Last Meeting
Key Points
- Supervision levels
- Level 1: pixel (w.r.t. feature map) / patch (w.r.t original image) level
- Level 2: region level, using superpixel or other clustering algorithms
- Level 3: image level, like instance contrastive learning
- MoCo-v2 + MoCo (original) should be the baseline.
- Starts with 10% label tests, linear evaluation, then go for 100% label fine-tuning.
- Linear probe should be, freezing every parameter except the parameters of the 1x1 convolution for segmentation classification.
- Evaluation methods
- t-SNE visualization for qualitative analysis
- Examining different layers of encoder or decoder
- Linear probe, only tuning last linear classification layer
- SVM accuracy reveals linear separability
- Fine-tuning using less label
- Full fine-tuning
Monthly Summary
- Code revision
- Four new losses
- t-SNE visualization
- Reimplement linear probe
- Tests on more complex decoder heads
- Conclusions
- Pre-training with decoders, in most if not all cases, results in performance improvements. The performance gains are about 1~2% mIoU in fine-tuning with 100% labels test.
- Patch level (level 1) supervision is beneficial for dense predictions, but it brings not as a remarkable improvement as instance contrastive learning to image classification.
- Non-contrastive methods still cannot compete with contrastive approaches in terms of linear evaluation, but those two categories of methods are on par in fine-tuning tests. As shown in the tSNE visualization, features trained using contrastive methods are noticeably more separable than those using the non-contrastive method.
- Complex decoders gain less improvements compared to simple two layers of dilated convolutions in fine-tuning tests, but exceed in linear evaluation, achieving 57.54% mIoU, 5.17% mIoU higher than the best result of simple decoder.
- As for convergence rate, pre-trained decoders brought slight improvement.
- Same pattern continues on different dataset.
Design of Loss Functions
- Contrastive methods
- MoCo (original): ResNet-50 as encoder, MoCo pretraining (NCE loss) on VOC or Cityscapes dataset.
- MoCo (w/dec): Enc-Dec as encoder, MoCo pretraining (NCE loss) on VOC or Cityscapes dataset.
- RLMoCo (w/dec): Enc-Dec as encoder, MoCo pretraining (NCE loss) using feature map, matched regions, i.e. regions that have the same superpixel label, as positive pairs, on VOC or Cityscapes dataset.
- PLMoCo (w/dec): Enc-Dec as encoder, MoCo pretraining (NCE loss) using feature map, pairwise-distance-matched patches as positive pairs, on VOC or Cityscapes dataset.
- PLMoCo**+** (w/dec): Average of MoCo (w/dec) and PLMoCo (w/dec) loss.
- Non-contrastive methods
- PLSiam: Patch level contrastive version of the Simple Siamese network, contrastive learning without negative pairs, pretraining using feature map, pairwise matched patches as positive pairs, on VOC or Cityscapes dataset. (PLMoCo without negative pairs)
- P2Vec: Analogy of Word2Vec, treat each pixel on feature map as a word, maximize its conditional probability given the surrounding context, context is provided via decoder head.
- PRCL: Relational pre-training. Maximize the cosine similarity between the differences of matched patches of two augmented images.
(This method is similar to PLSiam, as one uses a projection head, that predict key patches through query patches, i.e.  , and the other confines the direction of the diff vector, i.e.
, and the other confines the direction of the diff vector, i.e.  , which only existed due to different augmentations and possibly global context. Naturally, it could be interpreted that projection head is modeling such difference)
, which only existed due to different augmentations and possibly global context. Naturally, it could be interpreted that projection head is modeling such difference)
Illustrations
PLMoCo -> PLSiam -> PRCL


t-SNE Visualization
- All decoder are MoCoFCN, 2 layers of dilated convolutions.
- The new linear evaluation protocol is in fact a quantitative analysis of linear separability.
As the complexity of the decoder increases, linear separability of the ResNet feature decreases.
MoCo-v2 + Supervised Learning




- MoCo-v2 + MoCo




- MoCo-v2 + PLMoCo




- MoCo-v2 + PLMoCo+




- MoCo-v2 + PLSiam


- MoCo-v2 + P2Vec


- MoCo-v2 + PRCL


mIoU Report
Pre-training Settings
- Batch size fixed at 16 for all pre-training.
- Base lr 0.02, cosine decay to 0.002, 10% base lr.
- Loaded pre-trained parameters have lr 0.002, 10% base lr, cosine increase to 0.02, base lr, but switch to the main lr when it’s about to be larger than the main lr.

Segmentation Settings
- Batch size fixed at 16 for all tests.
- FT-10%: Fine-tuning using 10% labeled data; compute gradients for every learnable parameter.
- VOC, 5k iterations, lr fixed at 0.001, momentum 0.9, weight decay 1e-4
- Cityscapes, 15k iterations, lr fixed at 0.005, momentum 0.9, weight decay 1e-4
- LP-100%: Linear probe using 100% labeled data; freeze everything except the last 1 by 1 convolutional layer used for classification. REQUIRES PRE-TRAINED DECODER
- VOC, 3k iterations, lr fixed at 0.03, momentum 0.9, weight decay 1e-4
- Cityscapes, 9k iterations, lr fixed at 0.1, momentum 0.9, weight decay 1e-4
- FT-100%: Fine-tuning using 100% labeled data; compute gradients for every learnable parameter.
- VOC, 30k iterations, lr 0.003, cosine decay to 3e-4, momentum 0.9, weight decay 1e-4
- Cityscapes, 90k iterations, lr 0.01, cosine decay to 1e-4, momentum 0.9, weight decay 1e-4
VOCaug
MoCoFCN (2 layers of dilated convolution)
| | FT-10% | LP-100% | FT-100% | | —- | —- | —- | —- | | Randinit (150k iterations) | - | - | < 70% | | ImageNet | 59.41% | - | 72.46% | | BYOL (bs256, ep300) | 60.98% | - | 72.31% | | MoCo-v2 (bs256, ep800) | 55.07% | - | 74.85% | | MoCo-v2 + naive MoCo | 56.74% | - | 74.91% | | MoCo-v2 + MoCo | 58.36% | - | 74.92% | | MoCo-v2 + MoCo (w/dec) | 61.50% | 47.03% | 75.47% | | MoCo-v2 + PLMoCo | 60.47% | - | 75.15% | | MoCo-v2 + PLMoCo (w/dec) | 62.56% | 51.40% | 75.72% | | MoCo-v2 + PLMoCo+ | 61.83% | - | 75.49% | | MoCo-v2 + PLMoCo+ (w/dec) | 63.85% | 52.37% | 76.03% | | MoCo-v2 + PLSiam (w/dec) | 63.13% | 18.37% | 75.55% | | MoCo-v2 + P2Vec (w/dec) | 62.96% | 14.04% | 75.81% | | MoCo-v2 + PRCL (w/dec) | 62.26% | 17.02% | 75.90% |
PSPNet - Pooling
| FT-10% | LP-100% | FT-100% | |
|---|---|---|---|
| ImageNet | 64.02% | - | 75.44% |
| BYOL (bs256, ep300) | 63.98% | - | 73.43% |
| MoCo-v2 (bs256, ep800) | 56.43% | - | 75.60% |
| MoCo-v2 + MoCo (original ep20) | 60.49% | - | 75.64% |
| MoCo-v2 + MoCo (w/dec ep20) | 63.13% | 48.29% | 75.70% |
| MoCo-v2 + PLMoCo (w/dec ep20) | 62.55% | 53.71% | 76.22% |
| MoCo-v2 + PLMoCo+ (w/dec ep20) | 63.73% | 52.06% | 76.02% |
| MoCo-v2 + PLSiam (w/dec) | 62.56% | 44.50% | 76.40% |
| MoCo-v2 + P2Vec (w/dec) | 63.31% | 25.66% | 75.39% |
| MoCo-v2 + PRCL (w/dec) | 62.86% | 44.15% | 75.14% |
DeepLabv3 - More Dilated Convs
| FT-10% | LP-100% | FT-100% | |
|---|---|---|---|
| ImageNet | 63.20% | - | 74.94% |
| BYOL (bs256, ep300) | 62.09% | - | 74.67% |
| MoCo-v2 (bs256, ep800) | 59.56% | - | 76.17% |
| MoCo-v2 + MoCo (original ep20) | 63.01% | - | 76.68% |
| MoCo-v2 + MoCo (w/dec ep20) | 63.31% | 50.93% | 77.41% |
| MoCo-v2 + PLMoCo (w/dec ep20) | 63.64% | 57.54% | 77.42% |
| MoCo-v2 + PLMoCo+ (w/dec ep20) | 64.13% | 55.09% | 77.42% |
| MoCo-v2 + PLSiam (w/dec) | 62.72% | 35.99% | 76.49% |
| MoCo-v2 + P2Vec (w/dec) | 61.88% | 22.99% | 77.35% |
| MoCo-v2 + PRCL (w/dec) | 64.40% | 50.30% | 77.38% |
Cityscapes
MoCoFCN (2 layers of dilated convolution)
| FT-10% | LP-100% | FT-100% | |
|---|---|---|---|
| RandInit | - | - | ~ 70% |
| ImageNet | 63.58% | - | 75.31% |
| MoCo-v2 (bs256, ep800) | 66.82% | - | 76.79% |
| MoCo-v2 + MoCo (original ep20) | 67.05% | - | 76.77% |
| MoCo-v2 + MoCo (w/dec ep20) | 67.42% | 30.77% | 77.06% |
| MoCo-v2 + PLMoCo (w/dec ep20) | 67.62% | 38.25% | 76.57% |
| MoCo-v2 + PLMoCo+ (w/dec ep50) | 67.34% | 32.33% | 77.14% |
| MoCo-v2 + PLSiam (w/dec) | 67.28% | 19.93% | 77.13% |
| MoCo-v2 + P2Vec (w/dec) | 68.27% | 7.56% | 77.37% |
| MoCo-v2 + PRCL (w/dec) | 67.44% | 23.39% | 77.63% |
Learning Curves
- MoCo, with and without decoder


- PLMoCo, with and without decoder

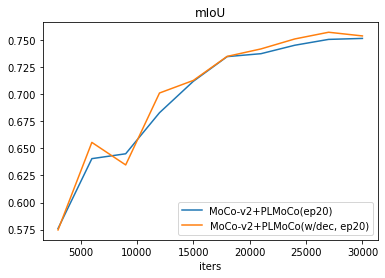
- PLMoCo+, with and without decoder


Conclusions
- Pre-training with decoders, in most if not all cases, results in performance improvements. The performance gains are about 1~2% mIoU in fine-tuning with 100% labels test.
- Patch level (level 1) supervision is beneficial for dense predictions, but it brings not as a remarkable improvement as instance contrastive learning to image classification.
- Non-contrastive methods still cannot compete with contrastive approaches in terms of linear evaluation, but those two categories of methods are on par in fine-tuning tests. As shown in the tSNE visualization, features trained using contrastive methods are noticeably more separable than those using the non-contrastive method.
- Complex decoders gain less improvements compared to simple two layers of dilated convolutions in fine-tuning tests, but exceed in linear evaluation, achieving 57.54% mIoU, 5.17% mIoU higher than the best result of simple decoder.
- As for convergence rate, pre-trained decoders brought slight improvement.
- Same pattern continues on different dataset.

若有收获,就点个赞吧
0 人点赞
