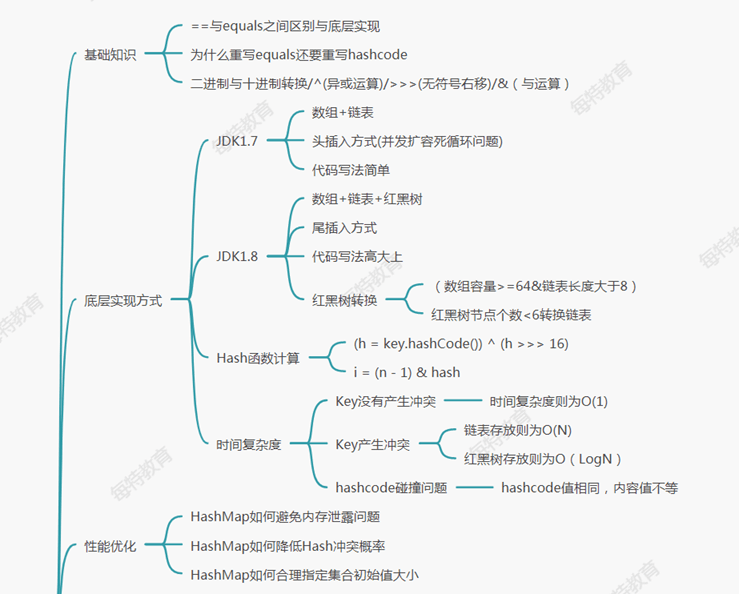
- HashMap相关问题
- 1.为什么重写Equals还要重写HashCode方法?
- 2.HashMap如何解决Hash冲突问题?
- 3.HashMap如何避免内存泄漏问题?
- 4.HashMapKey为null存放在什么位置?
- 5.HashMap1.7底层是如何实现的?
- 6.HashMap底层采用单链表还是双链表,单向链表?
- 7.为什么HashMap1.8需要引入红黑树?
- 8.HashMap如何扩容的?
- 9.HashMap死循环问题?
- 10.HashMap高低位与取模运算有那些好处?
- 11.HashMap根据key查询的时间复杂度?
- 12.HashMap如何存放1万条key效率最高?
- 13.为什么加载因子是0.75而不是1
- 14.hashmap1.8如何进行扩容?
- 15.HashMap1.8如何避免多线程扩容死循环问题
- 16.为什么不直接将key作为哈希值而是与高16位做异或运算?
- 17.HashMap高低位与取模运算有那些好处
- 18.HashMap底层是有序存放的吗?
- 19.LinkedHashMap和TreeMap底层如何实现有序的?
- 20.ConcurrentHashMap1.7底层实现原理?
- 21.ConcurrentHashMap1.8底层实现原理?
- 22.HashMap和HashTable区别?
- 23.为什么hashmap无序存放?
HashMap相关问题
1.为什么重写Equals还要重写HashCode方法?
因为重写了equals,如果不重写HashCode,当对象equals相等的时候,
HashCode不相等,存入HashMap不能去重,会重复存储,情况严重会造成内存泄露。
注意:equals方法默认的情况下Object类中采用==比较对象的内存地址是否相等。
2.HashMap如何解决Hash冲突问题?
jdk1.7:产生哈希冲突时,会在该索引位置挂链表。
jdk1.8:产生哈希冲突时,会在该索引位置挂链表或者
红黑树(当数组长度大于64并且链表长度大于等于8时转换成红黑树)
3.HashMap如何避免内存泄漏问题?
重写Euqals时会必须重写HashCode方法
4.HashMapKey为null存放在什么位置?
0索引的位置
5.HashMap1.7底层是如何实现的?
采用数组加链表,因为链表查找的复杂度O(n),所以链表较长的时候查找速度很慢,
因此在jdk1.8采用红黑数+链表
6.HashMap底层采用单链表还是双链表,单向链表?
单向链表,LinkedHashMap采用的才是双向链表
7.为什么HashMap1.8需要引入红黑树?
因为链表查找的复杂度O(n),所以链表较长的时候查找速度很慢,
而红黑树的时间复杂度为O(logn),查找速度快很多
8.HashMap如何扩容的?
当hashmap的值大于等于数组的容量0.75时,会扩容,使用位运算,
为原来的两倍。
要将所有元素遍历出来,并且n(数组容量)^hash重新计算数组下标(注意:哈希值不需要重新计算)
注意:添加元素是尾插法,扩容在1.7以前是头插法,1.8以后是尾插法
9.HashMap死循环问题?
因为多线程情况下,HashMap是线程不安全的,会导致指针错乱,
会出现环形链表,导致死循环,例如:a—->c c—->a
10.HashMap高低位与取模运算有那些好处?
高低位的方式分布的非常均匀
11.HashMap根据key查询的时间复杂度?
1).产生哈希冲突时
情况一:存储为链表时,为O(n),红黑树时为O(logn)
2).没有产生哈希冲突时O(1)
12.HashMap如何存放1万条key效率最高?
手动指定集合大小:(需要存储的元素/加载因子)+1
10000/0.75+1=-13334
正常如果存放1万个key的情况下,大概扩容10次=16384
—-来自阿里巴巴官方手册
13.为什么加载因子是0.75而不是1
产生背景:减少Hash冲突index的概率
加载加载因子越大,空间利用率比较高,有可能冲突概率越大
如果加载因子越小,有可能冲突概率比较小,空间利用率不高
空间和时间上的平衡点:0.75
统计学概率:泊松分布是统计学和概率学常见的离散概率分布
14.hashmap1.8如何进行扩容?
hashmap1.8扩容:
将原来的链表拆分两个链表存放,低位还是存放原来index位置 高位存放index=j+原来长度
if ((e.hash & oldCap) == 0) { 由于oldCap原来的容量没有减去1 所以所有的hash&oldCap
为0或者1;
优点:不需要每个值都去重新计算索引,只需要将拆分的链表存到原来索引和j+原来长度的索引位置,可以很好的提高效率
15.HashMap1.8如何避免多线程扩容死循环问题
扩容的时候采用尾插法
扩展:jdk1.8也会出现死循环,只是出现的问题不是环形链表,而是在链表转换为树的时候for循环一直无法跳出,导致死循环
16.为什么不直接将key作为哈希值而是与高16位做异或运算?
异或运算在数组散列分布更均匀
17.HashMap高低位与取模运算有那些好处
运算效率高,可以更好的减少哈希冲突.
18.HashMap底层是有序存放的吗?
无序,linked才是有序,因为遍历的时候是根据0索引开始遍历链表
19.LinkedHashMap和TreeMap底层如何实现有序的?
LinkedHashMap底层是把HashMap单向链表全部连接变成双向链表
TreeMap是通过红黑树算法实现的
20.ConcurrentHashMap1.7底层实现原理?
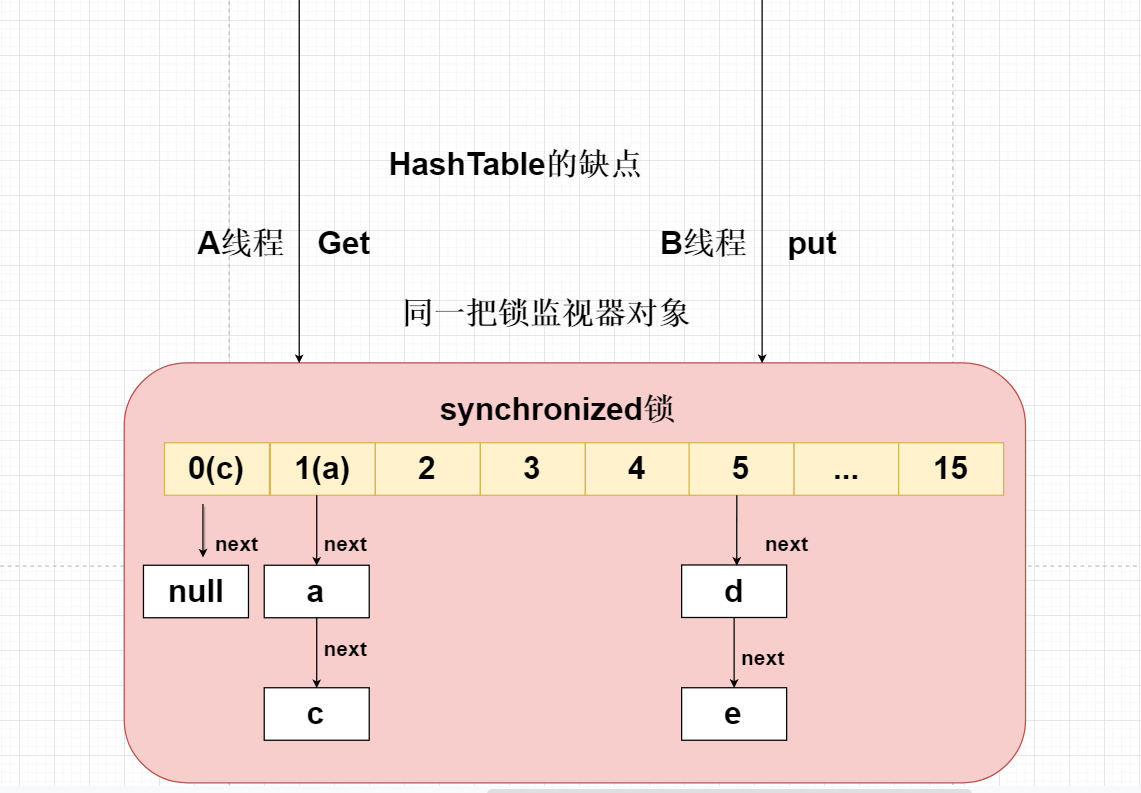
使用传统HashTable保证线程问题,是采用synchronized锁将整个HashTable中的数组锁住,
在多个线程中只允许一个线程访问Put或者Get,效率非常低,但是能够保证线程安全问题。
Jdk官方不推荐在多线程的情况下使用HashTable或者HashMap,建议使用ConcurrentHashMap分段HashMap。
效率非常高。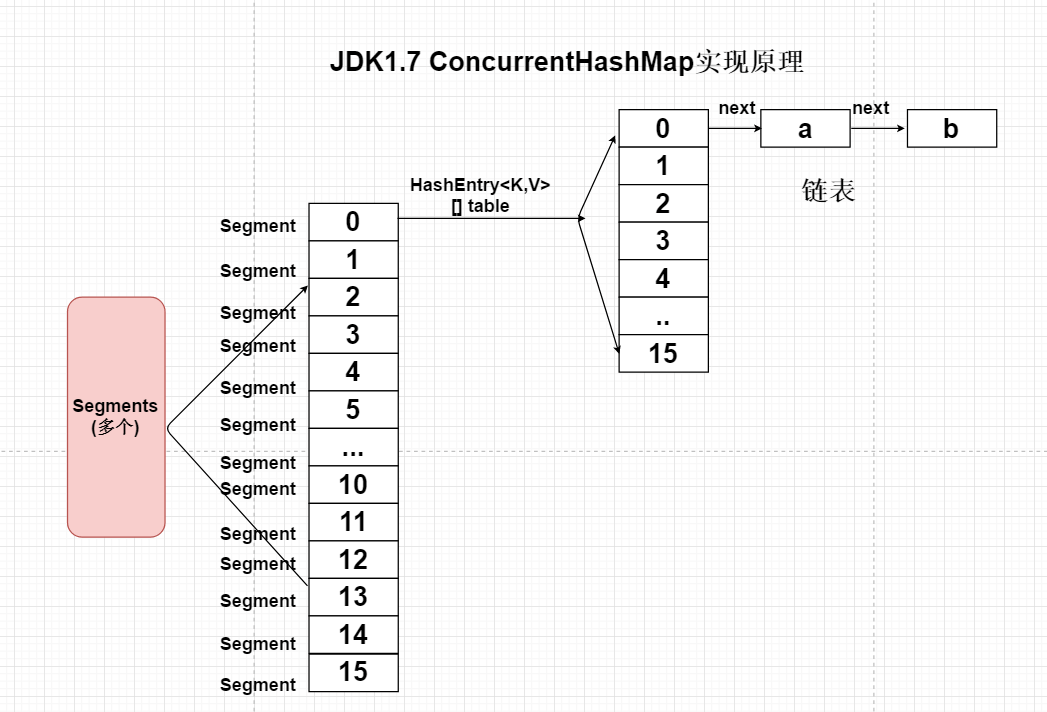
ConcurrentHashMap将一个大的HashMap集合拆分成n多个不同的小的HashTable(Segment),默认的情况下是分成16个不同的Segment。每个Segment中都有自己独立的HashEntry
当两个线程访问不同的hashmap时,则不会产生并发,很好的解决的并发效率
21.ConcurrentHashMap1.8底层实现原理?
ConcurrentHashMap1.8的取出取消segment分段设计,采用对CAS + synchronized保证并发线程安全问题,将锁的粒度拆分到每个index
下标位置,实现的效率与ConcurrentHashMap1.7相同。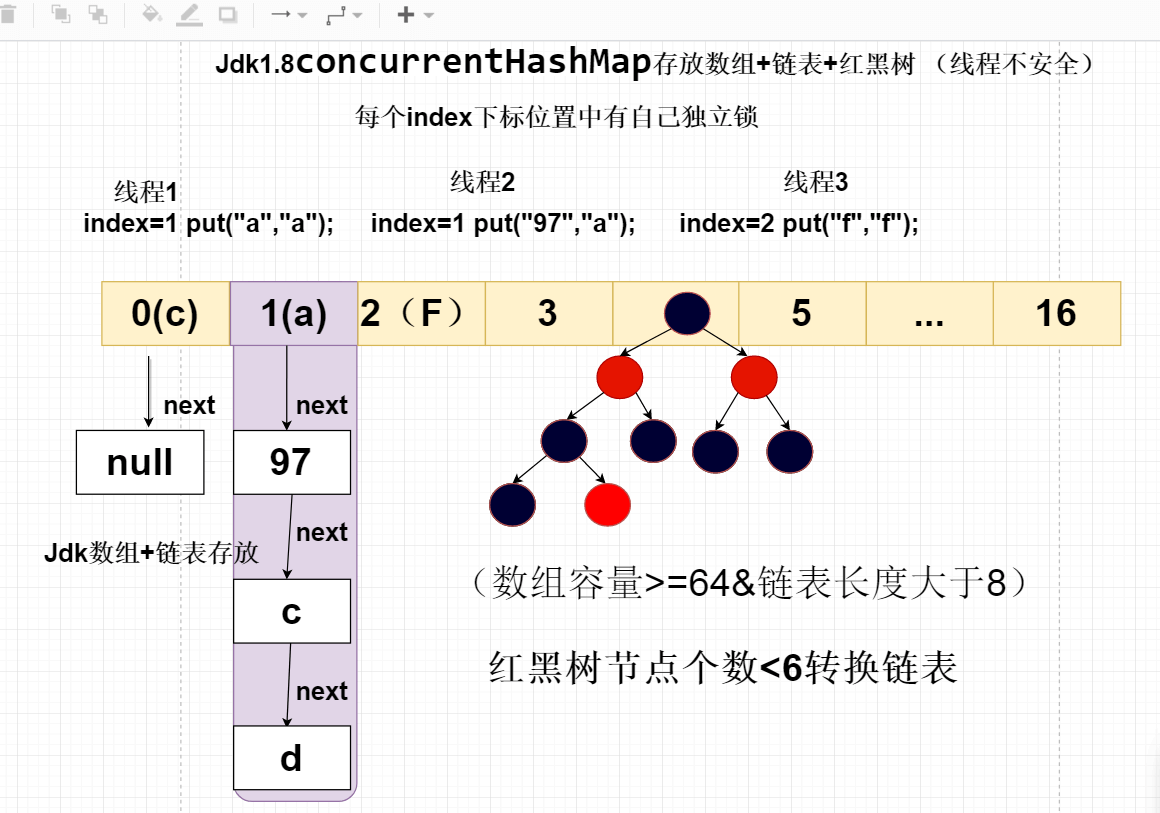
22.HashMap和HashTable区别?
1).hashmap线程不安全,hashtable线程安全
2).hashmap的key和value都可以存空值,hashtable的key和value都不能存空值
23.为什么hashmap无序存放?
因为你存的时候是根据hash值存,如果遍历是根据数据下标一个个来遍历数组下标的链表。
hashmap遍历效率非常低,因为要遍历链表和红黑树。时间复杂度比较高
24.LinkedHashMap集合的原理?
将每个index中的链表实现关联。
效率要比HashMap要低。
LinkedHashMap 的存取过程基本与HashMap基本类似,只是在细节实现上稍有不同,
这是由LinkedHashMap本身的特性所决定的,因为它要额外维护一个双向链表用于保持迭代顺序。
25.缓存淘汰算法底层实现的原理
分布式缓存淘汰算法:
LRU算法—->
最近少使用的key
方案1:访问key的时候对count值+1,效率是非常的低
方案2:基于LinkedHashMap有序集合实现
原理:访问该key的时候就会将key存放到链表最好的位置。
链表最开头的位置说明最近有可能少使用。
插入顺序:新添加的在前面,后添加的在后面。修改操作不影响顺序
执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始
的是最久没有被访问的,这就是访问顺序。其中参数accessOrder就是用来指定是否按照访问顺序,
如果为true,就是访问顺序false根据新增顺序
提示:如果需要对集合进行淘汰处理,最好使用LinkedHashMap.
扩展: 源码里面的modcount 作用
记录当前集合被修改的次数
- (1)添加
- (2)删除
这两个操作都会影响元素的个数。
当我们使用迭代器或foreach遍历时,如果你在foreach遍历时,自动调用迭代器的迭代方法,
此时在遍历过程中调用了集合的add,remove方法时,modCount就会改变,
而迭代器记录的modCount是开始迭代之前的,如果两个不一致,就会报异常,
说明有两个线路(线程)同时操作集合。这种操作有风险,为了保证结果的正确性,
避免这样的情况发生,一旦发现modCount与expectedModCount不一致,立即保错。

若有收获,就点个赞吧
0 人点赞
