟机中没有被gc root所指向的引用都会被回收,比如被局部变量指向的对象就是,list就是被局部变量指向的对象 first<—-linkedlist—->last
add方法:
注意:
如果插入的点是0索引,则前面的结点为空
如果插入的是最后的索引,则后面的结点为空
public void add(int index, E element) {if (index == size) {//如果插入的索引等于长度,则表示插入的是最后一个位置Node<E> prev =last;last = new Node<>(element, prev, null);prev.next=last;} else {Node<E> next = node(index);//获取当前元素Node<E> prev = next.prev;//获取前一个元素Node<E> newNode = new Node<E>(element, prev, next);next.prev = newNode;if (prev == null) {//如果当前结点的前一个节点为null,则表示插入的结点为0结点first = newNode;} else {prev.next = newNode;}}}
remove方法:
注意:跟add方法有点相似
如果插入的点是0索引,则前面的结点为空
如果插入的是最后的索引,则后面的结点为空
public void remove(int index) {Node<E> node = node(index);Node<E> next = node.next;Node<E> prev = node.prev;if (prev == null) {first = next;} else {prev.next = next;}if(next==null){last = prev;}else {next.prev = prev;}size--;}
12.总结
单向链表vs双向链表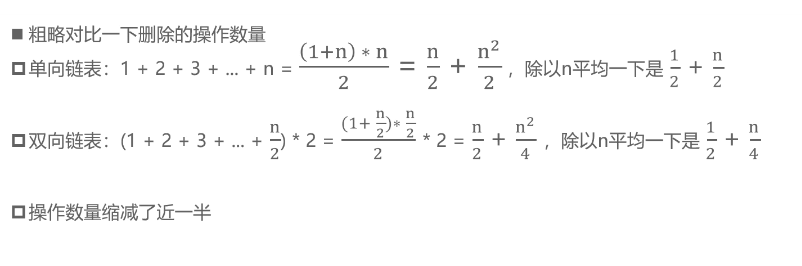
双向链表vs动态数组
动态数组:开辟、销毁内存空间的次数相对较少,但可能造成内存空间浪费(可以通过缩容解决)
双向链表:开辟、销毁内存空间的次数相对较多,但不会造成内存空间的浪费
如果频繁在尾部进行添加、删除操作,动态数组、双向链表均可选择
如果频繁在头部进行添加、删除操作,建议选择使用双向链表
如果有频繁的(在任意位置添加)添加、删除操作,建议使用双向链表
如果有频繁的查询操作(随机访问操作),建议选择使用动态数组
有了双向链表,单向链表是否就没有任何作用了?
并非如此,在哈希表的设计中就用到了双链表
13.源码分析
在源码中的删除代码是把每个节点都清空
因为在源码中有用到迭代器,迭代器引用某个结点的话会导致内存不会被回收
14.单向循环链表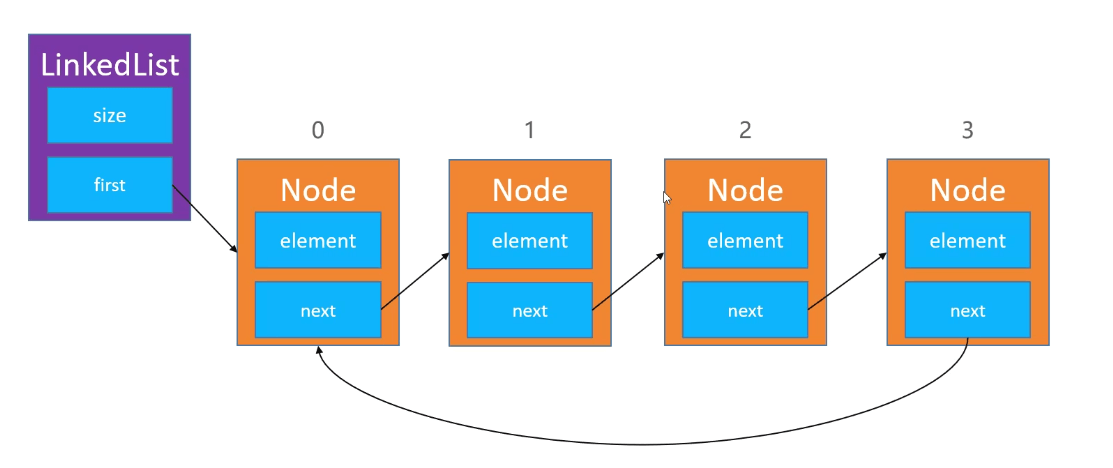
15.双向循环链表
只需要修改添加和修改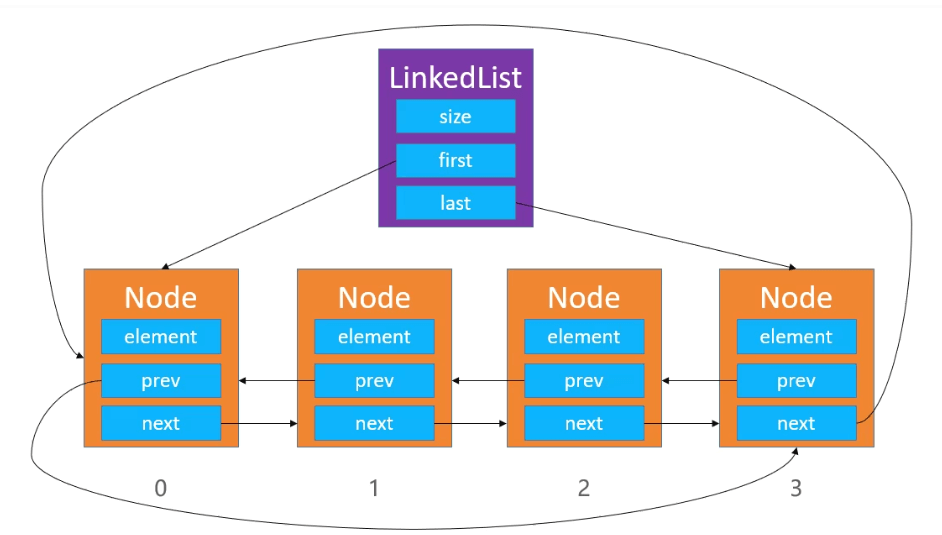
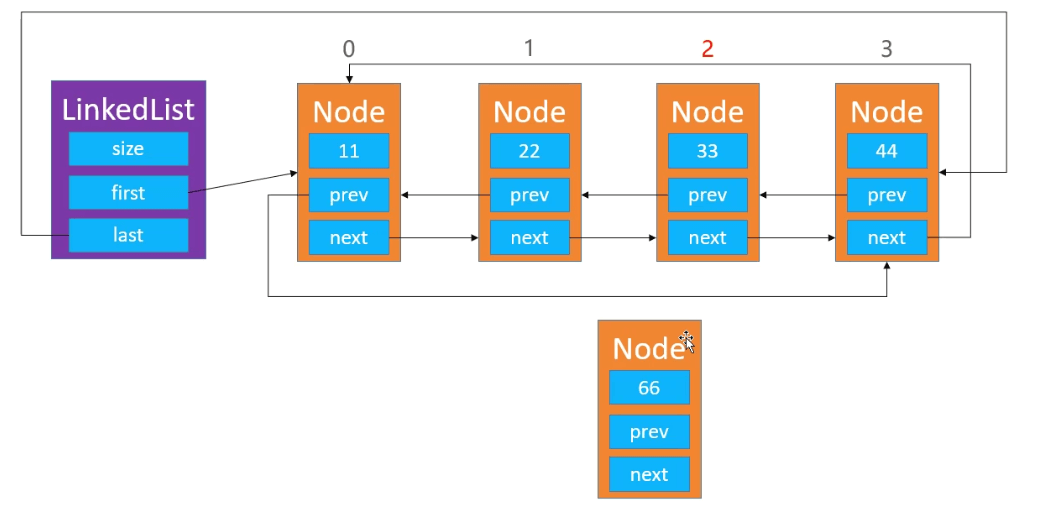
双向循环链表如果只有一个结点,那么他会自己指向自己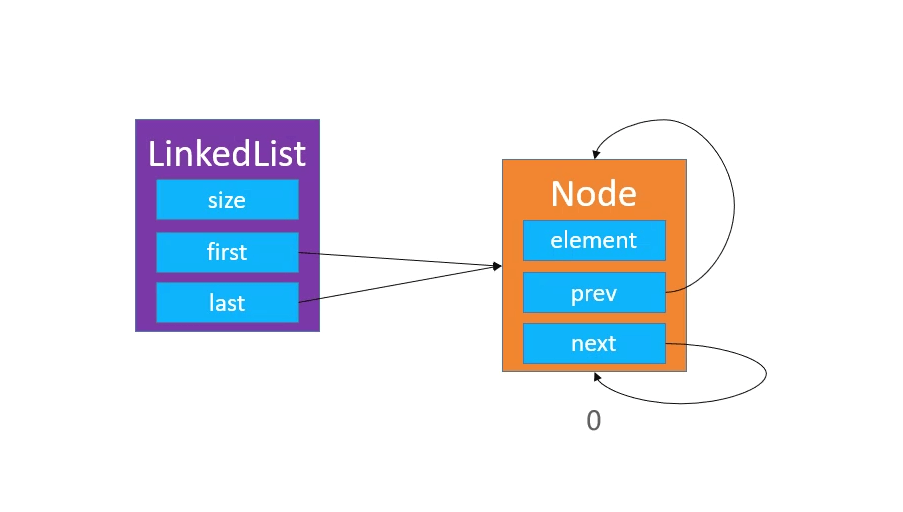
add方法:
需要注意的点:环形链表只有一个结点
public void add(int index, E element) {if (index == size) {//如果插入的索引等于长度,则表示插入的是最后一个位置,即从最后面添加Node<E> oldNode =last;last = new Node<>(element, oldNode, first);//新增的节点if(oldNode==null){ //说明这个链表是空链表first=last;last.next=last;last.prev=last;}else {//说明不是空链表oldNode.next=last;last.next=first;}} else {Node<E> next = node(index);//获取当前元素Node<E> prev = next.prev;//获取前一个元素Node<E> newNode = new Node<E>(element, prev, next);next.prev = newNode;if (prev == null) {//如果当前结点的前一个节点为null,则表示插入的结点为0结点first = newNode;} else {prev.next = newNode;}}size++;}
remove方法:
理解:因为环形链表是一个环,只有一个元素的时候需要特殊考虑,别的情况都是一样,头尾结点只需要指明头尾结点即可
public E remove(int index) {//至少有一个元素Node<E> node = node(index);Node<E> next = node.next;Node<E> prev = node.prev;if (size == 1) {first = null;last = null;} else {prev.next = next;next.prev = prev;if (node == first) {//则代表这是第一个元素first = next;}if (node.next == first) {//则代表这是最后一个元素last = prev;}}size--;return node.element;}
<br />**16.约瑟夫问题:**<br /><br />如何发挥出循环链表的最大威力?<br />可以考虑增设一个成员变量、三个方法<br />current:用于指向某个节点<br />void reset():让current指向头节点first<br />E next():让current往后走一步,也就是current=current.next<br />E remove():删除current指向的节点,删除成功后让current指向下一个节点
17.静态链表
前面所学的链表,是依赖于指针(引用)实现的
有些编程语言是没有指针的,比如早期的BASIC、FORTRAN语言
在没有指针的情况下,如何实现链表?
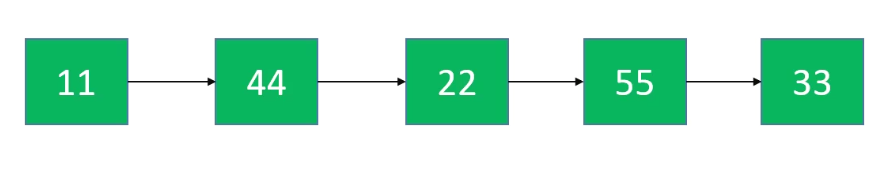
可以通过数组来模拟链表,称为静态链表
数组的每个元素存放2个数据:值、下个元素的索引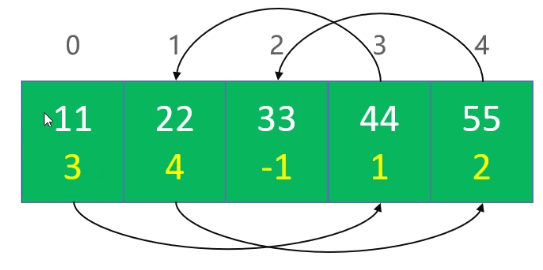
18.ArrayList优化
4.栈
1.设计和实现
栈是一种特殊的线性表,只能在一端进行操作
往栈中添加元素的操作,一般叫做push,入栈
从栈中移除元素的操作,一般叫做pop,出栈(只能移除栈顶元素,也叫做:弹出栈顶元素)
后进先出的原则,Last In First Out ,LIFO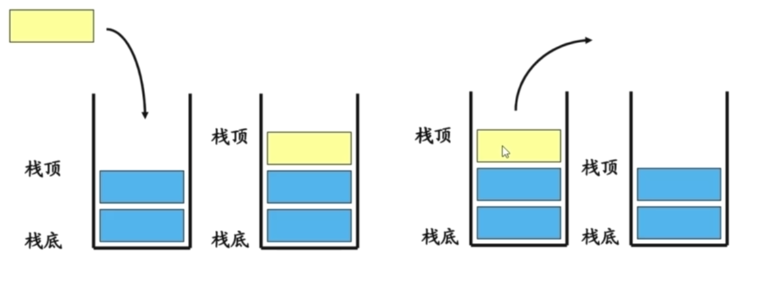
注意:这里说的”栈”与内存中的”栈空间”是两个不同的概念
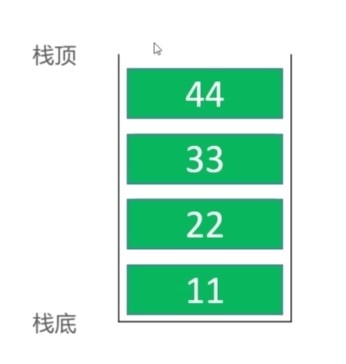

栈的内部实现是否可以直接利用以前学过的数据结构?
动态数组、链表
栈的实现
package com.ruoyi.Algorithms.f4栈;import java.util.ArrayList;import java.util.List;public class Stack1<E> {private List<E> list=new ArrayList<E>();/*** 入栈操作* @param element*/public void push(E element){list.add(element);}/*** 出栈操作* @return*/public E pop(){return list.remove(list.size()-1);}/*** 获取栈顶的元素* @return*/public E top(){return list.get(list.size() - 1);}/*** 判断是否为空* @return*/public boolean isEmpty(){return list.isEmpty();}}
2.栈的应用
浏览器的前进和后退
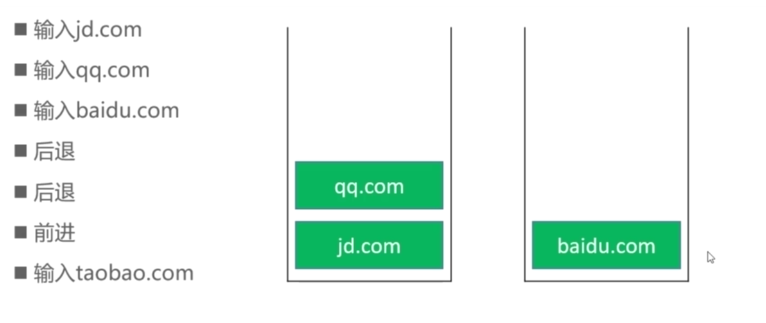
前进:左边栈顶元素弹出右边
后退:右边栈元素弹出左边
输入网址跳转,往左边栈顶加元素,清空右边栈
类似的应用场景:
软件的撤销、恢复功能
3.有效的括号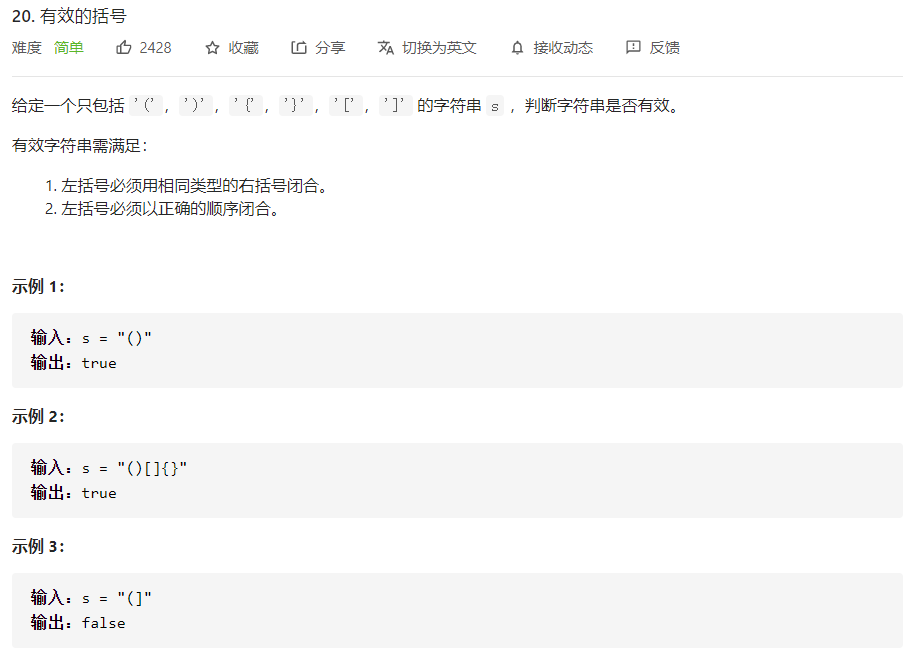
方法一:直接使用字符串操作替换,容易想到,但是效率非常低,因为String还是不可变的字符串,适合新手
class Solution {public boolean isValid(String s) {while(s.contains("()")||s.contains("{}")||s.contains("[]")){s.replace("{}","");s.replace("[]","");s.replace("()","");}return s.isEmpty();}}
方法二:直接使用栈
public boolean isValid(String s){java.util.Stack<Character> stack=new java.util.Stack<Character>();int len=s.length();for (int i = 0; i < len; i++) {char c=s.charAt(i);//如果是左边括号的话,就进行入栈操作if(c=='('||c=='{'||c=='['){stack.push(c);}else {if(stack.isEmpty()){return false;}char left = stack.pop();if(left=='('&& c!=')') return false;if(left=='['&& c!=']') return false;if(left=='{'&& c!='}') return false;}}return stack.isEmpty();}
clear方法: list.clear()即可
6.二叉树
1.树的基本概念
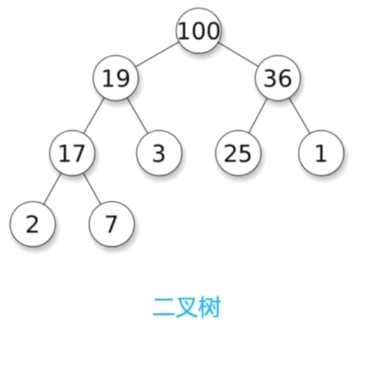
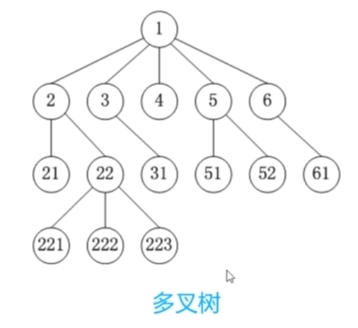
节点、根节点、父节点、子节点、兄弟节点
一棵树没有任何节点,成为空树
一颗树可以只有一个节点,也就是只有根节点
子树、左子树、右子树
节点的度:子树的个数
树的度:所有节点度中的最大值
叶子节点:度为0的节点
非叶子节点:度不为0的节点
层数:根节点在第1层,根节点的子节点在第2层,以此类推(有些教程也从第0层开始计算)
节点的深度:从根节点到当前节点的唯一路径
节点的高度:从当前节点到最远叶子节点的路径上的节点总数
树的深度:所有节点深度中的最大值
树的高度:所有节点高度中的最大值
树的深度等于树的高度
有序树:树中任意节点的子节点之间有顺序关系
无序树:树中任意节点的子节点之间没有顺序关系
森林:由m(m>=0)颗互不相交的树组成的集合
2.二叉树
每个节点的度最大为2(最多拥有2颗子树)
左子树和右子树是有顺序的
即使某节点只有一颗子树,也要区分左右子树
二叉树是有序树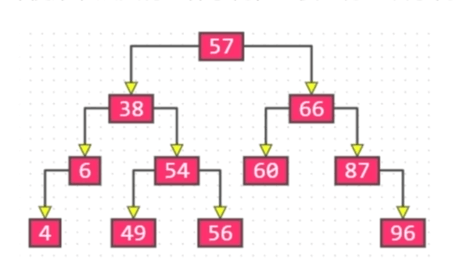
二叉树的性质:
非空二叉树的第i层,最多有2^(i-1) 个节点 (i>=1)
在高度为h的二叉树上最多有2^(h-1)个结点 (h>=1)
对于任何一颗非空二叉树,如果叶子节点个数为n0,度为2的节点个数为n2,则有:n0=n2+1
假设度为1的节点个数为n1,那么二叉树的节点总数n=n0+n1+n2
二叉树的边数T=n1+2*n2=n-1=n0+n1+n2-1
3.真二叉树、满二叉树
真二叉树:所有的节点的度都要么为0,要么为2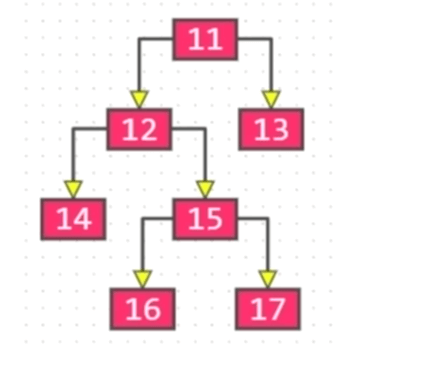
满二叉树:所有的节点的度要么为0,要么为2。且所有的叶子节点都在最后一层
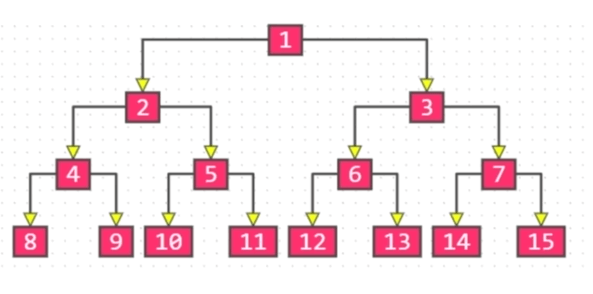
同样高度的二叉树中,满二叉树的叶子节点数量最多、总节点数量最多
满二叉树一定是真二叉树,真二叉树不一定是满二叉树
假设满二叉树的高度为h (h>=1),那么
第 i 层的节点数量:2^(i-1)
叶子节点数量2^(h-1)
总节点数量n
n=2^h-1=2^0+2^1+…+2^(h-1)
h=log2(n+1)
完全二叉树
叶子节点只会出现在最后两层,且最后一层的叶子节点都靠左对齐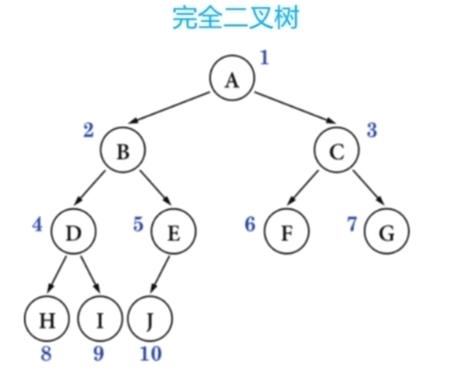
完全二叉树从根节点到倒数第二层是满二叉树
满二叉树一定是完全二叉树
性质:
度为1的节点只有左子树
度为1的节点要么是1个,要么是0个
同样节点数量的二叉树,完全二叉树的高度最小
假设完全二叉树的高度为h(h>=1),那么
1.至少有2^(h-1)个节点(2^0+2^1+2^2+…+2^(h-2) +1)
2.最多有(2^h)-1个节点(2^0+2^1+2^2+…+2^(h-1),满二叉树)0
假设总节点数量为n,求高度
2^(h-1)<=n<2^h
h-1<=log(2^n)<h
h=floor(log2n)+1
floor是向下取整,ceiling是向上取整
一颗有n个节点的完全二叉树(n>0),从上到下,从左到右对节点从1开始进行编号,对任意第i个节点
如果 i=1,它是根节点
如果 i>1,它的父节点编号为 floor(i/2)
如果 2i<=n,它的左子节点编号为 2i
如果 2i>n,它无左子节点
如果 2i+1<=n ,它的右子节点编号为2i+1
面试题:如果一颗完全二叉树有768个节点,求叶子节点的个数
假设叶子节点的个数为能n0,度为1的节点个数为n1,度为2的节点个数为n2
总结点个数n=n0+n1+n2 , 而且n0 = n2+1
n=2n0+n1-1
完全二叉树的n1要么为0,要么为1
n1为1时,n=2n0 ,n必然是偶数
叶子节点个数n0=n/2,非叶子节点个数n1+n2=n/2
n1=0时,n=2n0-1,n必然是奇数
叶子节点个数n0=(n+1)/2,非叶子节点个数n1+n2=(n-1)/2
通用公式:n0=floor((n+1)/2)
7.二叉搜索树
二叉搜索树是二叉树的一种,是应用非常广泛的一种二叉树,英文简称BST
又被成为:二叉查找树、二叉排序树
任意一个节点的值都大于其左子树所有节点的值
任意一个节点的值都小于其右子树所有节点的值
它的左右子树也是一颗二叉搜索树
二叉搜索树可以大大提高搜索数据的效率
二叉搜索树存储的元素必须具备可比较性
比如int、double等
如果是自定义类型,需要指定比较方式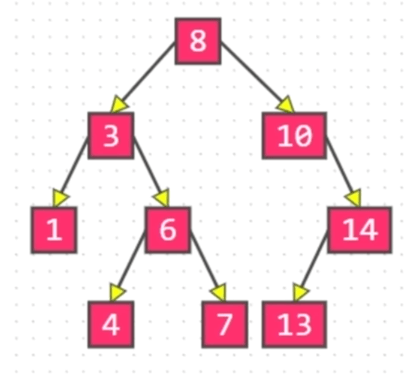
二叉搜索树的接口
int size() //元素的数量
boolean isEmpty() //是否为空
void clear() //请空所有元素
void add(E element) //添加元素
void remove(E element) //删除元素
boolean contains(E element) //是否包含某种元素
需要注意的是
对于我们现在使用的二叉树来说,它的元素没有索引的概念
为什么?
基本实现:
package com.ruoyi.Algorithms.f5二叉搜索树;public class BinarySearchTree<E> {private int size;//长度private Node<E> root;//根节点属性private static class Node<E> {E element;Node<E> left;Node<E> right;Node<E> parent;public Node(E element, Node<E> parent) {this.element = element;this.parent = parent;}}//判断节点是否为nullprivate void elementNotNullCheck(E element) {if (element == null) {throw new IllegalArgumentException("element must not be null");}}//元素的数量public int size() {return 0;}//是否为空public boolean isEmpty() {return false;}//请空所有元素public void clear() {}//添加元素public void add(E element) {}//移除元素public void remove(E element) {}//是否包含某种元素public boolean contains(E element) {return false;}}
add方法实现:
先找到父节点,然后再进行操作
//添加元素public void add(E element) {elementNotNullCheck(element);//添加第一个节点if (root == null) {root = new Node<>(element, null);size++;return;}//添加不是第一个节点//找到父节点Node<E> parent=null;Node<E> node = root;int cmp=0;while (node != null) {//跟节点比较cmp = compare(element, node.element);parent=node;if (cmp > 0) {node = node.right;} else if (cmp < 0) {node = node.left;} else {return;}}//看看插入到父节点的哪个位置Node<E> newNode=new Node<>(element,parent);if(cmp>0){parent.right=newNode;}else {parent.left=newNode;}size++;}
比较器方法:
在二叉搜索树中的元素必须是可比较的,所有必须要传入比较器或者实现比较器
public class BinarySearchTree<E> {private int size;//长度private Node<E> root;//根节点属性private Comparator<E> comparator;public BinarySearchTree() {this(null);}public BinarySearchTree(Comparator<E> comparator) {this.comparator = comparator;}public int compare(E element1, E element2) {if(comparator!=null){return comparator.compare(element1,element2);}return ((Comparable<E>)element1).compareTo(element2);}}public static void main(String[] args) {//像Integer这些都是默认有比较器的BinarySearchTree binarySearchTree=new BinarySearchTree<Person>(Comparator.comparingInt(Person::getAge));binarySearchTree.add(new Person("何华宇",15));}
未完待续…
8.B树
初识红黑树: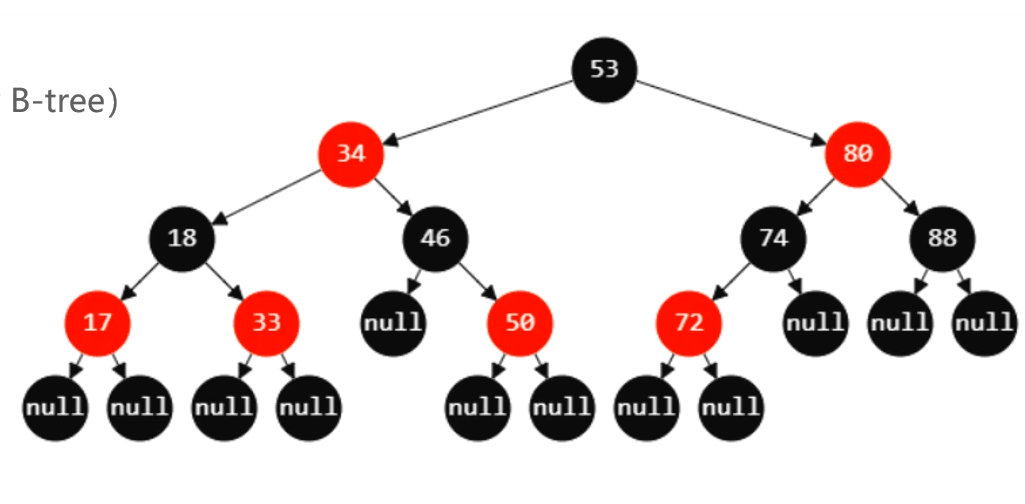
红黑树是一种自平衡二叉搜索树
以前也叫做平衡二叉B树
红黑树必须满足以下5个性质
1.节点是RED或者BLACK
2.根节点是BLACK
3.叶子节点(外部节点,空节点)都是BLACK
4.RED节点的子节点都是BLACK
RED节点的parent都是BLACK
从根节点到叶子节点的所有路径上不能有2个连续的RED节点
5.从任一节点到叶子节点的所有路径都包含相同数目的BLACK节点
B树(B-tree,b-树):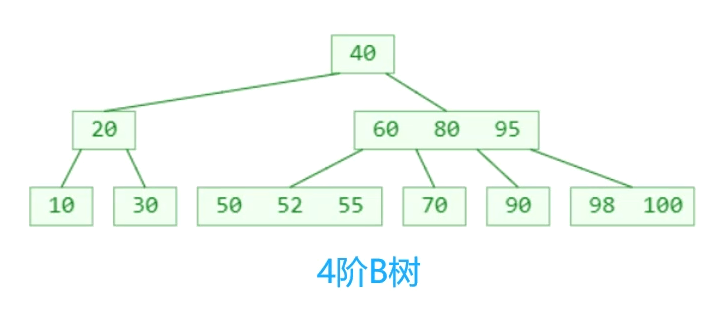
B树是一种平衡的多路搜索树,多用于文件系统,数据库的实现
仔细观察B树,有什么眼前一亮的特点?
1个节点可以存储超过2个元素,可以拥有超过2个子节点
拥有二叉搜索树的一些性质
平衡,每个节点的所有子树高度一致
比较矮
m阶B树的性质(m>=2)
阶数怎么区分:一个节点最多拥有的节点数称为阶数
假设一个节点存储的元素个数为X
根节点:1<=x<=m-1;
非根节点: ⌈m/2 ⌉ -1 <= x <= m-1;
如果有子节点,子节点个数y=x+1;
1)根节点:2<=y<=m
2)非根节点:⌈m/2 ⌉ -1<=y<=m,
比如m=3, 2<=y<=3, 因此可以称为(2,3)树,2-3树
比如m=4,2<=y<=4,因此可以称为(2,4)树,2-3-4树
以此类推
B树和二叉搜索树的区别: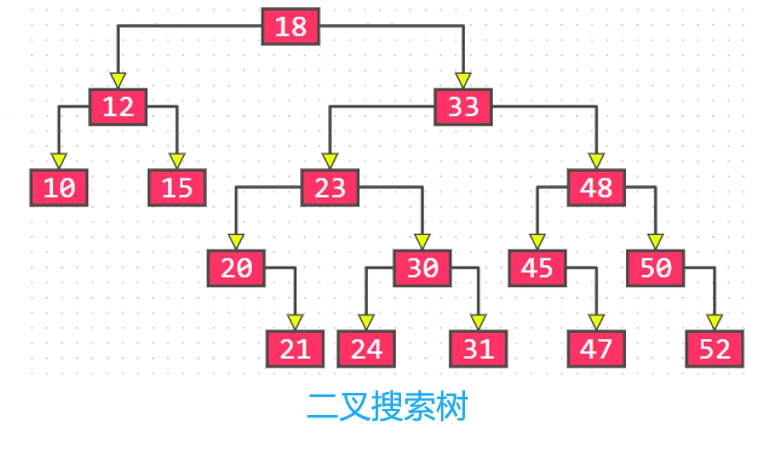
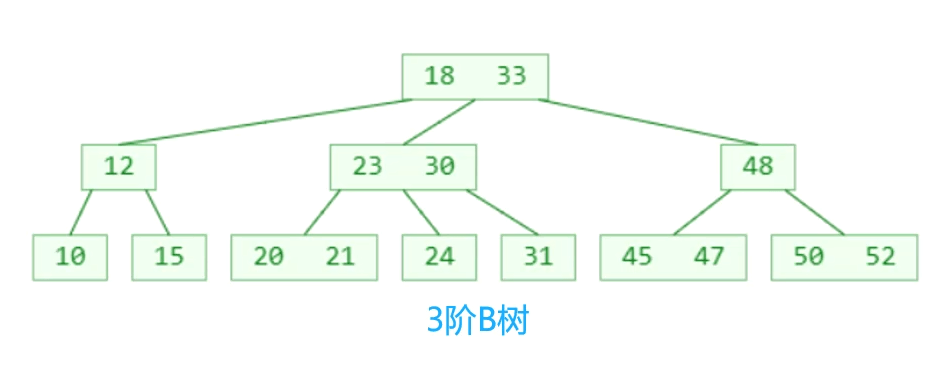
B树和二叉搜索树,在逻辑上是等价的
多代节点合并,可以获得一个超级节点
2代合并的超级节点,最多拥有4个子节点(至少是4阶B树)
3代合并的超级节点,最多拥有8个子节点(至少是8阶B树)
n代合并的超级节点,最多拥有2^n个子节点(至少是2^n阶B树)
m阶段B树,最多需要log2(m)代合并
搜索:
1.先在节点内部从小到大开始搜索元素
2.如果命中,搜索结束
3.如果未命中,再去对应的子节点中搜索元素,重复步骤1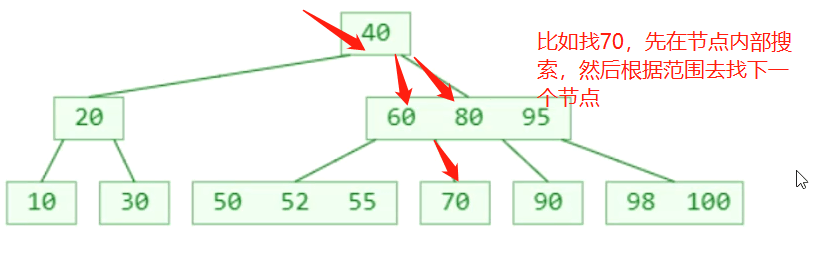
添加:
新添加的元素必定是添加到叶子节点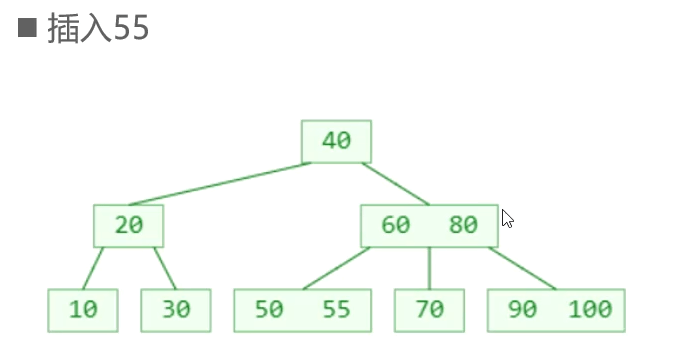

若有收获,就点个赞吧
0 人点赞
