 ">
">
 ">
">
Weekly Summary
- Updated code base. Started github: SSL4DP.
- Tested on Encoder-Decoder (Vanilla MoCo ResNet + UNetHead) momentum contrastive learning on VOCaug dataset. Experiments mainly focus on testing how whether freezing the R50 backbone or not would influence the transfer learning performance.
- Worked and tested on Patch Level momentum contrastive learning on VOCaug dataset. The naive version of this method does not seem to be very effective. This method is very similar to newly published works like PixContrast, DenseCL, etc.
Test Report
Encoder-Decoder MoCo
MoCo(v1) & EDMoCo(R50Frozen or not) + UNetHead


Original Hypothesis: By freezing the R50 backbone (MoCov1 loaded) during pre-training, the decoder head probably is forced to form a good decoding strategy for the frozen representation. Since MoCo pretrained R50 can form decent representations, the decoder head can learn from it and perform well.
Loss seems to be the same but evaluation mIoU is higher for EDMoCo with R50 not frozen.MoCo(v1) & EDMoCo(R50Frozen or not) + UNetHead (R50Frozen)
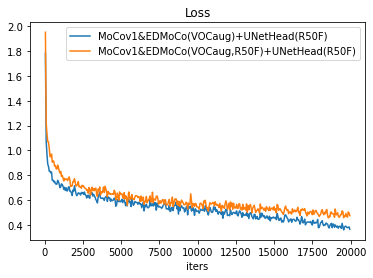

Seems that by freezing R50 during pre-training, the model have slightly better evaluation mIoU.
MoCo(v1) & EDMoCo(R50Frozen) + UNetHead (R50Frozen or not)


A group to demonstrate how UNetHead with R50Frozen or not affect segmentation performance.
Patch-Level MoCo
Vanilla MoCo(v1) v.s. MoCo(v1) & PLMoCo
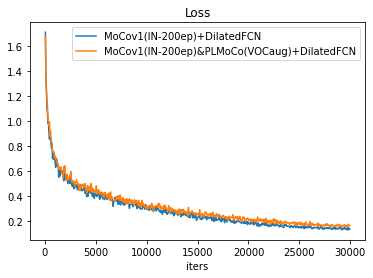

MoCo(v1) & PLMoCo + UNetHead
UNetHead performs worse than simple 2-layer dilated convolution, mainly because UNetHead demands longer training and it learns well under small learning rate. 20k training schedule uses lr=0.01, poly decay, whereas 30k training schedule uses lr=0.003, linear decay.
RandomInit. & PLMoCo
RandomInit. & PLMoCo + DilatedFCN is tested. The result is similar compared to encoder-decoder moco method with random init. resnet backbone (not included in the report due to similar performance and lack of reference value).
RandomInit. & PLMoCo + UNetHead performs very poorly because of undertrained UNetHead and backbone representation.

若有收获,就点个赞吧
0 人点赞
