Weekly Summary
- Reproduced reported performance-wise result in MoCo paper with linear lr update schedule.
- Carried out testing on supervised ImageNet pretraining. Results indicate better performance (initialization) but the reported mIoU has not yet been reached.
- Conducted experiments with several different lr update strategies including step, linear, polynomial and exponential, on MoCo pretraining as well as supervised ImageNet pretraining.
- Discovered that the linear learning rate decay yields better mIoU and has smoother loss reduction than the default lr schedule (step decay).
- Converted SimCLR tf model to mmseg-style and done some testing in MoCo setup. Results shows that SimCLR performs better than MoCo in the same setting.
Test Report
Downstream Task Finetuning Setting
As describe in MoCo paper, in the appendix section, their backbone consists of the convolutional layers in R50, and the 3 by 3 convolutions in conv5 blocks have diilation 2 and stride 1. FCN head consists of two 3 by 3 convolutions of 256 channels, with BN and dilations set to 6, and finally a 1 by 1 convolution for per-pixel classification. Training is with random scaling by a ration in 0.5 and 2.0 inclusive, cropping, and horizontal flipping. Crop size is set to 513. Inference is performed on original image size. Mini-batch size is 16 and weight decay 0.0001. Learning rate starts at 0.003, multiplied by 0.1 at 70th (21000 iters) and 90th percentile (27000 iters) of training in a total of 30k iterations setting. Training and evaluation is performed on PASCAL VOC segmentation dataset.Experimented Lr Schedules
All different investigated learning rate schedules, as shown in the figure below, start with the base learning rate as 0.003, same as the settings introduced in MoCo funetuning on VOC segmentation task. Step lr decay strategy is what was originally proposed in the paper, but yet later in our testing, chances are that such strategy could yield undertrained model, and the model may suffers from increasingly lack of small steps towards convergence. Besides, all later developed learning rate schedules are designed to have similar footprint to the step lr schedule.
In the second figure, the blue line stands for training loss in step lr schedule and the orange line stands for training loss in linear lr schedule. The second figure indicates that perhaps a smoother learning rate decay could help the model find a better convergence point if it had previously.

Performance Report (mIoU)
Reference to the reported performance in MoCo.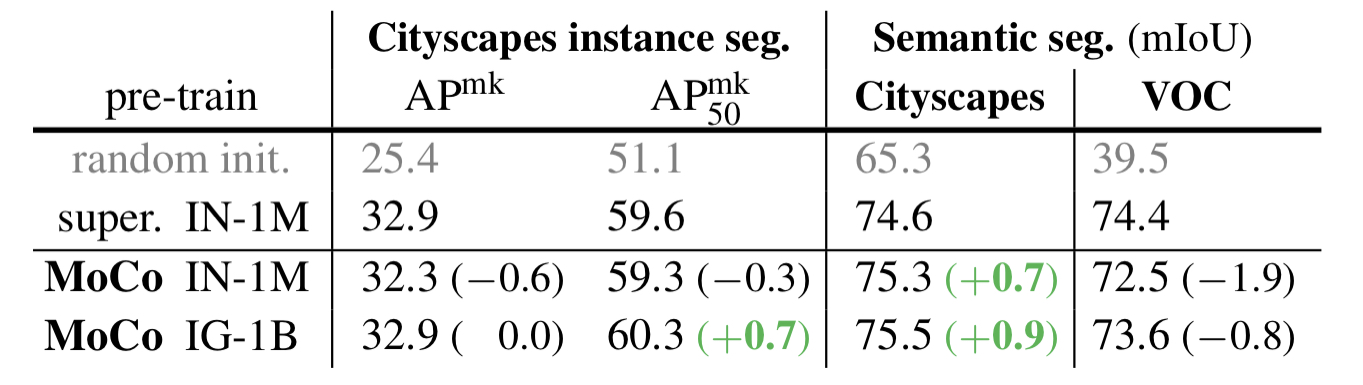
| Our results | Reference to paper | |||
|---|---|---|---|---|
| SuperIN-1M | MoCo | SuperIN-1M | MoCo | |
| Step | 73.226 | 71.437 | 74.4 | 72.5 |
| Linear | 72.873 | 72.646 | - | - |
| Poly | 72.348 | 71 | - | - |
| Exp | 71.927 | - | - |

若有收获,就点个赞吧
0 人点赞
