什么是Raft?
Raft 是一种共识算法,旨在易于理解(Paxos比较难理解)。它在容错性和性能上与 Paxos 相当。不同之处在于它被分解为相对独立的子问题,并且它干净地解决了实际系统所需的所有主要部分。我们希望 Raft 能够为更广泛的受众提供共识,并且这些更广泛的受众将能够开发出比目前可用的各种更高质量的基于共识的系统。
什么是共识?
共识是容错分布式系统中的一个基本问题。共识涉及多个服务器的值达成一致。一旦他们就某个值做出决定,该决定就是最终决定。当大多数服务器可用时,典型的共识算法就能继续运行;例如,即使 2 台服务器出现故障,由 5 台服务器组成的集群也可以继续运行。如果更多服务器出现故障,它们将停止运行(但永远不会返回错误结果)。
共识通常出现在复制状态机的上下文中,这是一种构建容错系统的通用方法。每个服务器都有一个状态机和一个日志。状态机是我们要使其容错的组件,例如哈希表。即使集群中的少数服务器出现故障,客户端也会认为它们正在与单个可靠的状态机交互。每个状态机都将其日志中的命令作为输入命令。在我们的哈希表示例中,日志将包含诸如_set x to 3_之类的命令。共识算法使得服务器日志中的命令达成一致。共识算法必须确保如果任何状态机将 set x to 3作为第n个命令,没有其他状态机应用不同的第n个命令。也就是说,每个状态机处理相同顺序的命令,从而产生相同顺序的结果并达到相同顺序的状态。
Raft可视化
这是在浏览器中运行的 Raft 集群。您可以与它进行交互以查看 Raft 的运行情况。左边显示了五台服务器,右边显示了它们的日志。我们希望尽快创建一个截屏视频来解释发生了什么。这个可视化(RaftScope)仍然很粗糙,欢迎大家的PR。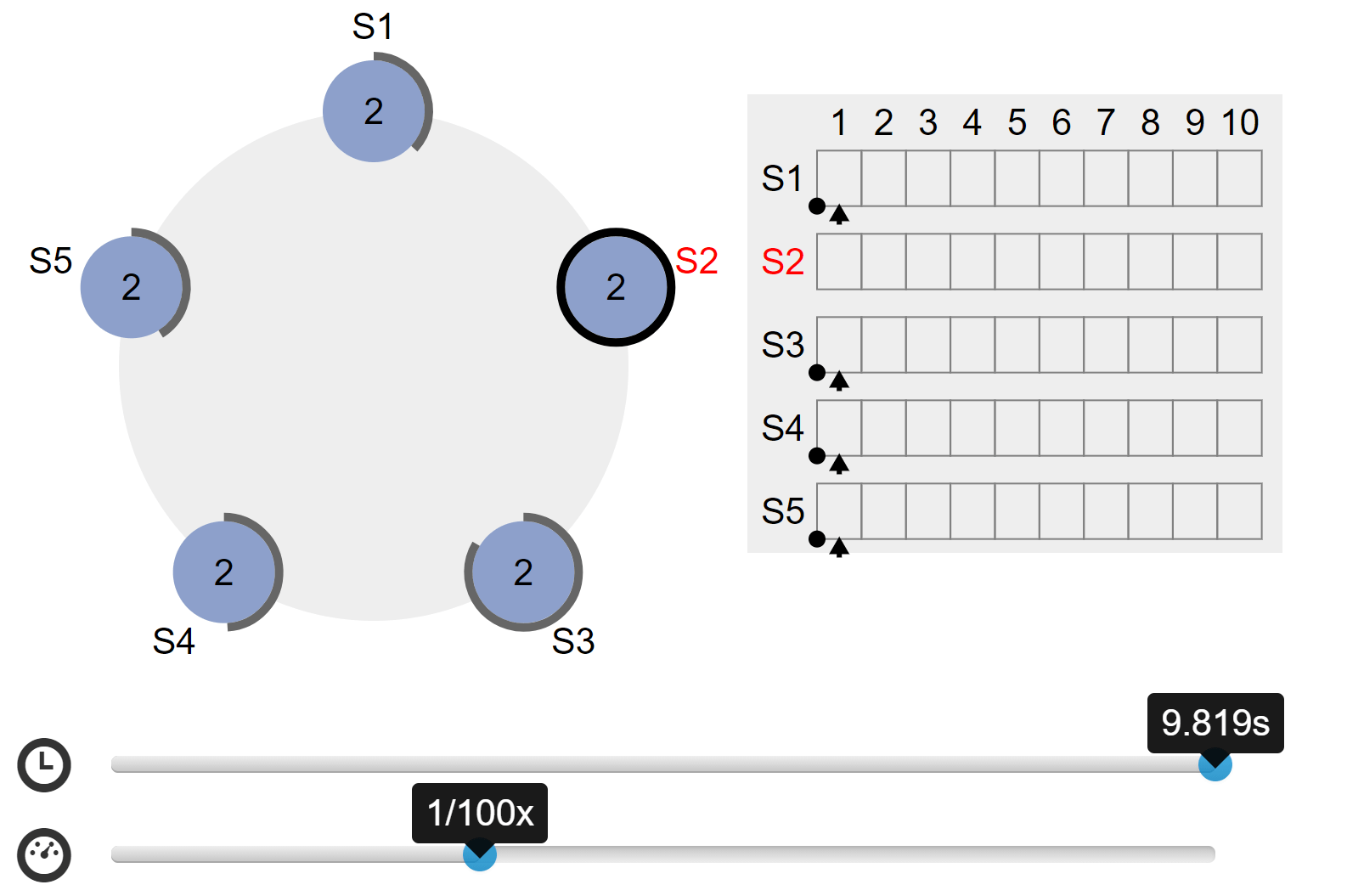
看动态的gif可以到https://raft.github.io/
如何选举领导者?
Raft 是通过以领导者为准实现各个节点日志一致的一种共识算法,被越来越多的分布式系统框架应用,比如 Etcd、Consul 等等,Seata 未来也会引用 Raft,即将发布的 Kafka 2.8 也引入了 Raft,在 Raft 的基础上做了一些改版,在 Kafka 2.8 中称作 KRaft。
由此看来,Raft 是目前大部分分布式系统的首选共识算法,学习 Raft 将有助于你在分布式领域中如鱼得水。
本文主要内容为我对 Raft 选举领导者的一些理解总结。
成员
按照我的理解,Raft 是一种强领导者模型,即一切以领导者为准,实现一系列的共识和各个节点日志一致性的一种共识算法。
Raft 一共有三种成员身份,分别是:领导者(Leader)、跟随者(Follower)、候选人(Candidate)。
跟随者:在 Raft 中只有领导者才会与客户端交互,因此在不发生选举时,跟随者仅默默地处理来自领导者发送的消息,充当数据冗余的作用,当领导者心跳超时,跟随者就会主动推荐自己当选候选人。
候选人:成为候选人之后,就会向其他节点发送请求投票消息,以获取其他节点的投票,如果获得了大多数选票,则当选领导者。
领导者:数据一切以领导者为准,它也是与客户端交互的唯一角色,处理请求,管理日志的复制,同时还不断地发送心跳信息给跟随者,不断刷新跟随者节点的超时时间,以防跟随者发起新的选举。
选举过程
下面我以一个刚初始化的 Raft 集群为例:
1、初始状态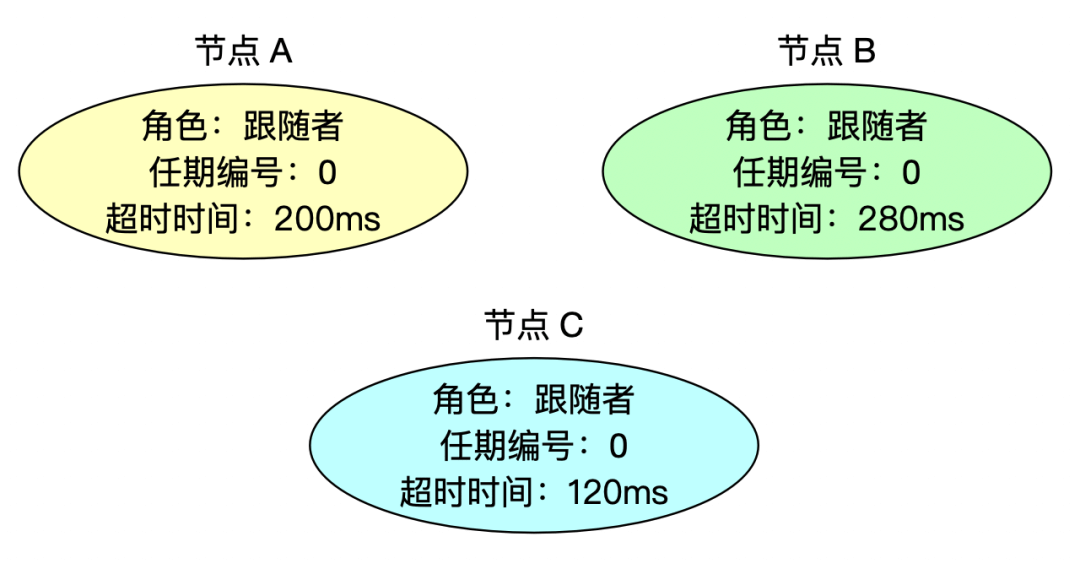
Raft 每个节点初始化后的心跳超时时间都是随机的,如上所示,节点 C 的超时时间最短(120ms),任期编号都为 0,角色都是跟随者。
2、请求投票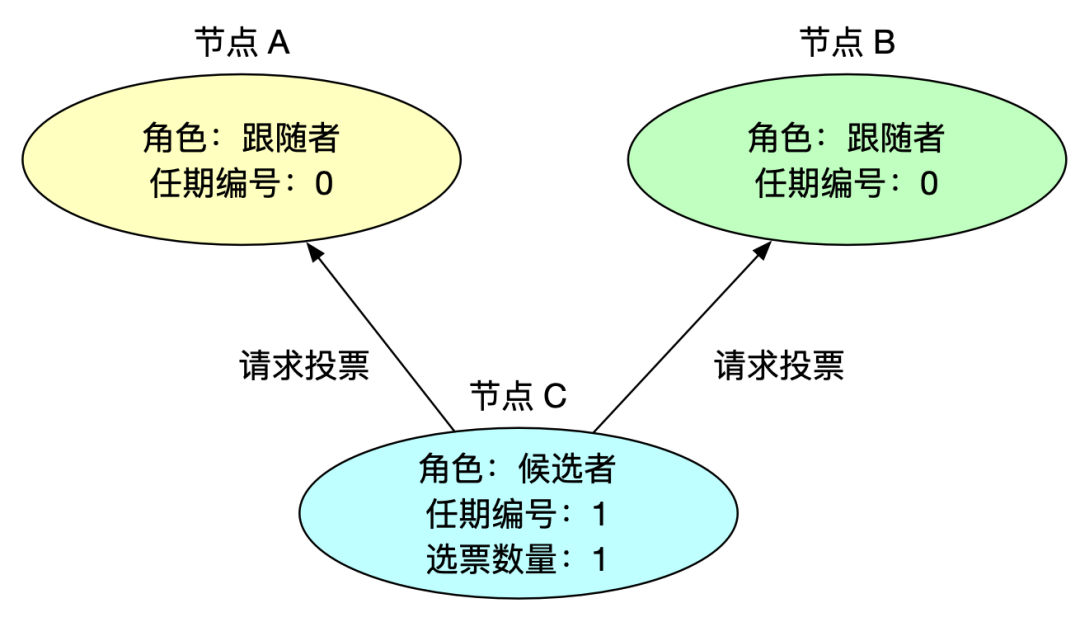
此时没有一个节点是领导者,节点等待心跳超时后,会推荐自己为候选人,向集群其他节点发起请求投票信息,此时任期编号 +1,自荐会获得自己的一票选票。
3、跟随者投票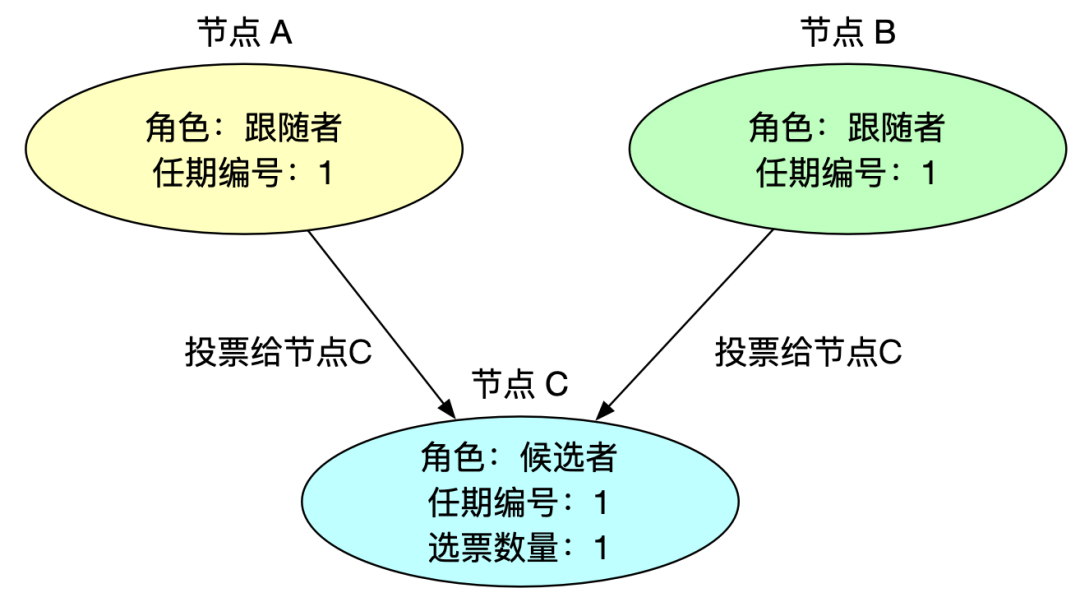
跟随者收到请求投票信息后,如果该候选人符合投票要求后,则将自己宝贵(因为每个任期内跟随者只能投给先来的候选人一票,后面来的候选人则不能在投票给它了)的一票投给该候选人,同时更新任期编号。
4、当选领导者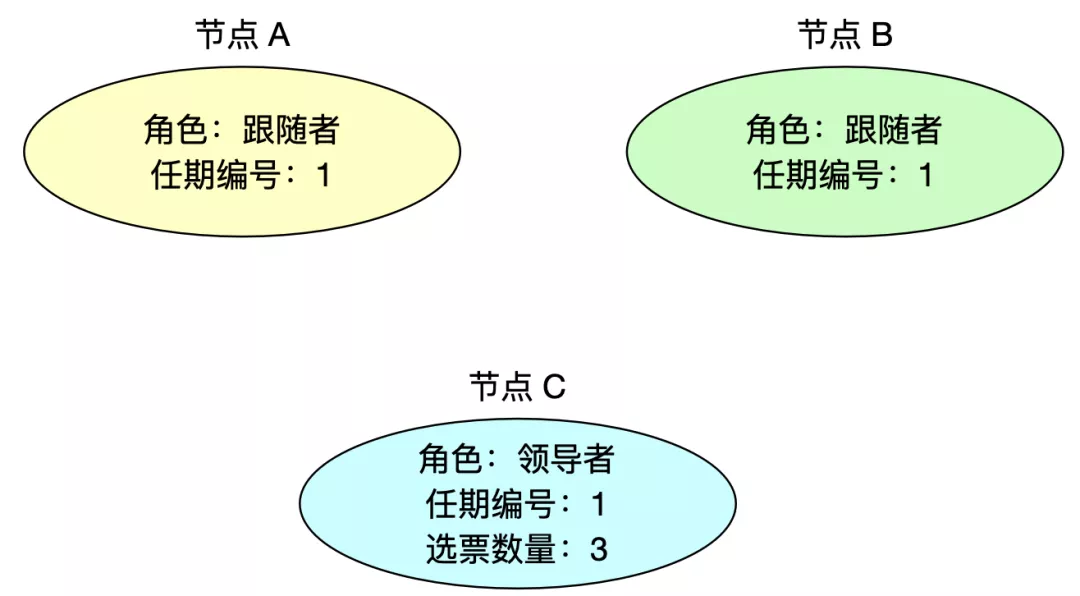
当节点 C 赢得大多数选票后,它会成为本次任期的领导者。
5、领导者与跟随者保持心跳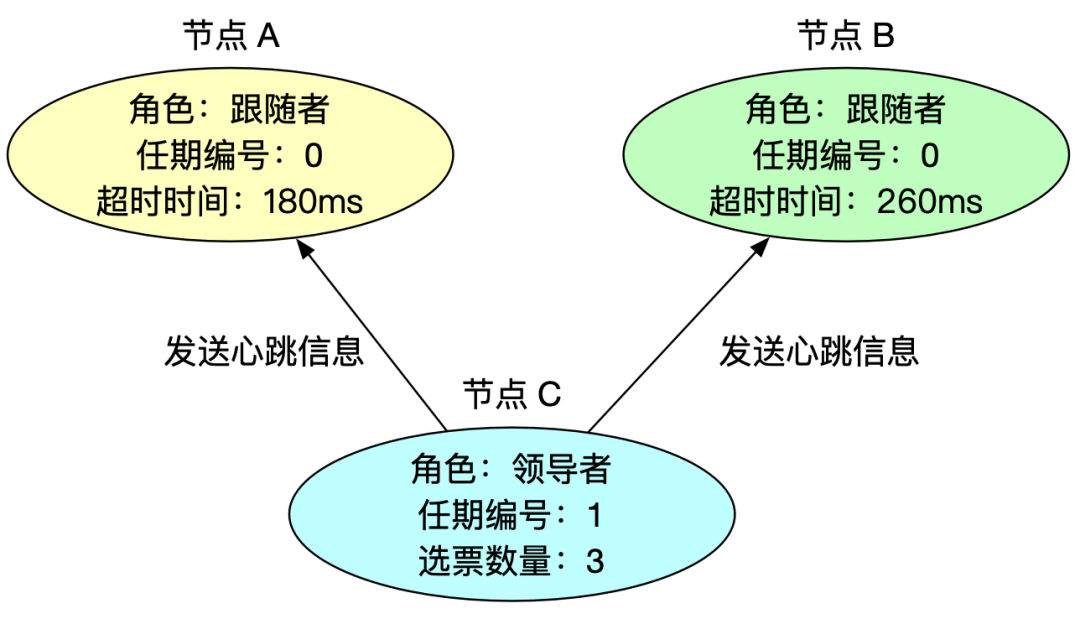
领导者周期性发送心跳消息给其他节点,告知自己是领导者,同时刷新跟随者的超时时间,防止跟随者发起新的领导者选举。
关于任期
从以上的选举过程看,我们知道在 Raft 中的选举中是有任期机制的,顾名思义,每一任领导者,都有它专属的任期,当领导者更换后,任期也会增加,Raft 中的任期还要注意以下个细节:
- 如果某个节点,发现自己的任期编号比其他节点小,则会将自己的任期编号更新比自己更大的值;
- 从上面的选举过程看出,每次推荐自己成为候选人,都会得到自身的那一票;
- 如果候选人或者领导者发现自己的任期编号比其它节点还要小,则会立即更新自己为跟随者,这点很重要,按照我的理解,这个机制能够解决同一时间内有多个领导者的情况,比如领导者 A 挂了之后,集群其他节点会选举出一个新的领导者 B,在节点 A 恢复之后,会接收来自新领导者的心跳消息,此时节点 A 会立即恢复成跟随者状态;
- 如果某个节点接收到比自己任期号小的请求,则会拒绝这个请求。
关于随机超时
跟随者如果没有在某个时间内接收到来自领导者的心跳,则会发起新一轮的领导者选举,试想一下,如果全部跟随者都在同一时间发起领导者选举,这是一种怎样的场景?会不会造成同一时间内造成选举混乱呢?如果同时发起选举,会不会因为选票被瓜分导致选举失败的原因?
感觉会出现很多问题,但是 Raft 它利用随机超时巧妙地避开了这些问题。

若有收获,就点个赞吧
0 人点赞
