- Weekly Summary
- Test Report
Weekly Summary
- 修复重大问题(pairwise patch matching算法写错了)相关实验重做。
- Encoder-Decoder一起pre-training,lr分开并没有像预计的那样比统一lr要带来更好的效果。原假设,By freezing the R50 backbone (MoCov1 loaded) 或减小其lr during pre-training, the decoder head is forced to form a good decoding strategy for the well-trained representation,进而提升分割性能。但实验结果没有印证该假设。
- Negative sample可以帮助学习context information: negative sample中的patch来自不同图片,整体不同但局部相似,使patch内容相似。尤其是高分辨率VOCaug预训练时,CNN感受野相对减小,context information减小,使得pixel相似的patch representation更加相似,却被视为negative sample,需要push away。通过decoder显式encode context infomation,让contrastive learning能够依赖context info来判断negative pair。但是仅仅判断不同,所需要的context info并不多,所以效果其实有限。
Test Report
Pairwise Patch Matching Alg Demo
Left to right, top to bottom, image q, image k, matching result, gt_illustration.



In practice, with threshold



MoCov1 v.s. MoCov1 + PLMoCo(VOCaug)
修复版PLMoCo算法测试
- Performance comparison
- MoCov1: 72.65%
- MoCov1&PLMoCo(VOCaug-20ep): 72.33%
- MoCov1&PLMoCo(VOCaug-50ep): 72.63%
-



MoCov2 v.s. MoCov2 + PLMoCo(VOCaug)
拓展版PLMoCo测试
Performance comparison
- MoCov1: 74.04%
- MoCov1&PLMoCo(VOCaug-20ep): 74.21%
- MoCov1&PLMoCo(VOCaug-50ep): 73.76%
- Learning rate schedule:





MoCov1 v.s. MoCov1 + PLEDMoCo(VOCaug, lr-1/10:1)
- Performance comparison
- MoCov1: 72.65%
- MoCv1&PLEDMoCo(VOCaug-20ep, lr_enc:dec=1:10): 72.88%
- MoCv1&PLEDMoCo(VOCaug-50ep, lr_enc:dec=1:10): 73.24%
- Learning rate schedule:



Ablation: Pre-training w/ and w/o Decoder
-
Ablation: PLEDMoCo(VOCaug) Epoch & LR
Performance comparison
- MoCv1&PLEDMoCo(VOCaug-20ep, lr-1:1): 72.98%
- MoCv1&PLEDMoCo(VOCaug-50ep, lr-1:1): 73.24%
- MoCv1&PLEDMoCo(VOCaug-20ep, lr-1/10:1): 72.88%
- MoCv1&PLEDMoCo(VOCaug-50ep, lr-1/10:1): 73.24%
- MoCv1&PLEDMoCo(VOCaug-20ep, lr-0:1): 73.43%
- MoCv1&PLEDMoCo(VOCaug-50ep, lr-0:1): 72.86%
通过对比原版MoCo和PLEDMoCo的encoder freeze版本,可以说patch level的pretext task对decoder的初始化是有帮助的。还不太清楚为什么encoder freeze的版本以最少的ep取得最好的mIoU。也不太清楚为什么先前的假设在lr-1:1和lr-1:10上没有实现。
尝试:PatchLevelContrastiveLearning与SimSiam的结合(基于原版MoCo,对比原版MoCo)
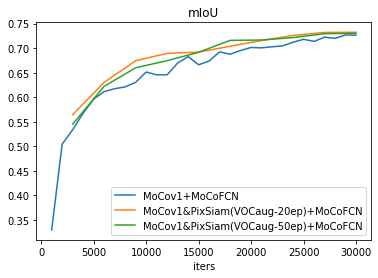
第一组PixSiam在VOCaug上的实验
- Performance comparison
- MoCov1: 72.65%
- MoCov1&PixSiam(VOCaug-20ep): 73.24%
- MoCov1&PixSiam(VOCaug-50ep): 73.04%
- Learning rate schedule:



另一组PixSiam在ImageNet上的实验(224x224分辨率,小于VOCaug上使用的512x512,可以达到更大的batch-size,最后效果也还好)
- Performance comparison
- MoCov1: 72.65%
- MoCov1&PixSiam(IN-2ep): 73.40%
- MoCov1&PixSiam(IN-5ep): 72.87%
- Learning rate schedule:




对比实验,PLEDMoCo与PLMoCo与PixSiam
- 带不带negative sample
- PLEDMoCo与PixSiam的对比
- PLMoCo与PixSiam non decoder的对比
- pre-train decoder有没有用

若有收获,就点个赞吧
0 人点赞
