汇报论文汇总: http://paper.idea.edu.cn/cvpr2021
录播:
目标检测
Weakly-supervised Instance Segmentation via Class-agnostic Learning with Salient Images
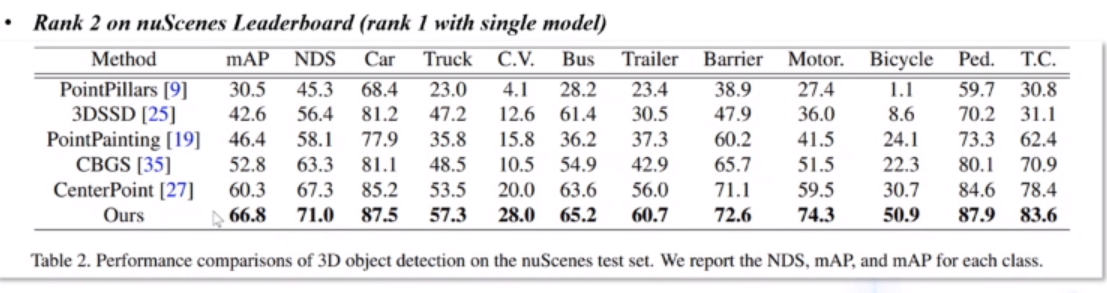
PointAugmenting: Cross-Modal Augmentation for 3D Object Detection
跨模态3D物体检测算法
- http://paper.idea.edu.cn/paper/544429653300703242
- https://vision.sjtu.edu.cn/files/cvpr21_pointaugmenting.pdf
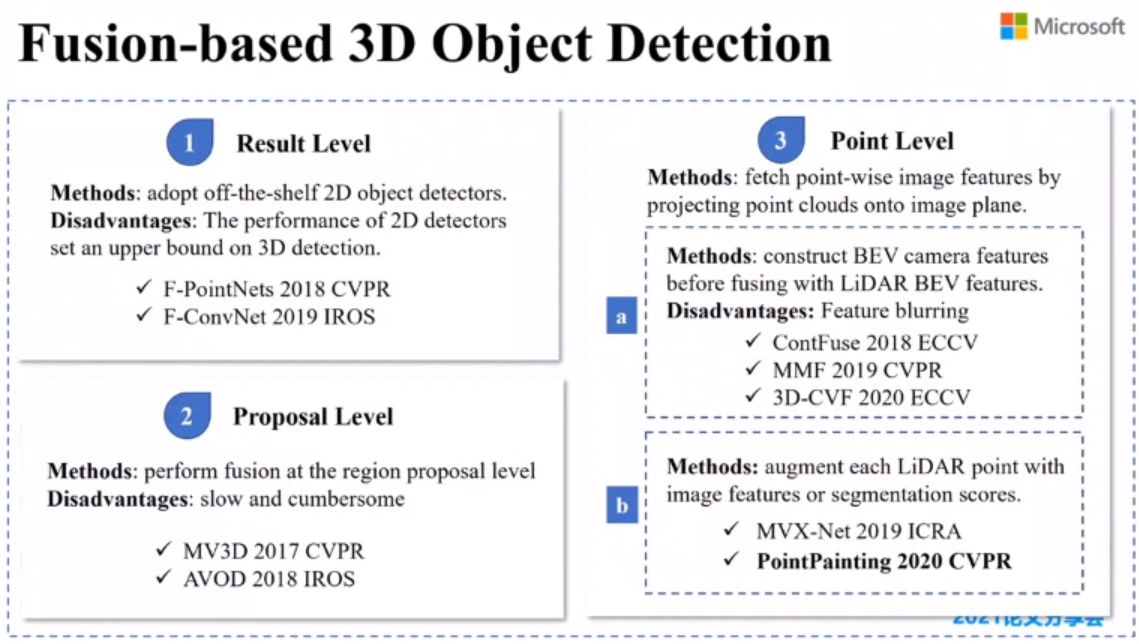
多模态3D目标检测 (融合多传感器)
2D图像检测结果扩展为3D框
点云雷达标定
- 点云特征压缩到鸟瞰图上
- 点云与图像特征拼接
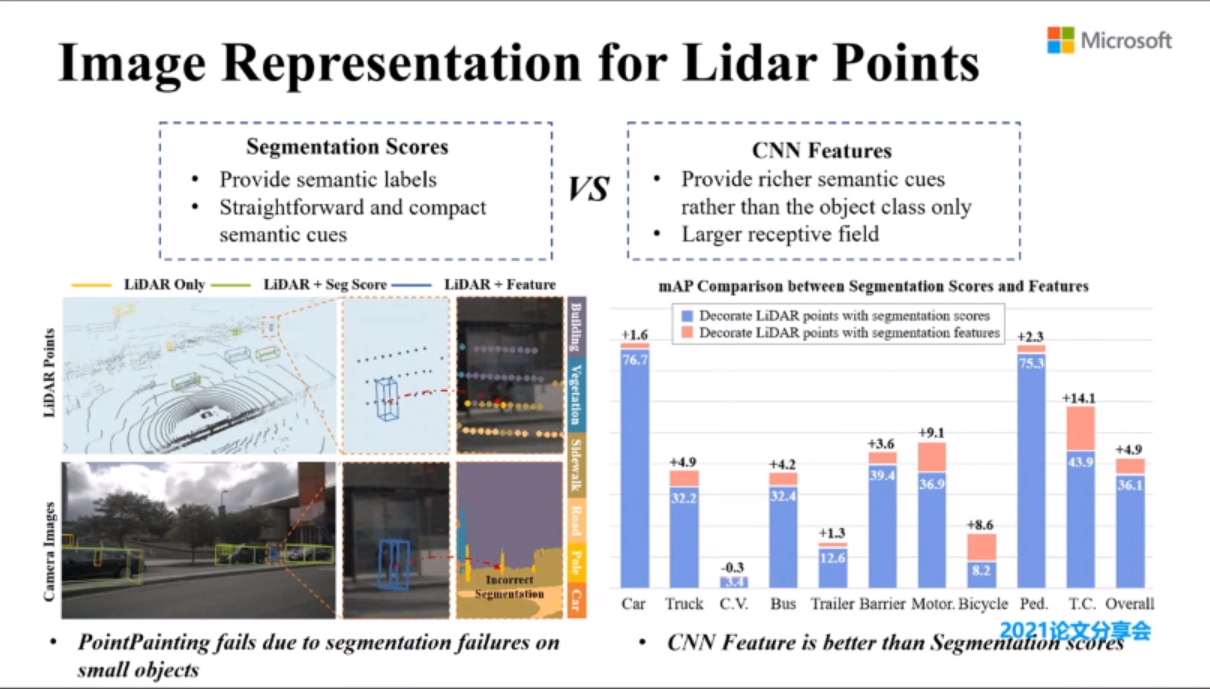
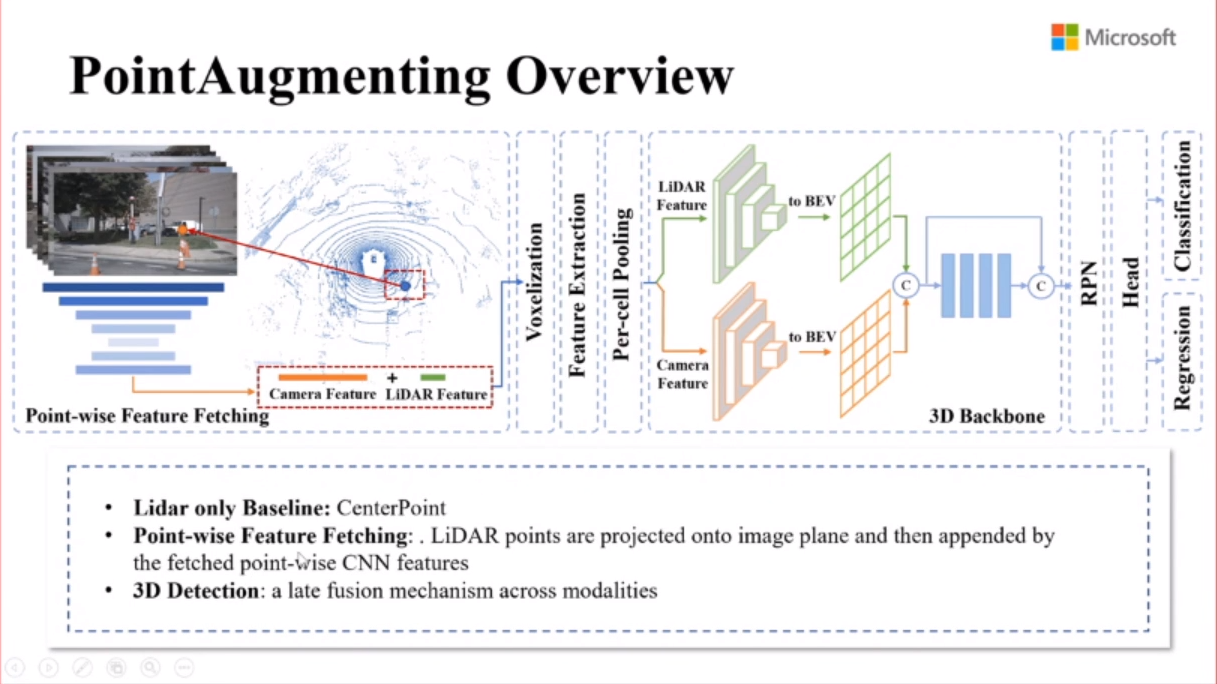
数据模态的一致性,在点云上删除图像的遮挡部分
Towards More Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark
基于自然语言的目标跟踪
三维视觉
Deep Implicit Moving Least-Squares Functions for 3D Reconstruction
IMLSNet预测了一个八叉树结构,作为在需要时生成MLS点的支架,并通过学习的局部先验来描述形状几何,在重建质量和计算效率方面超过了最先进的基于学习的方法
https://arxiv.org/pdf/2103.12266.pdf
Variational Relational Point Completion Network
一个多视图部分点云数据集(MVP数据集),其中包含超过10万个高质量的扫描,从26个均匀分布的相机姿态为每个三维CAD模型渲染了部分三维形状。广泛的实验表明,VRCNet在所有标准的点云补全基准上都优于最先进的方法,也在现实世界的点云扫描中显示出了极大的通用性和稳健性。
We are More than Our Joints: Predicting how 3D Bodies Move

若有收获,就点个赞吧
0 人点赞
