摘要
With the proliferation of online social networks, the identification or classification of real-life relationship between users hasbeen very useful for many applications such as financial fraud detection. In real life, usually people with different relationships wouldpresent gifts with special meanings to each other on different dates. In many Asian cultures, especially in Chinese culture, the redpacket is a traditional form of monetary gift. With the rapid development of the Internet, people gradually began to give electronic redpackets instead of paper ones as the means of money gifting on social network platforms. As motivated, in this paper we advocate a novel approach that exploits users’ red packet interactions for users relationship identification on WeChat, one of the largest socialplatforms in China. Specifically, we analyze the WeChat red packets network, identify the real-life relationship types between usersthrough mining the semantic information of the amount and sending time of each red packet. In order to better capture the red packetgifting behaviors between users for relationship identification, on one hand, we construct an Amount-Date Graph and apply the graph embedding method to learn embeddings of the amount and sending date of each red packet. On the other hand, we propose a novelsequential model, Cross & Attention Sequence Model (CASM), which explicitly learns the interactions between the latent semanticinformation of each red packet’s amount and sending date in the red packets sequence between two users. To validate our approach,we conduct comprehensive experiments on a real-world WeChat Users Red Packets dataset that involves 8 kinds of real-liferelationships. The experiments show that our proposed approach performs significantly better than baselines and achieves 81.70%prediction accuracy.
随着在线社交网络的激增,用户之间真实生活关系的识别或分类对于许多应用程序(例如金融欺诈检测)已经非常有用。在现实生活中,通常具有不同关系的人会在不同的日期互相赠送具有特殊含义的礼物。在许多亚洲文化中,尤其是在中国文化中,红包是一种传统形式的金钱礼物。随着互联网的飞速发展,人们逐渐开始以电子红包代替纸质红包作为在社交网络平台上的赠礼手段。为此,我们提倡一种新颖的方法,该方法利用用户的红包交互来在微信(中国最大的社交平台之一)上识别用户关系。具体来说,我们分析微信红包网络,通过挖掘每个红包的数量和发送时间的语义信息,确定用户之间的现实关系类型。为了更好地捕获用户之间的红包行为,以进行关系识别,一方面,我们构造了一个金额-日期图,并应用图嵌入方法来学习每个红包的数量和发送日期的关系。另一方面,我们提出了一种新颖的时序模型,即交叉与注意序列模型(CASM),该模型准确学习了每个红包金额的潜在语义信息与两个用户之间的红包序列中的发送日期之间的相互作用。为了验证我们的方法,我们对涉及8种真实生活关系的真实世界的“微信用户红包”数据集进行了全面的实验。实验表明,我们提出的方法的性能明显优于基线,并且可以达到81.70%的预测精度。
Introduction
In most cultures, gift-giving is a long-standing way tomaintain and express relationships. The forms of giftsare varied and the same gift may have different meanings indifferent cultural contexts. In East Asian cultures, especially Chinese culture, people usually put cash in a red packet asa gift for others on special dates or on some momentousoccasions like wedding, birthday party, graduation cere-mony and so on. As the popularity of social networkingand mobile payment, quite a lot of Chinese people are usedto giving electronic red packets instead of cash. The redpackets gifting behavior between users on social networksis largely influenced by their real-life relationships. Peoplewith different relationship types tend to send red packetswith different amounts of money and on different dates,which involves the Chinese homonym and Chinese culture.For instance, “520” and “I love you” have similar pronunci-ations in Chinese, so on Valentine’s Day or May 20, couplesoften give red packets with an amount of 520 to expresstheir love. Another easy-to-understand example is that “8” implies making a fortune in Chinese culture, so co-workersoften give away red packets related to “8”. Figure 1 gives anexample to illustrate different red packets gifting patterns among users of different relationships.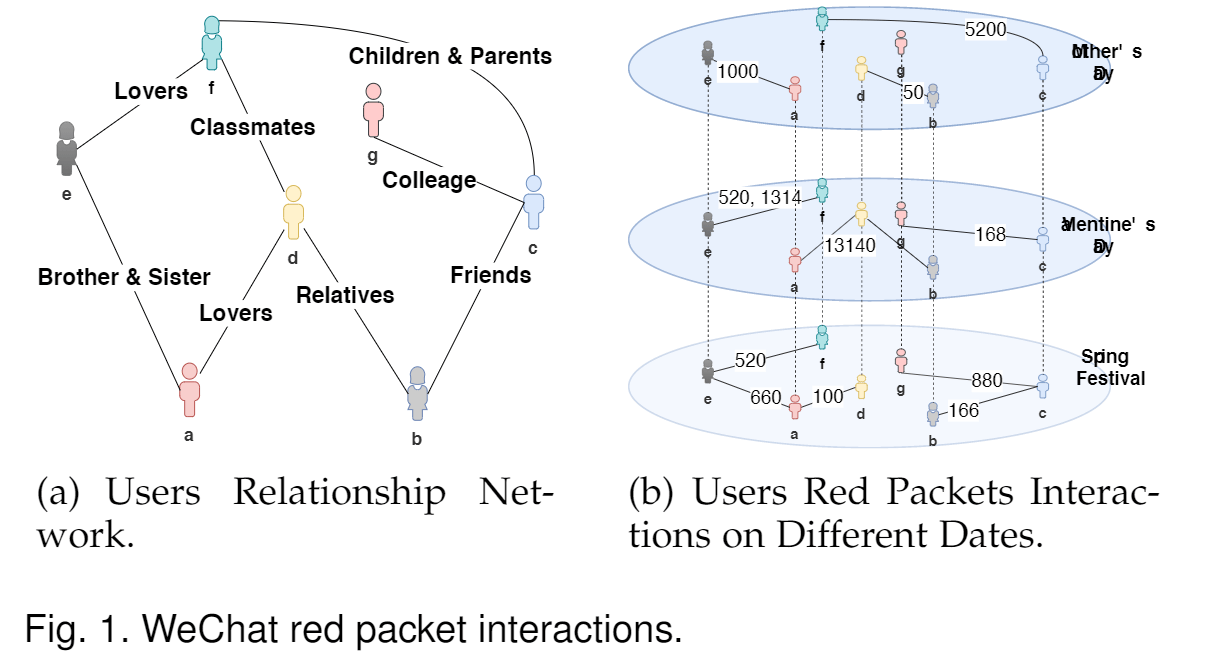
在大多数文化中,送礼是维持和表达人际关系的一种长期方法。礼物的形式多种多样,相同的礼物在不同的文化背景下可能具有不同的含义。在东亚文化中,尤其是中国文化中,人们通常在特定的日期或在某些重要场合,例如婚礼,生日聚会,毕业典礼等上,将红包作为礼物送给其他人。随着社交网络和移动支付的普及,相当多的中国人习惯于提供电子红包而不是现金。用户之间在社交网络上的重礼包礼物行为很大程度上受其现实生活关系的影响。关系类型不同的人倾向于在不同的日期发送不同金额的红包,这涉及中文同音异义词和中国文化。**例如**,“ 520”和“我爱你”的中文发音相似,因此情人的在5月20日(一天或5月20日),对夫妇送出520的红包以表达对他们的爱。另一个易于理解的示例是“ 8”意味着在中国文化中发了大财,因此同事软化了与“ 8”相关的红色包装。图1给出了一个示例,说明了不同关系用户之间的不同红包赠礼模式。
On the premise of complying with security and privacy policies, many applications may be benefit from userrelationship features. For example, utilizing user relationslike workmates and transaction relations can help to detectfinancial fraud on Alipay [2]. In general, we can betterunderstand users’ social role and social circle if we havethe information about their real-life relationships. Indeed,in recent years, researchers have reported that a wide rangeof applications can benefit from exploiting the relationshipsbetween users on social network such as financial frauddetection [2], [3], [4], secure routing in mobile network[5] and communities detection [6]. In the financial frauddetection task, user relationship information can be used forlearning more comprehensive user representations [3]. Be-sides, since very few users are labeled in this task, user socialrelations can be used to extend unlabeled samples for semi-supervised learning [2]. Exploiting the information about user relationships can help models better detect fraudstersthereby protecting users and providers.
在遵守安全和隐私策略的前提下,许多应用程序可能会受益于用户关系功能。例如,利用诸如同事之类的用户关系和交易关系可以帮助检测支付宝上的财务欺诈[2]。总的来说,如果我们了解用户的现实生活关系,就可以更好地了解他们的社交角色和社交圈。确实,近年来,研究人员已经报告说,利用社交网络上用户之间的关系,例如金融欺诈检测[2],[3],[4],移动网络中的安全路由[5]和社区,可以从各种应用程序中受益。检测[6]。在财务欺诈检测任务中,可以使用用户关系信息来学习更全面的用户表示[3]。另外,由于在此任务中标记的用户很少,因此用户社交关系可用于扩展未标记的样本以进行半监督学习[2]。利用有关用户关系的信息可以帮助模型更好地检测欺诈行为,从而保护用户和提供者。
Several prior literatures have attempted to identify userrelationships on open online social networks such as sinaweibo [7], [8] and Facebook [9]. For an open social network,many of the user’s attributes are public, and the interactioninformation between users is easily available, such as postforwarding, mentioning, sharing of pictures and tweets, andthe giving thumbs-up. Besides, for relationship identifica-tion task on open social networks, researchers usually usethe rich text information to generate features for modeltraining. However, many open social network users areactually strangers, and they may not know each other intheir real life.
一些现有文献试图在开放的在线社交网络上识别用户关系,例如新浪微博[7],[8]和Facebook [9]。 对于开放的社交网络,许多用户属性是公开的,并且用户之间的交互信息很容易获得,例如后转发,提及,图片和推文共享以及赞扬。 此外,对于开放式社交网络上的关系识别任务,研究人员通常使用富文本信息来生成用于模型训练的功能。 但是,许多开放的社交网络用户实际上是陌生人,他们在现实生活中可能彼此不认识。
In this paper, we focus on the task of identifying the real-life relationship between users of WeChat, one of the largestsocial network platforms with more than a billion monthlyactive users. Since WeChat launched the red packet applica-tion in 2014, more and more users have sent electronic redpackets on WeChat [10], [11]. Figure 2 shows the interfaceof the WeChat red packet application and Figure 3 presentsan instance of red packet sending and receiving on WeChat.It’s a challenging but significant task to identify user real-life relationships on WeChat. On one hand, WeChat is anacquaintance social networking platform [12] where users’interactions usually involve their real-life relationships. Onthe other hand, the textual information generated by user in-teractions is not available due to privacy protection policies.Besides, it’s difficult to obtain sufficient and accurate userprofiles for user representation. Taking the characteristics ofthe WeChat platform into consideration, we aim at identi-fying the user real-life relationship types according to theirred packets gifting behavior. Intuitively, this is feasible sinceWeChat users with active interactions are usually acquain-tances in real life, and their red packets gifting behaviorwould contain rich hidden knowledge about their real-life relationships. Nevertheless, due to the highly dynamicnature of red packet interactions, how to build a sound model for efficient relationship prediction is non-trivial.
在本文中,我们专注于识别微信用户之间的现实关系,微信是最大的社交网络平台之一,每月活跃用户超过十亿。自2014年微信推出红包应用程序以来,越来越多的用户在微信上发送了电子红包[10],[11]。图2显示了微信红包应用程序的界面,图3展示了在微信上发送和接收红包的实例。在微信上识别用户的现实关系是一项艰巨而艰巨的任务。一方面,微信是熟人社交网络平台[12],用户的互动通常涉及他们的现实生活关系。另一方面,由于隐私权保护政策,用户互动时生成的文本信息不可用。此外,很难获得足够准确的用户个人资料来表示用户。考虑到微信平台的特点,我们旨在根据用户的红包赠送行为来识别他们的真实生活关系类型。从直觉上讲,这是可行的,因为具有活跃交互作用的微信用户通常是现实生活中的熟人,而他们的红包礼物行为将包含有关其现实生活关系的丰富隐藏知识。然而,由于红包交互的高度动态性,如何构建用于有效关系预测的声音模型并非易事。
Specifically, in order to capture the latent semantic infor-mation of each red packet, we first construct the Amount-Date Graph (ADG) to indicate the correlation between theamount and the sending date of each red packet. The nodeson ADG consists of the amounts and the sending dates ofeach red packet. ADG is an undirected weighted graph,and the weight of the edge represents the degree of corre-lation between the amount node and the date node. Thenwe apply graph embedding method to generate embed-dings for each amount and date. With the carefully definedweights of edges that connect amounts and sending dates,the generated embeddings are able to reflect the semanticsimilarity between nodes. For instance, the Valentine’s Dayand Chinese Qixi Festival, known as Chinese Valentine’sDay, are very close in semantics, although these two datesare separated by months. To address the problem of lack ofsufficient user attributes, we generate user embeddings viagraph embedding as well. In this way, we can represent eachuser with a low dimensional dense vector which containsthe topology information of user red packet interactionnetwork.
具体来说,为了捕获每个红包的潜在语义信息,我们首先构造金额-日期图(ADG)来指示每个红包的金额和发送日期之间的相关性。 **ADG上的节点由每个红包的金额和发送日期组成。 ADG是无向加权图,边缘的权重表示金额节点和日期节点之间的相关程度。然后我们应用图嵌入的方法为每个金额和日期生成嵌入。通过精心定义的连接金额和发送日期的边的权重,生成的嵌入能够反映节点之间的语义相似性。**例如,情人节和中国七夕节在语义上非常接近,尽管这两个日期之间相隔数月。为了解决用户属性不足的问题,我们还通过图形嵌入生成了用户嵌入。这样,我们可以用一个低维的密集向量表示每个用户,该向量包含用户红包交互网络的拓扑信息。
In practice, every pair of users may have multiple redpackets interactions at different times which can be formedas an ordered sequence of red packets. In order to betterlearn the semantics of each red packet that involves areal-life relationship type, we propose a novel graph-basedapproach, Cross & Attention Sequence Model (CASM) forWeChat user real-life relationship identification problem.For each pair of users, a red packet in the red packetssequence is initially represented by the date embedding andamount embedding. Considering the amount of money in red packets indicates a lot of information in Chinese culture,we firstly exploit graph attention network to update theamount embedding for each amount node in Amount-DateGraph. The preserved neighbors of each amount node aretop-k other amount nodes with the largest cosine similarityin the embedding space. Secondly, we apply vector-awarefeature cross to generate the red packet representation.Then, we input the red packets sequence into a LSTM modelto capture the temporal dependencies of different red pack-ets. Last but not the least, we exploit user representationsand hidden state vectors of LSTM to train a attention layerand eventually get a integrated latent representation of userred packet interactions for downstream classification. Theembedding layer of CASM is initialized with the results ofthe graph embedding method, which preserves the semanticinformation of the sending date and amount for red packetrepresentations and the topology information of WeChat users graph for user representation. With the feature inter-action and attention mechanism, CASM is able to efficientlyutilize the semantic information of each red packet and theuser representations.
在实践中,每对用户在不同时间可能具有多个红包交互,这些交互可以形成为红包的有序序列。为了更好地了解每个涉及区域生命关系类型的红包的语义,我们针对微信用户真实生活关系识别问题提出了一种新颖的基于图的方法,交叉和注意力序列模型(CASM)。红包序列中的红包最初由日期嵌入和数量嵌入表示。考虑到红包的金额在中国文化中表明了大量信息,我们首先利用图注意力网络来更新ADG中每个金额节点的金额嵌入。每个数量节点的保留邻居是嵌入空间中余弦相似度最大的前k个其他数量节点。其次,我们使用向量感知特征叉生成红包表示形式,然后将红包序列输入到LSTM模型中以捕获不同红包集的时间相关性。最后但并非最不重要的一点是,我们利用LSTM的用户表示和隐藏状态向量来训练关注层,并最终获得用户红包交互的集成潜在表示,以进行下游分类。图嵌入方法的结果初始化了CASM的嵌入层,该方法保留了红包表示的发送日期和发送金额的语义信息以及用户表示的微信用户图的拓扑信息。通过功能交互和关注机制,CASM能够有效利用每个红包和用户表示的语义信息。
To summarize, this paper makes the following contribu-tions:
•We analyze the users money-gifting behavior and identify users real-life relationship on WeChat, oneof the largest social network platforms in China. Toour best knowledge, this paper is the first attemptto identify users real-life relationships using realistic WeChat datasets.
•We propose a graph embedding based approach tolearn the semantics of red packets via constructingthe Amount-Date Semantics Graph and User-UserInteraction Graph.
•Based on the analysis of red packet gifting onWeChat and red packet embeddings, we accordinglypropose a novel Cross & Attention Sequence Model(CASM) for WeChat users real-life relationship iden-tification problem.
•We conduct comprehensive experiments on a large-scale real world WeChat dataset with eight differ-ent common relationship types. The experimentsdemonstrate that exploiting red packet interactionsis very effective for real-life relationship identifica-tion, and our approach achieves a high accuracy of 81.70%.
The rest of our paper is organized as follows. In Section 2, we analyze the users red packets gifting behavioron WeChat. Our proposed approach will be presented inSection 3. We will introduce the experiments on WeChat and analyze the results in Section 4. In Section 5, we brieflyintroduce some related work. Finally we give our conclusionin Section 6.
总而言之,本文做出了以下贡献:
•我们在中国最大的社交网络平台之一的微信上分析了用户的红包行为,并确定了用户的真实生活关系。尽力而为,本文是首次尝试使用真实微信数据集识别用户的现实关系。
•我们提出了一种基于图嵌入的方法,通过构造金额-日期语义图和用户-用户交互图来学习红包的语义。
•基于对微信中的红包赠予和红包嵌入的分析,我们针对微信用户的现实生活中的身份识别问题提出了一种新的交叉注意序列模型(CASM)。
•我们对具有八种不同共同关系类型的大规模现实世界微信数据集进行了综合实验。实验表明,利用红包交互作用对现实生活中的关系识别非常有效,我们的方法达到了81.70%的高精度。
本文的其余部分安排如下。在第二节中,我们分析了在微信上用户的红包赠送行为。我们提出的方法将在第3节中介绍。我们讲介绍微信上的实验,并在第4节中分析结果。在第5节中,我们简要介绍一些相关工作。最后,我们在第6节中给出结论。
2 ANALYSIS OF WECHAT RED PACKET
In this section, we will first provide a formal problemdefinition. Then we describe our real-world WeChat datasetand illustrate our findings and insights via comprehensivedata analysis.
在本节中,我们将首先提供一个正式的问题定义。然后我们描述了真实世界的微信数据集,并通过全面的数据分析说明了我们的发现和见解。
2.1 Problem Statement
WeChat is a large scale social network, where users’ in-teractions are mostly based on their real-life relationship.Users do not need to provide their profile and the userprofile could contain bogus information, which leads tothe difficulty of utilizing users attributes to predict theirrelationship. Given the user red packet exchange records,basic demographic attributes X and the defined relationshiptypesY={0,1,2,···,M} where M is the number of different relationship types, the problem of identifying userrelationship on WeChat money-gifting network can be de-fined as a multi-classification problem. Hence, given a userspair(ua,ub)who have red packet interactions and their redpacket interaction sequences{(t1,a1),(t2,a2),···,(tn,an)}where ti and ai are the sending date and amount ofi-th redpacket, our purpose is to predict which relationship typebetween these two users is.
微信是一个大规模的社交网络,用户的互动主要基于他们的真实生活关系,用户无需提供个人资料,并且用户资料中可能包含虚假信息,这导致难以利用用户属性进行预测他们的关系。 给定用户红包交换记录,基本人口统计属性X和定义的关系类型Y = {0,1,2,···,M}其中M是不同关系类型的金额,在微信红包上识别用户关系的问题 网络可以定义为一个多分类问题。 因此,给定一个具有红包交互及其红包交互序列{(t1,a1),(t2,a2),···,(tn,an)}的用户对(ua,ub)},其中ti和ai是发送者 第i个红包的日期和金额,我们的目的是预测这两个用户之间的关系类型。
2.2 Data Description
In this paper, we use a real world WeChat Red Packets dataset sampled from anonymized logs between July 23th,2018 to 20th May, 2019. To protect users’ privacy, the datasetwas desensitized and users’ identifies were anonymized before we access, which is similar to the previous researchon WeChat red packets [13]. The dataset is large scale, whichcontains 38,910,249 red packets records which involves3,977,824 users. Each user in this dataset is represented withencrypted user ID which we can not track back the real useractually for privacy, and brief user profile including genderand age.
•Red Packets RecordsR. Each red packets recordis described by a tuple(senderID,receiverID,a,t)whereais the amount of money in the red packetandtcorresponds to the sending time.<br /> •User SetU. It contains all users that have red packetsinteraction behavior in our dataset. Each user isdescribed as a tuple(ID,Gender,Age).<br /> •Relationships LabelL. It contains of all tuples(u,v,y)where useru,v∈ Uhave relationship typesy∈Y. The labels setYconsist of 8 different real liferelationship types which are described in Table 1.
在本文中,我们使用了一个真实世界的微信红包数据集,该数据集是在2018年7月23日至2019年5月20日之间从匿名日志中采样的。之前对微信红包的研究[13]。该数据集规模庞大,包含38,910,249个红包记录,涉及3,977,824位用户。该数据集中的每个用户都用加密的用户ID表示,我们无法从实际角度追溯真实用户的隐私,以及简短的用户配置文件(包括性别和年龄)。
•红包记录R。每个红色数据包记录都由一个元组(senderID,receiverID,a,t)描述,其中红色数据包中的金额与发送时间相对应。
•用户Set U。它包含我们数据集中所有具有红包交互行为的用户。每个用户都被描述为一个元组(ID,性别,年龄)。
•关系标签 L。它包含所有元组(u,v,y),其中用户u,v∈U具有关系类型y∈Y。标签集Y由8种不同的实际生活关系类型组成,如表1所示。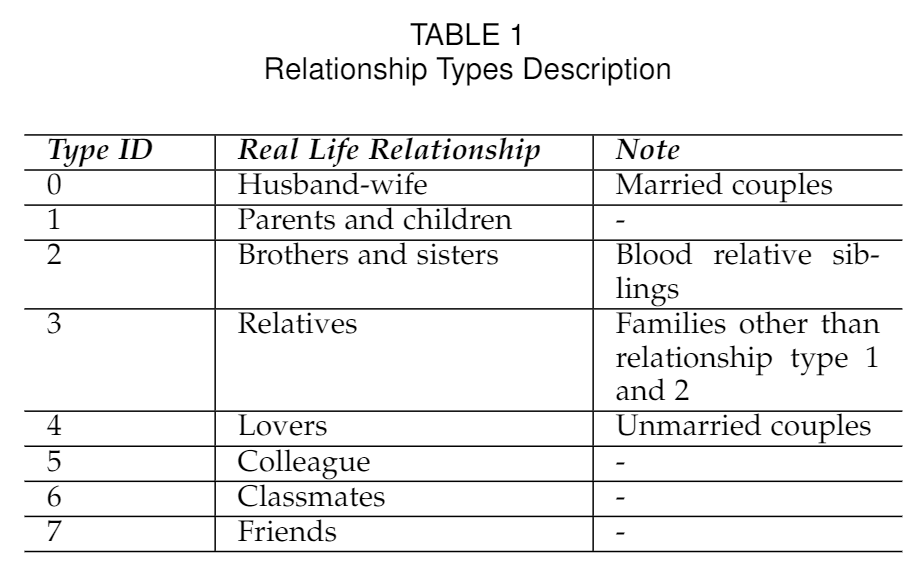
2.3 Data Analysis
In this subsection, we analyze red packets gifting behaviorof WeChat users. In general, people’s gift-giving behav-ior is mainly influenced by their relationship types and demographic attributes. The empirical data analysis weperform in this paper can help us to understand the money-gifting patterns of users on WeChat social network and gaininsights for the user relationship identification task.
Relationship Effects. Figure 4 shows the average num-ber of red packets sent involves different relationship types.
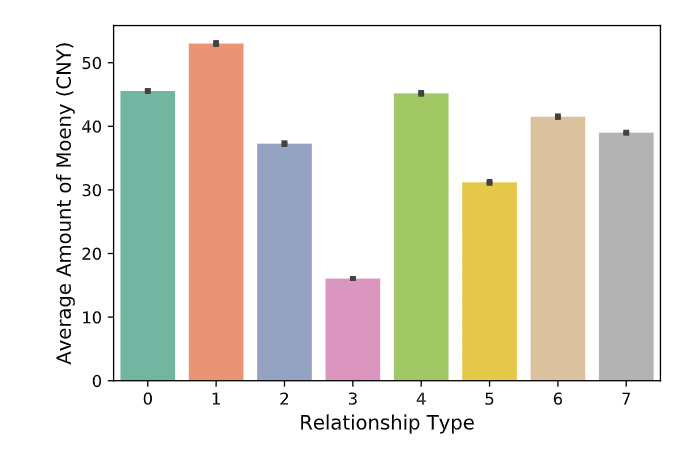
It demonstrates that there are obviously more red packetinteractions between husband and wife, and the red packetsare not often sent between the classmates. In addition,there are more red packets interactions between users whohave intimate relationships such as family while users whoare distantly related are less likely to give each other redpackets. Figure 5 shows the average amount of money in redpackets corresponding to different relationship types. It im-plies that red packets sent between parents and children aremore likely to contain larger amounts. This may be becausemany parents use the WeChat red packet application to paythe children’s living expenses and the larger amount of NewYear’s lucky money. Although the number of red packetinteractions between classmates are quite small, we can findfrom this figure that the average amount of red packets sentbetween the them is relatively large. However, as a meansof maintaining relationships and expressing feelings, strongfeelings and intimate relationships do not necessarily meana larger amount of red packets. In traditional culture, some numbers are given special meanings because of the homo-phonic. For example, “8.88” and “8888” are both consideredto be the meaning of blessing fortune in Chinese culture,although they differ greatly in numerical value.
在本小节中,我们将分析微信用户的红包赠送行为。通常,人们的送礼行为主要受他们的人际关系类型和人口统计属性的影响。本文的经验数据分析可以帮助我们了解微信社交网络上用户的赠礼方式,并获得对用户关系识别任务的见解。
关系影响。图4显示发送的红包涉及不同关系类型的平均数量。
它表明,夫妻之间明显有更多的红包互动,并且红包很少在同学之间发送。此外,在具有亲密关系的用户(例如家庭)之间存在更多的红包交互,而关系更疏远的用户则不太可能互相发红包。图5显示了与不同关系类型相对应的红包中的平均金额。这意味着父母和孩子之间发送的红包中包含更大的金额。这可能是因为许多父母使用微信红包应用程序来支付孩子们的生活费和大量的新年幸运钱。尽管同学之间的红包交互的数量非常少,但从该图我们可以发现,他们之间发送的红色数据包的平均数量相对较大。然而,作为维持关系和表达感情的一种手段,强烈的感情和亲密关系不一定意味着大量的红包。在传统文化中,由于谐音,一些数字被赋予特殊的含义。例如,“ 8.88”和“ 8888”虽然在数值上有很大差异,但在中国文化中都被认为是福气的意思。
In traditional Chinese culture, red packets are usuallysent by elders to juniors during the Spring Festival, which iscalled “luck money”. With the development of the economyand the popularity of electronic red packets, the gifting ofred packets is no longer restricted to the Spring Festivalor important occasions like weddings. People will sendred packets with different amount of money to each otheron different dates according to the relationships betweenthem. In order to illustrate the causal relationship betweendates and red packet gifting behavior among users withdifferent relationship types, we plot the ratio of the numberof red packets involved in each relationship type to the totalamount of red packets involved in the relationship type ondifferent dates. As shown in Figure 6, we can clearly seethat New Year’s Eve is the peak period for Chinese peopleto send red packets. Besides, Figure 6 indicates that WeChat users red packets gifting behavior does be affected by datesand their relationship types. For instance, couples are morelikely to send red packets on Qixi Festival or Valentine’s Dayand users who have parent-child relationships may tend tosend red packets on dates like Mother’s Day. Therefore, thesending dates of red packets indicate certain semantic infor-mation, which can be exploited to boost the performance ofuser relationship identification.
在中国传统文化中,春节期间,老年人通常会向小辈们发送红包,这被称为“利是”。随着经济的发展和电子红包的普及,红包的赠送不再局限于春节或婚礼等重要场合。人们将根据彼此之间的关系在不同的日期相互发送不同金额的钱包。为了说明日期和具有不同关系类型的用户之间的红包赠予行为之间的因果关系,我们绘制了每种关系类型中涉及的红包金额与不同日期上的关系类型中涉及的红包总数的比率。如图6所示,我们可以清楚地看到,除夕是中国人发送红包的高峰期。此外,图6表示微信用户的红包礼物行为的确受到日期及其关系类型的影响。例如,夫妻更有可能在七夕节或情人节发送红包,有亲子关系的用户可能倾向于在母亲节等日期发送红包。因此,红色数据包的发送日期表明了某些语义信息,可以用来提高用户关系识别的性能。
In order to visually reflect the intrinsic meaning of thered packet amount in Chinese, we take the red packetsgifting records between lovers on the Qixi Festival day as anexample. As shown in Figure 7, the amounts of red packetswith higher frequency have some romantic meanings. Tobe specific, all the amounts of “5.20”, “5.21” and “52.00”CNY mean “I love you” in Chinese cyber culture. The redpackets contain “13.14” CNY means “the whole lifetime”since they are pronounced alike. The amounts that contain“7” also has a higher frequency of appearance, because “7”and “kiss” have the similar Chinese pronunciation, and Qixiis the 7th July on the Chinese lunar calendar. Therefore,exploring and utilizing the semantic information broughtby the red packet amounts plays a very important role inour relationship identification task. Chinese cyber cultureis constantly evolving, and the inherent meaning of theamount of red packets will change accordingly. For instance,“6” symbolizes good luck in traditional Chinese culture, butin recent years young people have gradually given it themeaning of “impressive” and “awesome”.
为了直观地反映红色包装数量在中文中的内在含义,我们以七夕节恋人之间的红色包装礼物记录为例。如图7所示,频率较高的红色数据包的数量具有一些浪漫的意义。具体而言,在中国网络文化中,“ 5.20”,“ 5.21”和“ 52.00”人民币全部表示“我爱你”。红包中包含“ 13.14” CNY的含义是“整个生命周期”,因为它们发音相同。包含“ 7”的数量也出现频率更高,因为“ 7”和“ kiss”具有相似的中文发音,而七夕是中国农历的7月7日。因此,探索和利用红色数据包量带来的语义信息在我们的关系识别任务中起着非常重要的作用。中国网络文化在不断发展,红包数量的内在含义也将随之改变。例如,“ 6”象征着中国传统文化中的好运,但近年来,年轻人逐渐赋予它“令人印象深刻”和“令人敬畏”的含义。
Demographic Effects. We also explore the correlationbetween basic users demographic attributes and their red packets behavior patterns. As shown in Figure 8, thereis no significant difference between the average amountof red packets received by male users and female users, but the average sent amount of male users is larger thanthat of female users. Figure 9 shows the heatmap of thefrequency of red packets sent and received between sendersand receivers from different age groups. The darker colors represent the more red packets are sent and received. In thisway, the heatmap is very intuitive to show that the WeChat users red packet interactions frequently occur between users of similar ages. Besides, we can also see from Figure 9 thatthe WeChat red packets users have a large age span.Through the above data analysis, we have obtained someempirical conclusions about the patterns of WeChat usersred packet gifting behavior. These findings provide valu-able insights for relationship identification task on WeChatplatform. In general, users red packets interactions are mo-tivated by their real-life relationships and affected by theirdemographics. Moreover, the sending date and amount ofred packets implies the real-life relationships between users.
人口统计学影响。我们还探讨了基本用户人口统计属性与其红包行为模式之间的相关性。如图8所示,男性用户和女性用户平均收到的红包数量没有明显差异,但是男性用户的平均发送数量大于女性用户。图9显示了不同年龄组的发送者和接收者之间发送和接收红包频率的热图。较深的颜色表示发送和接收的红包越多。这样,热图非常直观地表明,微信用户的红包交互经常发生在相似年龄的用户之间。此外,从图9还可以看出,微信红包用户的年龄跨度较大。通过以上数据分析,我们得出了一些微信用户红包赠送行为模式的经验结论。这些发现为微信平台上的关系识别任务提供了有价值的见解。通常,用户的红包交互是受其现实生活的关系所激励,并受到其人口统计学的影响。此外,红包的发送日期和数量暗示着用户之间的现实关系。
3 MODELING APPROACHES
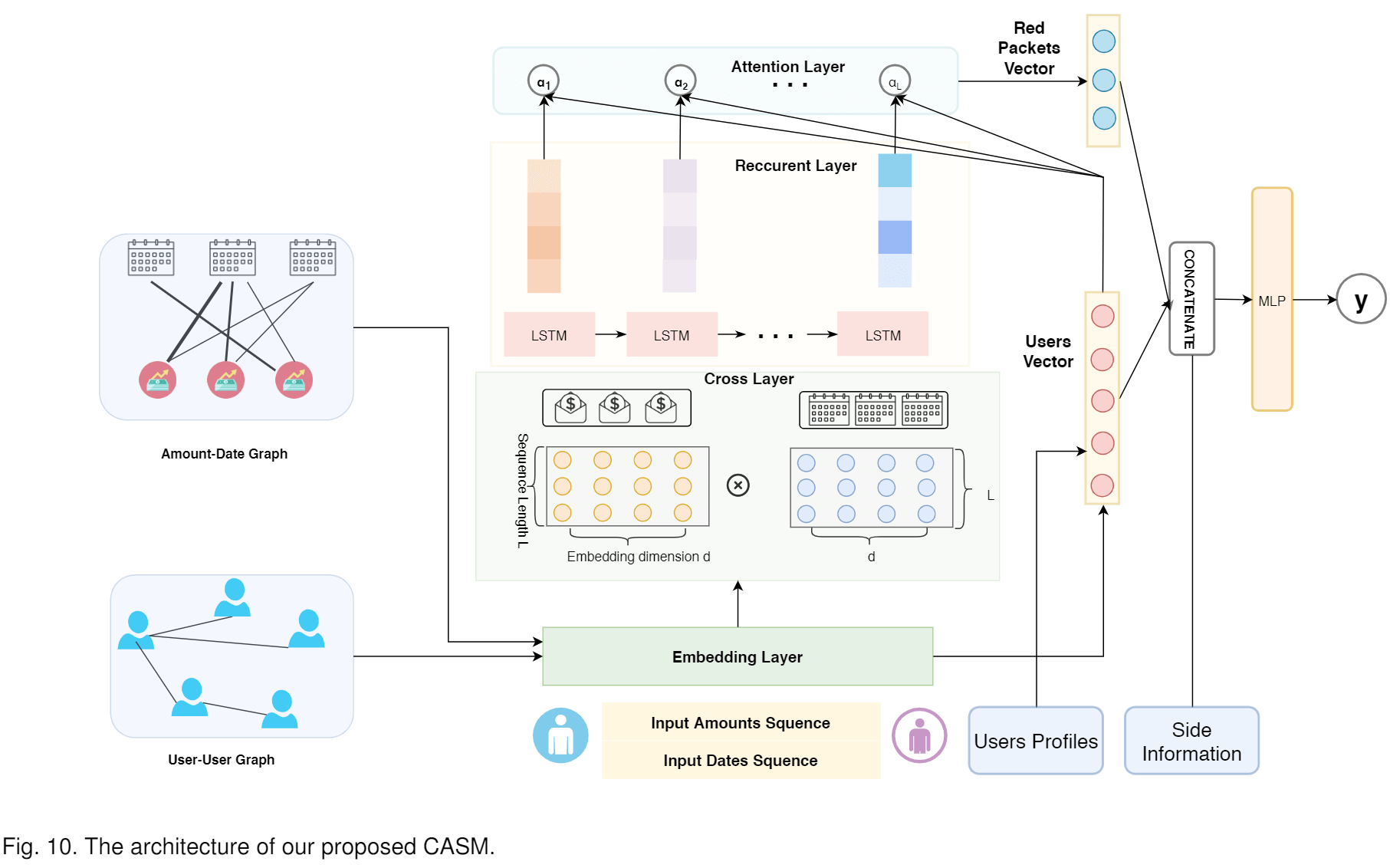
With the data analysis we discussed above, we found that itis feasible to identify the real-life relationship between usersthrough their red packet interactions. Therefore, we proposea relationship identification model which effectively learnsthe latent semantics of red packets as well as their interac-tion dynamics to identify users real life relationship types onWeChat. The overview of our proposed Cross & AttentionSequence Model (CASM) is shown in Figure 10. Firstly, weapply graph embedding over the amount-date graph anduser-user graph to generate initial embeddings. Secondly,we stack cross layers to capture the feature interactionsbetween sending amount embedding and date embedding,which can help model better capture the semantic informa-tion of each red packet. Thirdly, as a special kind of giftsexchange behavior, there are causal effects in the user redpacket interactions. Therefore, our model uses an LSTM tocapture the temporal dependencies of red packets. Afterthat, CASM uses the user-aware attention mechanism togenerate the final red packet interactions embedding. Lastbut not the least, the model integrates red packet interac-tions embedding, user representation and side informationfor classification.
通过上面讨论的数据分析,我们发现通过红包交互识别用户之间的现实关系是可行的。因此,我们提出了一种关系识别模型,该模型可以有效地学习红包的潜在语义及其交互动态,从而在微信上识别用户的现实生活中的关系类型。我们提出的交叉和注意力序列模型(CASM)的概述如图10所示。首先,我们在金额-日期图和用户-用户图上应用图嵌入,以生成初始嵌入。其次,我们通过堆叠跨层来捕获发送量嵌入和日期嵌入之间的特征交互,这可以帮助模型更好地捕获每个红包的语义信息。第三,作为一种特殊的礼物交换行为,用户红包交互中存在因果关系。因此,我们的模型使用LSTM捕获红包的时间依赖性。之后,CASM使用用户感知的注意力机制来生成最终的红包交互嵌入。最后但并非最不重要的一点是,该模型集成了红包交互嵌入,用户表示和辅助信息以进行分类。
3.1 Amounts & Dates Semantic Modeling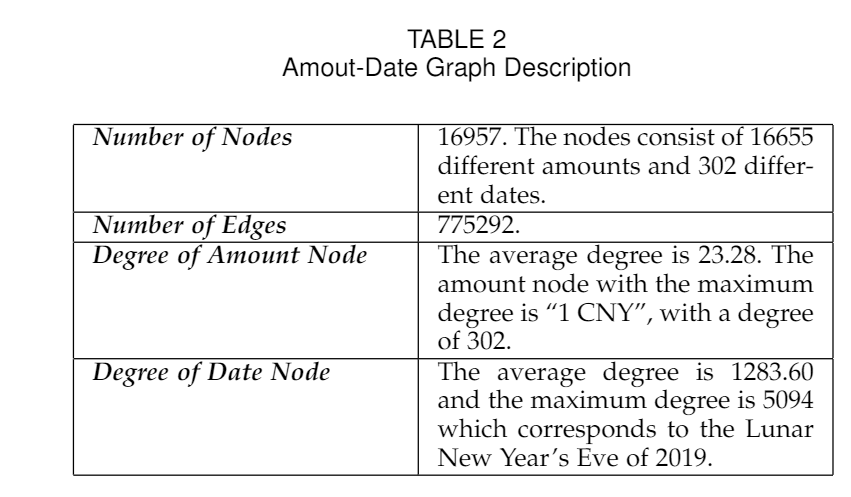
In order to capture the semantic meaning of the red packetsamount and date, a naive approach is to manually asso-ciate different amounts and dates with specific keywords.However, manually crafting comes with high cost and itis difficult to develop comprehensive rules. Users tendto send red packets with corresponding special meaningsamounts on some special dates, which inspires us to con-struct Amount-Date Graph (ADG) to indicate the asso-ciation between red packets amounts and correspondingsending date. The Amount-Date Graph is constructed as a undirected weighted bipartite GraphG= (V,E,W).Visthe set of nodes which consist of amount nodes and datenodes,Eis the edges set and we define an edgeeadbetweena date nodeNdand a amount nodeNaif there is a redpacket sent on datedwith amounta. The weight of edgeeadis calculated as:
为了捕获红包的金额和日期的语义含义,一种简单的方法是手动将不同金额和日期与特定的关键字相关联。但是,手工制作具有很高的成本,并且难以制定全面的规则。 用户倾向于在某些特殊日期发送具有相应特殊含义的金额的红包,这启发我们构造了金额日期图(ADG)来指示红包数量与相应的发送日期之间的关联。 Amount-Date图构造为无向加权二分图G =(V,E,W).V是金额节点和日期节点组成的节点集,E是边集,我们在日期节点和金额节点之间定义了一个边e(ad) 在日期d发送了带有金额a的红包。 边的权重计算为:
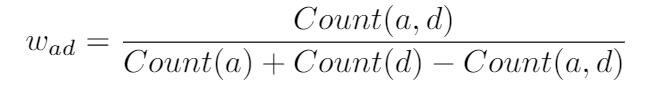
其中Count(a,d)代表包含日期上出现的数量的红包金额,Count(a)是所有日期上具有金额a的红包总数,Count(d)是过时发送的红色数据包总数。表2中描述了基于我们的微信数据集构建的数量数据图的描述。我们在ADG上应用Node2vec [14]以生成对出现在数据集中的所有金额和日期的嵌入。 Node2vec是一种广泛使用的无监督特征学习方法,用于图结构化数据,它通过有偏的随机游走程序来保持节点之间的接近度,并将生成的节点序列输入到跳过文法模型中[15]以获得节点嵌入。使用定义明确的ADG和图形嵌入方法,语义上相似的日期和数量将在特征空间中接近。在表3中,我们列出了一些具有特殊含义的数量及其重要的邻居节点(日期),它直观地表明了具有相似含义的节点具有相似的拓扑,因此我们可以通过图嵌入来了解金额和日期的含义。实际上,用户也可以在公共日期发送具有特殊含义的红包。因此,我们使用图神经网络来更新嵌入量,更好地理解每个红包的语义信息。对于ADG中的每个金额节点,我们找到了与其他金额节点最相似的k个节点。然后,我们应用图注意力网络[16]来汇总随后的信息,以更新每个金额节点的表示。这样,CASM可以更好地学习不同红包数量的这些语义关联。
where Count(a,d)represents the number of red packetscontaining the amountaappears on the dated,Count(a)is the total number of red packets with amountasent on all dates andCount(d)is the total number red packets sent ondated. The description of Amount-Data Graph constructedbased on our WeChat dataset is described in Table 2. Weapply Node2vec [14] on ADG to generate embeddings forall amounts and dates that appear in our dataset. Node2vecis a widely used unsupervised feature learning methodfor graph-structured data, it preserves proximity betweennodes via a biased random walk procedure and inputs thegenerated node sequences into the skip-gram model [15] toobtain nodes embedding. With the well-defined ADG andgraph embedding method, semantically similar dates andamounts will be close in the feature space. In Table 3, welist some amount with special meaning and their importantneighbor nodes (dates), it intuitively shows that nodes withsimilar meanings have similar topologies, and thus we canlearn the meaning of the amount and date through graphembedding. In practice, users may also send red packetswith special meaning amounts on common dates. Therefore,we use graph neural network to update amount embeddingand better understand the semantic information of each redpacket. For each amount node in the ADG, we find the k most similar other amount nodes as its neighbors. Then,we apply graph attention network [16] to aggregate theneighboring information for updating each amount noderepresentation. In this way, CASM can better learn thesemantic association of different red packet amounts.
3.2 User Modeling
WeChat is a large scale social network, where user interac-tions are mostly based on their real-life relationship. Usersdo not need to provide their detailed profiles and the userprofile could contain bogus information, which leads to the difficulty of user modeling. To address this problem,we generate user representation based on their interactionbehaviors from the WeChat users graph.
微信是一个大规模的社交网络,其中用户互动主要基于他们的真实生活关系。 用户不需要提供其详细的配置文件,并且该用户配置文件可能包含虚假信息,这导致用户建模困难。 为了解决这个问题,我们基于微信用户图的交互行为来生成用户表示。
The red packets interactions between users connect themas a large scale user-user graph, there is an edge between two users if they have red packets interactions. The redpackets interactions between users are complex with a largenumber of nodes and complex topological structure. Figure11 shows the part of the WeChat Red Packet Network. Inorder to capture the graph structure information for user modeling, we firstly employ Node2vec on User-User Graph to generate user embeddings. In this way, users with similar neighborhood structures will have similar embeddings. Sec-ondly, for each user node, we sample a portion of the nodesfrom its immediate neighbors and compute the average vector of the sampled neighbor nodes as part of the uservector representation, which further preserves the graph structure information for each user node from the graphand enhances the expression ability of user vector. Becauseseveral users may have red packets sent and received with thousands of other users, we need to make reasonableneighbor node sampling. For each user, we sort the neighbor nodes according to the times of red packets interactionsbetween them and select the top M neighborhood users where M is a hyperparameter. For users with fewer than M neighbors, we pad with the most important neighbor. Inthis way, the similarity of the generated user embedding canindicate the closeness of the users’ relationship on the social network.
用户之间的红包交互将它们连接成一个大规模的用户-用户图,如果两个用户之间存在红包交互,则在两个用户之间存在边。用户之间的红包交互非常复杂,具有大量的节点和复杂的拓扑结构。图11显示了微信红包网络的一部分。为了捕获用于用户建模的图结构信息,我们首先在User-User Graph上使用Node2vec生成用户嵌入。这样,具有相似邻域结构的用户将具有相似的嵌入。其次,对于每个用户节点,我们从其直接邻居中采样一部分节点,并计算采样后的邻居节点的平均矢量作为用户矢量表示的一部分,这进一步保留了来自图和每个用户节点的图结构信息。增强了用户载体的表达能力。因为几个用户可能与成千上万的其他用户发送和接收了红包,所以我们需要进行合理的邻居节点采样。对于每个用户,我们根据邻居之间的红包交互时间对其进行排序,并选择前M个邻居用户,其中M为超参数。对于邻居少于M个的用户,我们会与最重要的邻居进行交互。这样,生成的用户嵌入的相似性可以表明用户在社交网络上的亲密关系。
3.3 Cross & Attention
For a single red packet, we mainly focus on the sendingamount and date. From the data analysis described inSection 2, we find that the sending date and amount ofred packets are related to user real-life relationship types.It is necessary to combine the amount semantics and datesemantics to represent a red packet since two red packetswith different delivery dates may involve two distinct userrelationship types even if their amounts are exactly same. For instance, the implied meaning of red packets sent onValentine’s Day with 52.0 CNY is likely to be love betweencouples, while it is gratitude and love from children totheir mothers on Mother’s Day. To achieve the combinationbetween amounts and dates semantics, a simple approachto represent a red packet by directly concatenating thedate embedding with amount embedding. However, the naive concatenation limits the express ability of red packetsrepresentation. In order to better capture the semantics ofeach red packet, we introduce feature cross to the sequence model.
对于单个红包,我们主要关注发送金额和日期。从第2节中的数据分析中,我们发现红包的发送日期和金额与用户的现实生活关系类型有关,因为两个具有不同传递日期的红包需要将数量语义和日期语义结合起来来表示一个红包。可能涉及两种截然不同的用户关系类型,即使它们的金额完全相同。例如,在情人节那天以52.0元人民币发送的红包的隐含含义很可能是夫妻之间的爱,而在母亲节,这是孩子们对母亲的感谢和爱意。为了实现数量和日期语义之间的组合,一种简单的方法是通过将日期嵌入与金额嵌入直接串联来表示红包。但是,简单级联限制了红包表示的表达能力。为了更好地捕获每个红包的语义,我们将特征交叉引入到序列模型中。
Feature cross or interactions has been widely used inrecommendation systems [17], [18]. However, most of thefeature intersection methods in previous work are not pro-posed for the sequence model. In this paper, we implementa cross layer for explicit feature crossing between sending dates sequence and red packet amounts sequences togenerate red packets representation that efficiently combinethese two aspects of information. For each pair of users,we firstly lookup the amount embeddings and date embeddings according to their red packets interaction records.Both amount sequence embeddings and date sequence embeddings can be formatted as a matrix M∈RL×d where L is the length of the sequence anddis the dimension of eachamount or date embedding. The cross operation defined inthe Cross Layer is shown in Figure 12. Different from theCrossNet proposed in [18], we generate feature interactionsbetween two vectors of each time step for sequences. For a amount embedding vtamount∈R1×dand a date embedding vtdate∈R1×d in the time stept, we generate the representation of the corresponding red packet via following formulation:
特征交叉或交互已在推荐系统中得到广泛使用[17],[18]。但是,先前工作中的大多数特征交集方法并未针对序列模型提出。在本文中,我们实现了一个交叉层,用于在发送日期序列和红包金额序列之间进行显式特征交叉,以生成红包表示形式,从而有效地结合了这两个方面的信息。对于每对用户,我们首先根据他们的红包交互记录查找金额嵌入和日期嵌入。金额序列嵌入和日期序列嵌入都可以格式化为矩阵M∈RL×d,其中L是序列的长度并确定每个金额或日期嵌入的尺寸。交叉层中定义的交叉操作如图12所示。与[18]中提出的CrossNet不同,我们在序列的每个时间步长的两个向量之间生成特征交互。对于在时间步长中嵌入vtamount∈R1×d的日期和嵌入vtdate∈R1×d的日期,我们通过以下公式生成相应的红包的表示形式:
where || represents concatenation operation and Wamount,Wdate∈Rd are trainable weights. We theninput the generated red packets representation to the Long Short-Term Memory (LSTM) [19] network to capture the temporal dependencies of red packet interactions sequencefor each pair of users.
Not all red packets in the sequence are equally impor-tant, and we may want to pay special attention to some ofthem with special meaning. Furthermore, the importanceof each red packet for relationship identification task varywith the users pair involved. To address this issue, weexploit the users-ware attention mechanism to aggregate theoutput hidden states of LSTM. For each users pair, we firstly concatenate their embeddings and profile attributes as user representationu. Then we calculate attention weights foreach hidden state according to user representation and thehidden state vector. For a sequence withLhidden statevectors H= [h1,h2,h3,···,hL],hi∈Rd, the attention coefficients in CASM are obtained via the following formulations:
其中||表示级联运算,Wamount,Wdate∈Rd是可训练的权重。然后,我们将生成的红包表示形式输入到长期短期记忆(LSTM)[19]网络中,以捕获每个用户对红包交互序列的时间依赖性。
并非序列中的所有红包都具有同样重要的意义,我们可能要特别注意其中一些具有特殊含义的红包。此外,每个红包对于关系识别任务的重要性随所涉及的用户对而变化。为了解决这个问题,我们利用用户关注机制来聚合LSTM的输出隐藏状态。对于每个用户对,我们首先将其嵌入和配置文件属性连接为用户表示形式u。然后根据用户表示和隐藏状态向量计算每个隐藏状态的注意力权重。对于具有隐藏状态向量H = [h1,h2,h3,···,hL],hi∈Rd的序列,通过以下公式获得CASM中的关注系数:

where Wu,Wh∈Rd×d′ are trainable weights for linear feature transformation, and We∈R2d′×1 is the trainable attention weights to get a score for each hidden state vector.
Eventually, we integrate the hidden vectors in H into a single vector for the downstream classification task. The aggregated representation for His formulated as:
其中,Wu,Wh∈Rd×d’是线性特征变换的可训练权重,而We∈R2d’×1是为每个隐藏状态向量获得分数的可训练注意力权重。 最终,我们将H中的隐藏向量集成到单个向量中,以进行下游分类任务。 他的综合表述为:
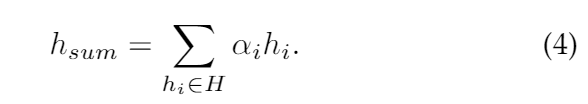
The attention mechanism with a single head is difficult tocapture different aspects of semantic information of user redpackets interactions. To this end, we exploit the multi-headattention mechanism to boost the express power. For every single head, the output of the attention layer is obtainedthrough Equation 3 and Equation 4. The trainable weightsof each head are different and thus we can capture thesemantics of the red packets sequence from different aspects.We concatenate the outputs of each head to obtain finalsequence representation.
单头注意力机制难以捕获用户红包交互语义信息的不同方面。 为此,我们利用多头注意机制来提高表达能力。 对于每个单个头部,通过等式3和等式4获得关注层的输出。每个头部的可训练权重是不同的,因此我们可以从不同方面捕获红包序列的这些语义。我们将每个头部的输出连接起来以获得最终序列表示。
Besides the generated sequence representation and userrepresentation, we utilize several features as side informa-tion such as the average red packets amount, the red packetinteraction times between two users and so on. Eventually,we concatenate sequence vector, users vector and side infor-mation and then input it to a three-layer neural network toget the predicted result.
除了生成的序列表示和用户表示,我们还利用了一些辅助功能,例如平均红包金额,两个用户之间的红包交互时间等。 最终,我们将序列向量,用户向量和辅助信息连接起来,然后将其输入到三层神经网络中以获得预测结果。
4 EXPERIMENTS
We perform comprehensive experiments on the real-world WeChat red packets dataset described in Section 2. We splitthe whole dataset into the training set, validation set, andtesting set. The training set contains 2,569,652 pairs of users,the validation set has 366,081 samples and there are 734,534pairs of users as testing samples in the testing set. The taskis to identify the real-life relationship between each pairof users in the dataset from the 8 relationship types wedescribed in Table 1.
我们对第2节所述的现实世界微信红包数据集进行了全面的实验。我们将整个数据集分为训练集,验证集和测试集。 训练集包含2,569,652对用户,验证集中有366,081个样本,测试集中有734,534对用户作为测试样本。 任务是从表1中描述的8种关系类型中识别数据集中每对用户之间的真实关系。
4.1 Experimental Setup
Metrics. Our task is a multi-classification problem. Hence,we exploit several metrics that are widely used for multi-classification problem. They are described as following:
•Macro-averaging AUC (Macro-AUC). Macro-AUCis a widely used extension of AUC (Area Underthe ROC curve) to multi-class classification, whichcalculates AUC for each label and then calculatestheir average value.
•Accuracy. Accuracy is a general metric for classifi-cation problem. It measures the proportion of thecorrectly predicted samples to all samples.
•Cross-entropyloss.Cross-entropyloss measures the distance between predicted score with the ground truth. It is formulated as−1N∑Ni=1∑mj=1yi,jlog(pi,j), whereyi,jis 1 ifthei−thsample belongs to classjor 0 if it belongsto other classes, andpi,jis the correspondingpredicted probability.Nis the number of samples,mis the number of classes.
指标。 我们的任务是一个多分类问题。 因此,我们利用了广泛用于多重分类问题的几种指标。 它们的描述如下:
•宏平均AUC(Macro-AUC)。 Macro-AUC是AUC(ROC曲线下的面积)到多类别分类的一种广泛使用的扩展,它可以计算每个标签的AUC,然后计算其平均值。
•准确性。 准确性是分类问题的通用指标。 它测量正确预测的样本在所有样本中的比例。
•交叉熵损失。交叉熵损失用于衡量预测值与真实值之间的距离。 它被公式化为-1N∑Ni = 1∑mj = 1yi,jlog(pi,j),如果第i个样本属于其他类,则yi为1,如果其他样本属于第0类,则pi为相应的预测概率。 样品,分类数不多。
Baselines. Since there exist no related studies of real-liferelationship prediction that can apply for our problem(which will be discussed in the related work in Section5), in order to illustrate the effectiveness of our proposeapproach, we compare our approach with widely used non-DL classifier and several relevant models for tasks involvedsequence input. All compared models are highly-tuned.For a fair comparison, the generated red packets sequencerepresentation is concatenated with users presentation andside information as CASM for all baseline models. All deeplearning models utilize the user-user graph to generatethe initial user embedding while only CASM utilizes theADG for amount and date embedding initial generation and baseline neural network methods learn amount-dateembedding from a randomly initialized embedding layer.
•Non-DL Approaches. We use some widely usedmachine learning classifier for comparison, includingSVM, Random Forest and Logistic Regression. Thesemodels take the average vector for sequence inputs.
•LSTM-Avg. We calculate the average of all hid-den state vectors as the sequence representation fordownstream prediction.
•LSTM-Max. It exploit max pooling operation to inte-grate hidden vectors of LSTM. Max pooling is widelyused for sequence representation.
•LSTM-MeanMax. It integrates the hidden vectors of LSTM via concatenating results of mean pooling andmax pooling [20].
•LSTM-AT. It uses self-attention mechanism that cal-culates attention coefficients based on each hiddenvector without user representation as extra informa-tion.
•LSTM-CNN. LSTM-CNN exploits CNN and max-pooling to integrate the hidden vectors of LSTM [21].•Attention-only. Similar to item sequence predictionfor recommendation in [22], the attention mecha-nism is adopted to generate sequence representation.While, in our approach we exploit user representa-tion as extra information to calculate the attentionweights.
•BiLSTM-AT. BiLSTM-AT is proposed for generatingsentence embedding [23]. It uses multi-head self-attention mechanism to calculate the weighted sumsof hidden states from a bidirectional LSTM.
•Cross-AT. It applies multi-head self-attention mech-anism over the cross layer to generate red packetsentence embedding.
For models that without Cross layer, each red packet is rep-resented with the concatenation of its amount embeddingand date embedding.
基线。由于目前尚无与现实生活相关的预测的相关研究可以解决我们的问题(将在第5节的相关工作中进行讨论),为了说明我们的提议方法的有效性,我们将我们的方法与广泛使用的Non-DL进行了比较分类器和一些与任务相关的模型涉及序列输入。为了比较起见,所有比较的模型都进行了高度调整。为公平起见,将所有基线模型的生成的红包序列表示与用户表示和边信息作为CASM连接在一起。所有深度学习模型都利用用户-用户图来生成初始用户嵌入,而只有CASM利用ADG进行金额和日期嵌入。初始生成和基线神经网络方法从随机初始化的嵌入层学习金额-日期嵌入。
•Non-DL Approaches。我们使用一些广泛使用的机器学习分类器进行比较,包括SVM,随机森林和Logistic回归。这些模型采用平均向量作为序列输入。
•LSTM-Avg。我们计算所有隐藏状态向量的平均值作为下游预测的序列表示。
•LSTM-Max。它利用最大池化操作来集成LSTM的隐藏向量。最大池被广泛用于序列表示。
•LSTM-MeanMax。它通过合并平均池和最大池的结果来整合LSTM的隐藏向量[20]。
•LSTM-AT。它使用自我注意机制,根据每个隐藏向量计算注意系数,而无需用户表示作为额外信息。
•LSTM-CNN。 LSTM-CNN利用CNN和max-pooling来集成LSTM的隐藏向量[21]。类似于[22]中用于建议的项目序列预测,采用注意机制来生成序列表示。同时,在我们的方法中,我们利用用户表示作为额外信息来计算注意权重。
•BiLSTM-AT。 BiLSTM-AT被提议用于生成句子嵌入[23]。它使用多头自我关注机制从双向LSTM计算隐藏状态的加权和。
•跨AT。它在跨层上应用多头自注意力机制来生成红色数据包嵌入。
对于没有交叉层的模型,每个红包都用其金额嵌入和日期嵌入的串联表示。
Reproducibility. For a fair comparison, embeddingdimensions for users, amount and date are set to be the samefor all models. The hidden unit of LSTM cell is set to be 64and we use tanh as the activation function. For all models,the generated sequence representation is concatenated with user presentation and side information and then inputtedto a 3-layer neural network whose hidden units are 64, 32and 16 in each layer. On Amount-Date Graph, we set thesearch bias parametersp= 1andq= 4for Node2vec.Moreover, we preserve 5 most similar other amount node asneighbors to update each amount representation with graphattention mechanism. For the user-user graph, the searchbias parameters are both set to be 1 for p and q, which isequivalent to DeepWalk [24]. All models are trained withADAM [25]. We use an early stopping strategy on cross-entropy loss of validation set and fix the batch size to be1024 for all cases. The learning rate, dropout probability, andother hyper-parameters are tuned for each model accordingto the performance on the validation set with a grid searchstrategy.
重现性。为了公平起见,将用户的嵌入尺寸,金额和日期设置为所有模型相同。 LSTM单元格的隐藏单位设置为64,我们使用tanh作为激活函数。对于所有模型,将生成的序列表示与用户表示和辅助信息连接起来,然后输入到3层神经网络中,该网络的每层隐藏单元分别为64、32和16。在金额日期图上,我们为Node2vec设置搜索偏差参数p = 1和q = 4.此外,我们保留了5个最相似的其他金额节点邻居,以使用graph attention机制更新每个金额表示形式。对于用户-用户图,p和q的search bias参数都设置为1,这与DeepWalk [24]等效。所有模型都使用ADAM进行训练[25]。我们对验证集的交叉熵损失使用了早期停止策略,并将所有情况下的批次大小固定为1024。根据使用网格搜索策略的验证集上的性能,为每个模型调整学习率,辍学概率和其他超参数。
4.2 Results
Overall comparison.The performances of different modelson the user relationship identification problem are shownin Table 4. In this experiment, the number of heads is 4 for all models with multi-head attention mechanism. For each user, we reserve up to 20 neighbor nodes to generate users neighboring information vector for users modeling.The maximum length of the red packet sequence for eachuser pair is limited to 50. Table 4 demonstrates that our CASM out performs other widely used sequence representation learning models. More specifically, the relative improvement over the best baseline is 4.7%, 11.98% and 1.5%in terms of Macro-AUC, Cross Entropy Loss and Accuracy,respectively. Considering the huge number of WeChat users,the improvement brought by the approach that we pro-pose in this paper is of practical significance. It suggests that our proposed approach is effective to learn each red packet’s representation and the red packet sequence repre-sentation. Notice that LSTM-AT has a better performance than Attention-only, which indicates that LSTM may bebeneficial since it can capture the temporal dependencies of red packets.
总体比较。表4中显示了不同模型在用户关系识别问题上的性能。在本实验中,所有具有多头注意机制的模型的头数均为4。对于每个用户,我们最多保留20个邻居节点以生成用户邻居信息向量以进行用户建模。每个用户对的红包序列的最大长度限制为50。表4证明了我们的CASM可以执行其他广泛使用的序列表示学习模型。更具体地,就Micro-AUC,交叉熵损失和准确性而言,在最佳基准上的相对改进分别为4.7%,11.98%和1.5%。考虑到微信用户数量巨大,本文提出的方法所带来的改进具有现实意义。这表明我们提出的方法可以有效地学习每个红包的表示形式和红包序列的表示形式。请注意,LSTM-AT具有比“仅关注”更好的性能,这表明LSTM可能是有益的,因为它可以捕获红包的时间依赖性。
Ablation Analysis. In order to illustrate the influenceof different components of CASM, we perform the ablationstudy. We mainly focus on the following variant of CASM:
CASM\ADG: Remove the Amount-Date Graph foramount and date embeddings generation. In this variant,CASM learns these embeddings via the random initializedembedding layer.
CASM\Cross: Remove the cross layer. Each red packetis represented by concatenating sending amount and datedirectly.CASM\UAT: Replace the user-aware attention mecha-nism introduced in Section 3.3 with the plain self-attentionmechanism for hidden vectors integration.
CASM\Profile: Eliminate user demographic attributesfrom users vectors.
CASM\Side: Eliminate side information features.The results are reported in Figure 5. It indicates thatADG and user-aware attention mechanism are important toCASM. On one hand, CASM learns better amount and daterepresentation by applying the graph representation learn-ing methods. It also suggests that the ADG we constructedcan effectively reflect the semantic correlation between datesand amounts. On the other hand, user-aware attentionmechanism help CASM to generate more expressive redpackets sequence representation since it uses user informa-tion to calculate attention weights. In this way, the impor-tance of each kind of red packet would dynamically changeaccording to different user pairs. Users profile features andside information provide less performance improvement forCASM because the number of these features in the datasetis quite small. Therefore, it’s of great significance to makefull use of red packets semantic information for real-liferelationship identification.
消融分析。为了说明CASM不同组件的影响,我们进行了消融研究。我们主要关注CASM的以下变体:
CASM \ ADG:删除金额-日期图,以生成金额和日期嵌入。在此变体中,CASM通过随机的initializedembedding层学习这些嵌入。
CASM \ Cross:删除交叉层。每个红色数据包都由发送量和日期直接串联表示。
CASM \ UAT:用普通的自我注意机制代替第3.3节中介绍的用户感知的注意机制,以实现隐藏矢量的集成。
CASM \ Profile:从用户向量中消除用户人口统计属性。
CASM\Side:消除了边信息功能。
结果报告在图5中。这表明ADG和用户感知注意机制对CASM很重要。一方面,CASM通过应用图形表示学习方法来学习更好的数量和日期表示。这也表明我们构建的ADG可以有效反映日期和金额之间的语义相关性。另一方面,用户感知的注意力机制可帮助CASM生成更具表现力的红包序列表示形式,因为它使用用户信息来计算注意力权重。这样,每种红包的重要性将根据不同的用户对动态变化。用户资料特征和辅助信息对CASM的性能改进较少,因为数据集中这些特征的数量非常少。因此,充分利用红包语义信息对现实生活中的关系进行识别具有重要意义。
In the relationship identification task based on red packetinteractions, we use several different features, includinguser embedding, demographic attributes, red packet fea-tures and so on. To better understand the contribution ofeach type of feature to the prediction task, we conduct an ablation analysis for features. In this experiment, we uselogistic regression model and remove different features toobserve the decline of prediction performance.
在基于红包交互的关系识别任务中,我们使用了几种不同的功能,包括用户嵌入,人口统计属性,红包特性等。 为了更好地理解每种类型的特征对预测任务的贡献,我们对特征进行了消融分析。 在本实验中,我们使用逻辑回归模型并删除了不同的功能以观察预测性能的下降。
The results shown in Table 5 indicate that the featuresused have a different impact on the relationship identifi-cation problem. It suggests that the semantic informationof the red packet amount has the greatest influence. Mean-while, the sending date of red packets also contains valuablesemantic information related to the identification task, sothe prediction performance degradation is also obvious afterremoving date embedding. The user embedding generatedby node2vec contain the information about the topologicalstructure of the user interaction graph and can reflect usersocial circle.
表5所示的结果表明,所使用的特性对关系识别问题有不同的影响。可见,红包金额的语义信息影响最大。同时,红包的发送日期也包含了与识别任务相关的有价值的语义信息,因此去除日期嵌入后,预测性能的退化也很明显。node2vec生成的用户嵌入包含了用户交互图的拓扑结构信息,能够反映用户社交圈。
Visualization. As an interpretation of the learned redpacket representations, we provide a heatmap for some ofthe samples in the dataset. We randomly select 2 samplesfrom the samples labeled as lovers and parent-child re-lationship respectively. Fig. 14 suggests that the attentionmechanism used in our model can capture the key factorsin the red packets sequence that indicate the relationshiptypes. For example, in the first red packet sequence of Fig.14(a), the red packet sent on Chinese Valentine’s Day (QixiFestival) with the amount of ”52.0” and the red packet senton Valentine’s Day with the amount of ”13.14” have largerattention weights. The meanings of these two amounts are ”Ilove you” and ”For the whole life”. Intuitively, these two red packet interactions are more likely to occur between lovers,so it is reasonable for the model to pay more attention to them.
可视化。 作为对学习到的红色数据包表示的一种解释,我们为数据集中的某些样本提供了一个热图。 我们从分别标记为恋人和亲子关系的样本中随机选择2个样本。 图14表明,我们模型中使用的注意力机制可以捕获红包序列中指示关系类型的关键因素。 例如,在图14(a)的第一个红色数据包序列中,在情人节(QixiFestival)发送的红色数据包的数量为“ 52.0”,而在情人节那天发送的红色数据包的数量为“ 13.14”的红色数据包具有 更大的注意权重。 这两个词的含义是“爱你”和“一生”。 直观地讲,这两个红包交互更可能在恋人之间发生,因此模型对它们进行更多关注是合理的。
5 RELATED WORK
5.1 Relationship Identification And Application
Extensive literates have researched user relationship identi-fication and related applications [26], [27], [28], [29]. Deng et al. [7] predicted users relationship types according to thetopic of their interactive tweets in Sina Weibo. They firstlyuse a generative model to discover relationship-related com-munities with users’ interactive content and then exploitexternal relationship-word distributions to infer relationshiptypes including colleague, school mate, family member andinterest-oriented friend. In [30], the authors used the users’profiles and shared photo to predict users relationships.Diehl et al. [31] proposed a supervised ranking approach formanager-subordinate relationship identification task using Enron email corpus with traffic and content-based features.
大量学者已经研究了用户关系识别和相关应用[26],[27],[28],[29]。 丹吉尔 [7]根据他们在新浪微博上的互动推文的主题来预测用户的关系类型。 他们首先使用生成模型来发现与用户互动内容相关的社区,然后利用外部关系词分布来推断包括同事,同学,家庭成员和有兴趣的朋友的关系类型。 在[30]中,作者使用用户的个人资料和共享的照片预测用户之间的关系。 [31]提出了一种使用基于流量和基于内容的特征的安然电子邮件语料库的监督排序方法,以建立从属关系和从属关系。
Cen et al. [32] used fine-grained real-life relationshiptypes between users and the discovered network correla-tion patterns to predict user trust relationship. They applythe inferred trust relationship information into Alibaba e-commerce platform and achieve better performance. Zhonget al. [3] constructed multi-view attributed heterogeneousinformation network which adopts user relationships (e.gfamily), trading and fund transfer behaviors and user-device login operations. They proposed MAHINDER modelto extract interactive features of users and detect financialdefaulter on Alibaba platform. Suzumura et al. [33] pro-posed a federated graph learning approach that utilizessocial relationships between customers to detect global fi-nancial crime activities across different financial institutions.Gong et al [34] exploited social relationships to motivateusers to participate in pseudonym change, which can helpprotect their location privacy. Leveraging the user relation-ship information in online social networks is beneficial tomitigate Sybil attack and develop access control models [35].Therefore, the proper use of social relationship informationcan help protect user privacy and security.
Cen等。 [32]使用用户和发现的网络关联模式之间的细粒度的真实生活关系类型来预测用户信任关系。他们将推断的信任关系信息应用到阿里巴巴电子商务平台中,并获得了更好的性能。 Zhonget al。 [3]构建了多视图属性异构信息网络,该网络采用了用户关系(例如家庭),交易和资金转移行为以及用户设备登录操作。他们提出了MAHINDER模型,以提取用户的交互功能并在阿里巴巴平台上检测金融违约行为。 Suzumura等。 [33]提出了一种联合图学习方法,该方法利用客户之间的社会关系来检测不同金融机构之间的全球金融犯罪活动。Gong等人[34]利用社会关系来激励用户参与化名更改,这可以帮助保护他们的假名。位置隐私。利用在线社交网络中的用户关系信息有利于缓解Sybil攻击并开发访问控制模型[35]。因此,正确使用社交关系信息可以帮助保护用户的隐私和安全。
The use of user relationship information in commercialapplications such as recommendation systems may involveethical issues and requires careful consideration with user consent.
在诸如推荐系统之类的商业应用中使用用户关系信息可能涉及道德问题,并需要在用户同意的情况下仔细考虑。
5.2 WeChat Social Network Analysis
As the largest acquaintance social networking platform in China, several previous literatures have paid attention tothe analysis of WeChat social network or made effort tosolve some machine learning task on WeChat datasets. Qiuet al. [36] analyzed the evolution patterns of WeChat socialmessaging groups and developed a model to predict groupmembership cascade. Liu et al. [12] analyzed the cascadingbehavior patterns in WeChat moments. Since WeChat RedPackets application is getting more and more popular inChina, several recent work analyzed the user red packetgiving behavior on WeChat. In [10], Wu et al. performedan archive analysis of red packets events in small numberof WeChat groups, a survey and an interview with some WeChat users and participants. In this way, they drawthe conclusion that red packets gifting behavior can helpmanage group dynamic. However, this work involves a tinynumber of users and data. In [11], the authors analyzed alarge WeChat red packets dataset to explore users onlinemoney gifting behavior. They used statistical approachesto demonstrate the association of users red packets givingbehavior with demographic characteristics and geographicbackground. Moreover, they used propensity score to ex-amine the causal effects of WeChat red packets on group dynamic.
作为中国最大的熟人社交网络平台,以前的一些文献已经关注微信社交网络的分析,或者致力于解决微信数据集上的一些机器学习任务。 Qiuet分析了微信社交消息群的演化模式,并建立了一个预测群体成员级联的模型。Liu et al.分析了微信中的级联行为模式。由于微信红包应用程序在中国越来越受欢迎,因此最近的一些工作分析了微信上的用户红色数据包赠送行为。在[10]中,Wu et al.对少数微信群中的红包事件进行了存档分析,一项调查以及对一些微信用户和参与者的采访。通过这种方式,他们得出结论:红包的赠礼行为可以帮助管理团队动态。但是,这项工作涉及极少数的用户和数据。在[11]中,作者分析了一个较大的微信红包数据集,以探索用户的在线货币赠礼行为。他们使用统计方法来证明用户红包行为与人口统计特征和地理背景相关联。此外,他们使用倾向评分来检验微信红包对群体动态的因果影响。
5.3 Attention Mechanism
Attention Mechanism has gradually become ade factostan-dard for quite a lot of neural language processing tasks suchas neural machine translation (NMT) [37], [38], text classifi-cation [39] and so on. Besides NLP applications, many othermachine learning tasks benefit from attention mechanismespecially the problems that involves sequence input. Forinstance, in the recommendation system, a common practiceis to construct a sequence of user historical operation recordsand input it to a sequence model, and the model can bettercapture the user’s interest via exploiting attention mecha-nism [40]. Usually, attention mechanism enable models toget better sequence representation since it help model tofocus on the most relevant part. For a typical sequencemodel with attention mechanism, it calculates a attentionweightαifor each hidden state vectorhi, and get thesequence representation as∑iαi·hi. The attention weightsare trainable and can be calculated in different ways. In [38],the authors proposed multi-head attnetion mechanism tocapture different aspects of sequence representation. Multi-head attention has been widely used in different researchareas. In [16], the authors introduces multi-head attentioninto graph neural networks (GATs) to aggregate the neigh-boring information for each node and applied it to the nodeclassification problem.
对于许多神经语言处理任务,例如神经机器翻译(NMT)[37],[38],文本分类[39]等,注意力机制已经逐渐成为事实。除了NLP应用程序外,许多其他机器学习任务还受益于注意力机制,尤其是涉及序列输入的问题。例如,在推荐系统中,一种常见的做法是构造一个用户历史操作记录序列,并将其输入到序列模型中,该模型可以通过利用注意力机制来更好地捕获用户的兴趣[40]。通常,注意力机制可以使模型获得更好的序列表示,因为它有助于模型专注于最相关的部分。对于具有注意机制的典型序列模型,它为每个隐藏状态向量hi计算一个注意权重αi,并将这些次数表示为∑ iαi·hi。注意权重是可训练的,可以用不同的方式计算。在[38]中,作者提出了多头攻击机制来捕获序列表示的不同方面。多头注意力已广泛应用于不同的研究领域。在[16]中,作者将多头注意力引入到图神经网络(GAT)中,以汇总每个节点的邻近信息,并将其应用于节点分类问题。
5.4 Graph Representation Learning Applications
Graph representation learning methods are proposed togenerate dense low-dimensional embeddings for nodes ongraphs [14], [24], [41]. Since graph embedding approachescan generate similar dense vector representations for relatednodes, many applications can benefit from them. Wang et al.[42] exploited DeepWalk [24] to generate item embeddingsand concatenated the generated item embedding with sideinformation to obtain item representation for recommen-dation in Taobao. In [43], Chen et al. used Node2vec [14]to capture the complex latent relevance among users (oritems) for a local recommender system. In [44], the authorsapplied node2vec to address churn prediction problem onuser calling graph.
提出了图表示学习方法来生成图上节点的密集低维嵌入[14],[24],[41]。 由于图嵌入方法可以为相关节点生成相似的密集矢量表示,因此许多应用程序都可以从中受益。 Wang et al。[42] 利用DeepWalk [24]生成项嵌入,并将生成的项嵌入与边信息连接起来,以获得项表示以在淘宝网中进行推荐。 在[43]中,Chen等。 使用Node2vec [14]来捕获本地推荐系统用户(方法)之间的复杂潜在相关性。 在[44]中,作者应用node2vec解决了用户调用图上的用户流失预测问题。
6 CONCLUSION
In this paper, we study the relationship identification prob-lem based on users money gifting behavior on WeChat.Through extensive data analysis, we illustrate the influenceof the real-life relationship types between users on their red packets gifting behavior. In order to capture the se-mantics of red packets, we construct Amount-Date Graphto represent the correlation between red packet sendingdates and amounts and employ graph embedding methodto generate embeddings for amounts and dates. Besides,we propose a novel sequence model, Cross & AttentionSequence Model (CASM), which effectively combines userrepresentation and red packets representation for users rela-tionship identification. The comprehensive experiments weconducted on the real world WeChat dataset demonstratethat our approach is effective.
本文基于微信上基于用户金钱赠与行为的关系识别问题进行了研究。通过广泛的数据分析,阐明了用户之间的真实生活关系类型对他们的红包赠与行为的影响。 为了捕获红色数据包的语义,我们构造了Amount-Date Graph来表示红色数据包发送日期和数量之间的相关性,并使用图嵌入方法生成数量和日期的嵌入。 此外,我们提出了一种新颖的序列模型,即交叉注意序列模型(Cross&AttentionSequence Model,CASM),该模型有效地结合了用户表示和红包表示,以进行用户关系识别。 我们在现实世界的微信数据集上进行的综合实验表明,我们的方法是有效的。
论文研究对象
核心创新
比较对象
拓展思路

若有收获,就点个赞吧
0 人点赞
