一. 项目介绍
将Hadoop打包到Docker镜像中,就可以快速地在单个机器上搭建Hadoop集群,这样可以方便新手测试和学习。
如下图所示,Hadoop的master和slave分别运行在不同的Docker容器中,其中hadoop-master容器中运行NameNode和ResourceManager,hadoop-slave容器中运行DataNode和NodeManager。NameNode和DataNode是Hadoop分布式文件系统HDFS的组件,负责储存输入以及输出数据,而ResourceManager和NodeManager是Hadoop集群资源管理系统YARN的组件,负责CPU和内存资源的调度。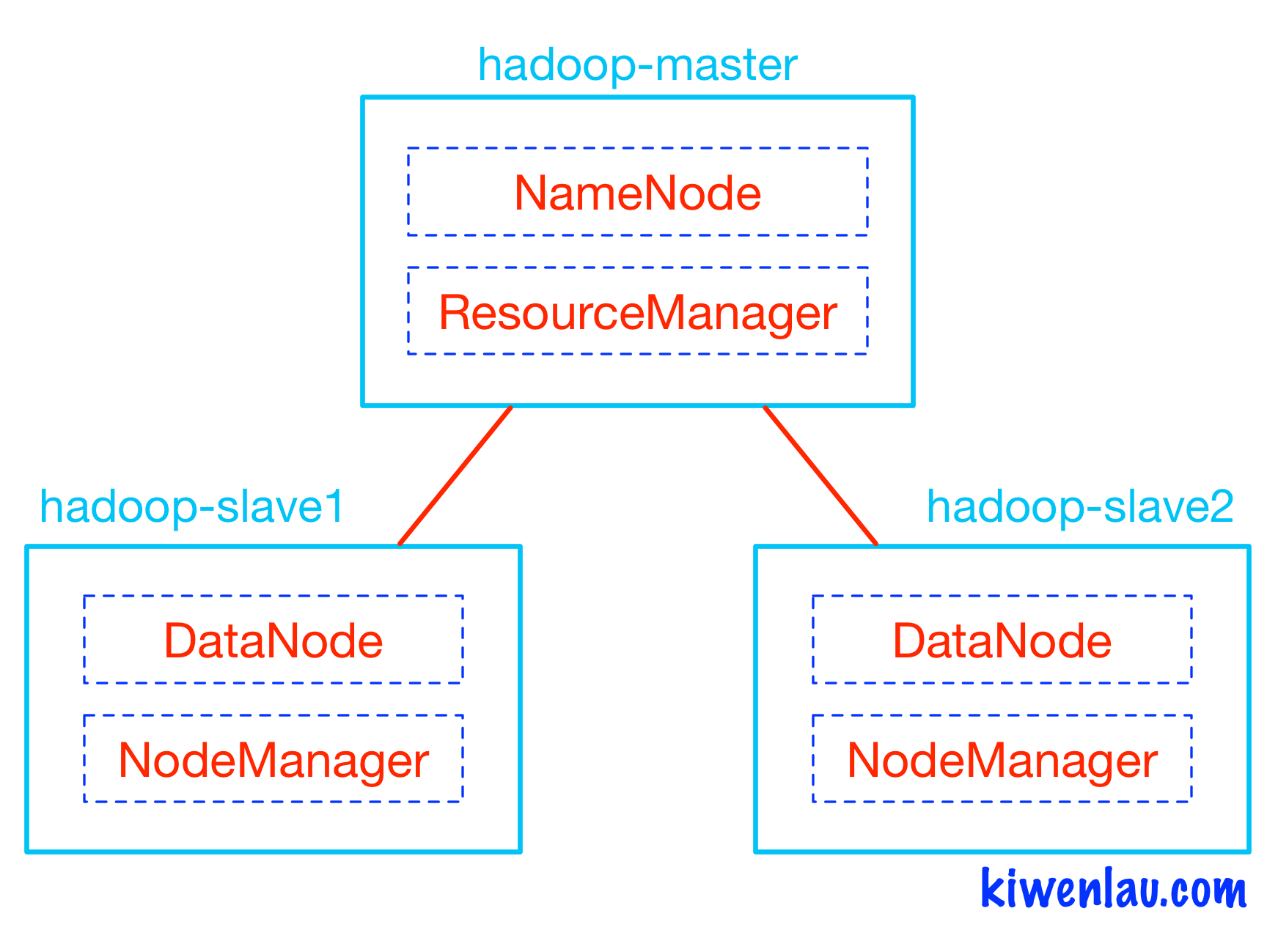
之前的版本使用serf/dnsmasq为Hadoop集群提供DNS服务,由于Docker网络功能更新,现在并不需要了。更新的版本中,使用以下命令为Hadoop集群创建单独的网络:
| sudo docker network create —driver=bridge hadoop |
|---|
然后在运行Hadoop容器时,使用”–net=hadoop”选项,这时所有容器将运行在hadoop网络中,它们可以通过容器名称进行通信。
项目更新要点:
- 去除serf/dnsmasq
- 合并Master和Slave镜像
- 使用kiwenlau/compile-hadoop项目编译的Hadoo进行安装
- 优化Hadoop配置
二. 3节点Hadoop集群搭建步骤
1. 下载Docker镜像
| sudo docker pull kiwenlau/hadoop:1.0 | | —- |
2. 下载GitHub仓库
| git clone https://[github.com/kiwenlau/hadoop-cluster-docker](http://github.com/kiwenlau/hadoop-cluster-docker) |
|---|
3. 创建Hadoop网络
| sudo docker network create —driver=bridge hadoop |
|---|
4. 运行Docker容器
| cd hadoop-cluster-docker ./start-container.sh |
|---|
运行结果
| start hadoop-master container… start hadoop-slave1 container… start hadoop-slave2 container… root@hadoop-master:~# |
|---|
6. 运行wordcount
| ./run-wordcount.sh |
|---|
运行结果
| input file1.txt: Hello Hadoop input file2.txt: Hello Docker wordcount output: Docker 1 Hadoop 1 Hello 2 |
|---|
Hadoop网页管理地址:
- NameNode: http://192.168.59.1:50070/
- ResourceManager: http://192.168.59.1:8088/
三. N节点Hadoop集群搭建步骤
1. 准备

若有收获,就点个赞吧
0 人点赞
