- 持久化
- 快照RDB
全量备份,二进制,存储紧凑
使用操作系统的COW机制实现快照持久化。
使用fork创建子进程,
子进程做数据持久化,它不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到磁盘中。但是父进程不一样,它必须持续服务客户端请求,然后对内存 数据结构进行不间断的修改。 这个时候就会使用操作系统的 COW 机制来进行数据段页面的分离。数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复 制一份分离出来,然后对这个复制的页面进行修改。这时子进程相应的页面是没有变化的, 还是进程产生时那一瞬间的数据。
- AOF日志
内存数据修改的指令记录文本,重启时会重放,需要定期AOF重写来瘦身。
Redis 会在收到客户端修改指令后,先进行参数校验,如果没问题,就立即将该指令文本存储到 AOF 日志中,也就是先存到磁盘,然后再执行指令。
bgrewriteaof 指令用于对 AOF 日志进行瘦身的原理:开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。 序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
fsync
写AOF文件时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回到磁盘的。
每秒执行一次fsync操作。周期可配置
其他策略:永不fsync,每条指令都fsync
Redis主节点不进行持久化,从节点来做持久化。
- 混合持久化
前一部分用rdb恢复,后小部分用aof持久化
用rdb会丢失大量数据,为什么?
aof比较慢。
redis 4.0新增混合持久化。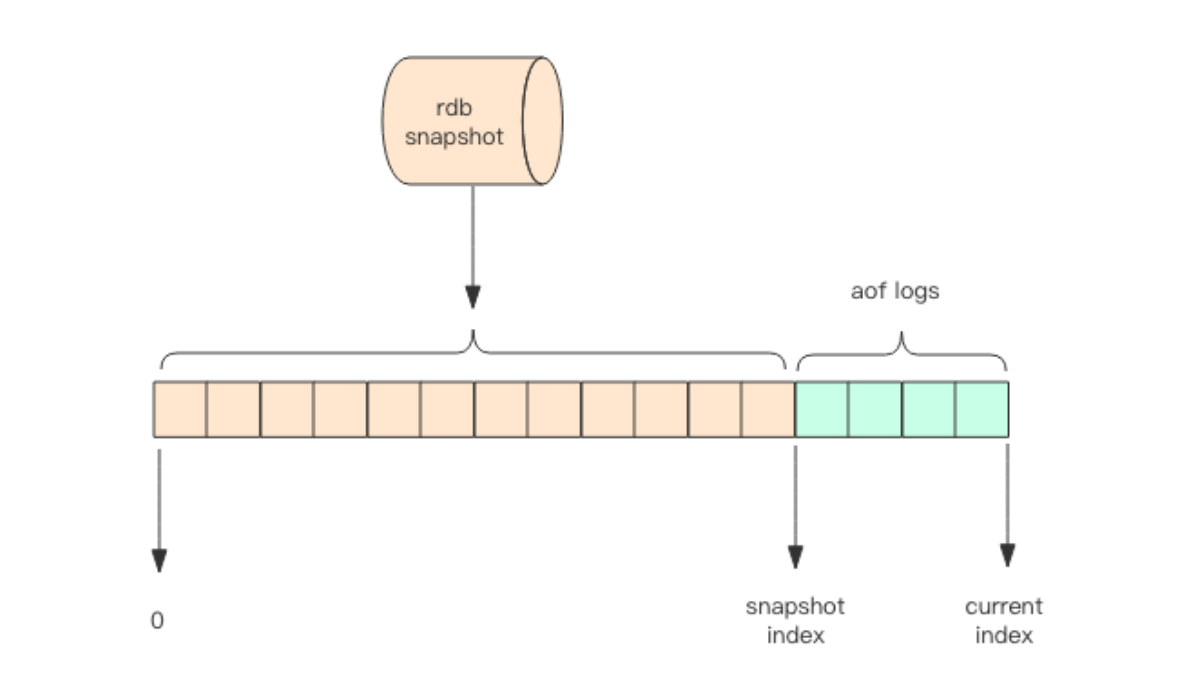
重启以后先加载rdb内容,然后重放增量AOF日志。
- Redis管道 Pipeline
客户端通过对管道中的指令列表改变读写顺序就可以大幅节省 IO 时间。管道中指令越多,效果越好。
本质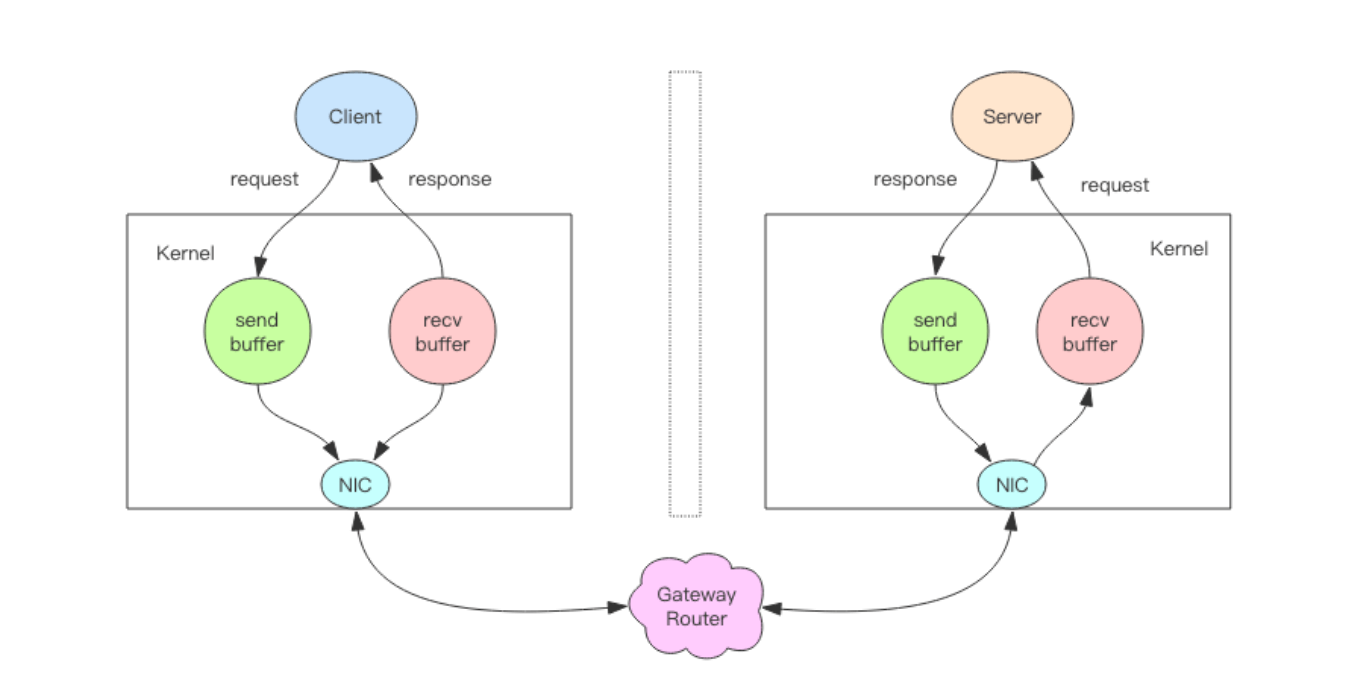
write不需要等待对方收到消息才返回,只要发送缓冲没有满,就会立即返回,否则,需要阻塞等待,这才是写操作IO耗时。
read也同理,只有缓冲是空的,才是读IO操作的真正耗时。
而对于管道来说,连续的 write 操作根本就没有耗时,之后第一个 read 操作会等待一个 网络的来回开销,然后所有的响应消息就都已经回送到内核的读缓冲了,后续的 read 操作 直接就可以从缓冲拿到结果,瞬间就返回了。
- 事务
multi 指示事务的开始, exec 指示事务的执行,discard 指示事务的丢弃。
不具有原子性,当某个中间指令失败了,后面的指令还会继续执行。
discard 指令,用于丢弃事务缓存队列中的所有指令。
事务常常结合pipeline一起使用,可以将多次IO操作压缩为单次IO操作。
watch,乐观锁,要在multi之前就开始watch,当发现关键变量自watch后被修改了,exec会返回null表示执行失败。
- PubSub
subcribe 订阅
publish 发布
模式订阅,如*匹配任何
消息结构:
{‘pattern’: None, ‘type’: ‘subscribe’, ‘channel’: ‘codehole’, ‘data’: 1L}
data 是消息的内容,一个字符串。
channel 表示当前订阅的主题名称。
type 表示消息的类型,如果是一个普通的消息,那么类型就是 message,如果是控制消息,比如订阅指令的反馈,它的类型就是 subscribe,如果是模式订阅的反馈,它的类型就 是 psubscribe,还有取消订阅指令的反馈 unsubscribe 和 punsubscribe。
pattern 表示当前消息是使用哪种模式订阅到的,如果是通过 subscribe 指令订阅的, 那么这个字段就是空。
缺点:
消息不是持久化的,重启会消失。另外如果消费者不在,消息就直接扔了。
几乎找不到合适的应用场景。
redis 5.0出了Stream数据结构,是持久化的,PubSub可以消失了。
- 小对象压缩
32bit和64bit:
如果内存不超过4G,使用32bit可以节约大量内存。
如果不足可以通过增加实例来解决。
ziplist
每个元素紧挨着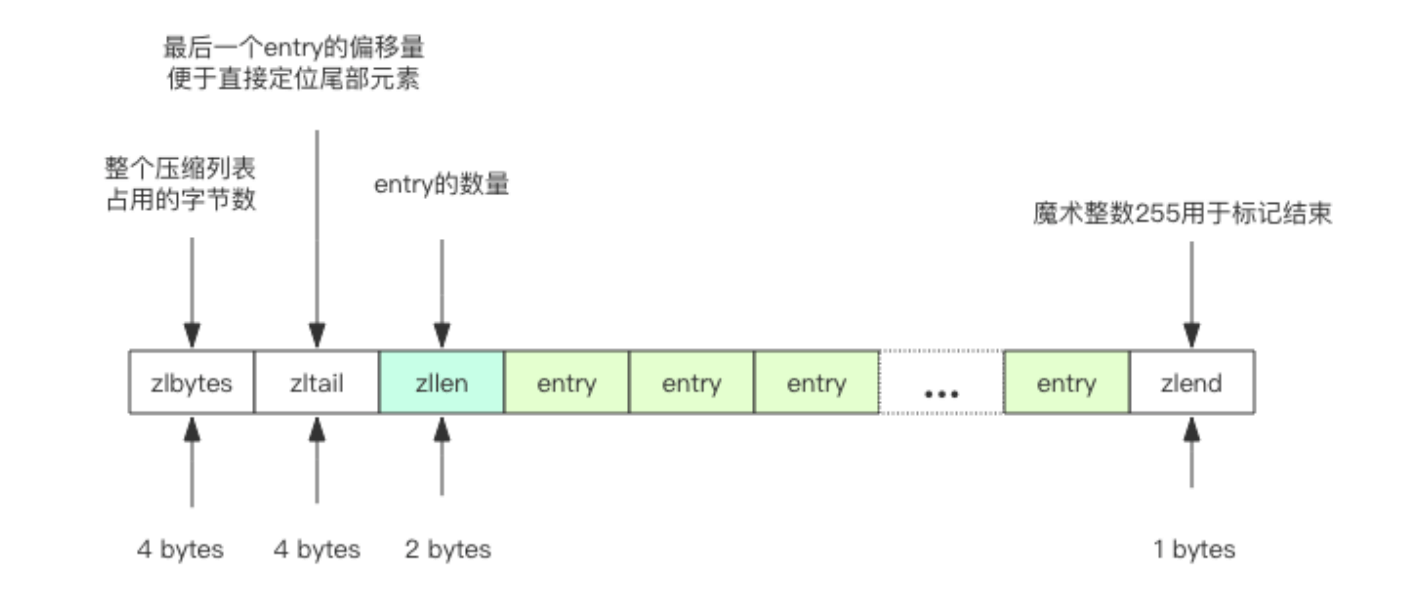
如果它存储的是 hash 结构,那么 key 和 value 会作为两个 entry 相邻存在一起。
如果它存储的是 zset,那么 value 和 score 会作为两个 entry 相邻存在一起。
object encoding可以用来查看某个key是以什么数据结构存储的
intset用来存整数且元素个数较少的set集合。动态升级,从16位到32位到64位。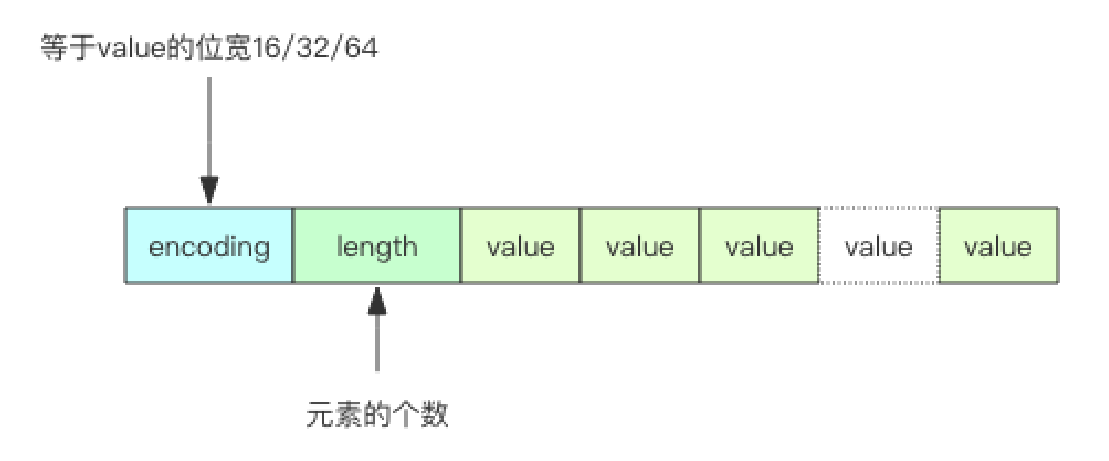
如果 set 里存储的是字符串,那么 sadd 立即升级为 hashtable 结构。
存储界限
当集合对象的元素不断增加,或者某个 value 值过大,这种小对象存储也会被升级为标准结构。
内存回收机制
操作系统回收内存是以页为单位,如果这个页上只要有一个 key 还在使用,那么它就不能被回收。
flushdb会删除所有key,所以内存马上就回收了。
内存分配算法
用jemalloc管理内存,也可以切换到tcmalloc。
- 主从同步
- CAP
- C 一致性
- A 可用性
- P 分区容忍性
网络分区发生时,一致性和可用性两难全。
跳过了集群和拓展部分
- 字符串源码分析
Simple Dynamic String
struct SDS
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位,不理睬它
byte[] content; // 数组内容
}
字符串可以修改,append操作类似于ArrayList的add,如果没有足够空间,就重新分配。
用泛型T的原因是有的字符串很短,可以用short或者byte表示。是为了内存优化
字符串长度不得超过512MB
创建时len和capacity一样长,绝大多数场景不会用append操作。
embstr vs raw
字符串有两种存储方式,特别短时用emb形式,长度超过44时,用raw形式存储。
区别?分界线为什么是44?
Redis对象都有一个对象头结构体,16字节
struct RedisObject {
int4 type; // 4bits 表示类型
int4 encoding; // 4bits 同一个类型的type也有不同的存储形式
int24 lru; // 24bits 记录LRU信息
int32 refcount; // 4bytes 引用计数,0时对象销毁
void *ptr; // 8bytes,64-bit system 对象内容具体存储位置
} robj;
SDS结构体
显然sds对象头的大小是16+3
embstr是一次性分配内存,RedisObject 对象头和 SDS 对 象连续存在一起
raw需要两次
内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64。
大字符串,总体超出64字节。
当分配64字节,有19用来存头,还有一个位置要存0用来标识字符串结束, 所以有44个位置可以存字符串。
扩容策略
字符串小于1M之前,加倍扩容。
大于1M之后,每次增加1M。
什么场景会用到字符串的append方法?
字典源码
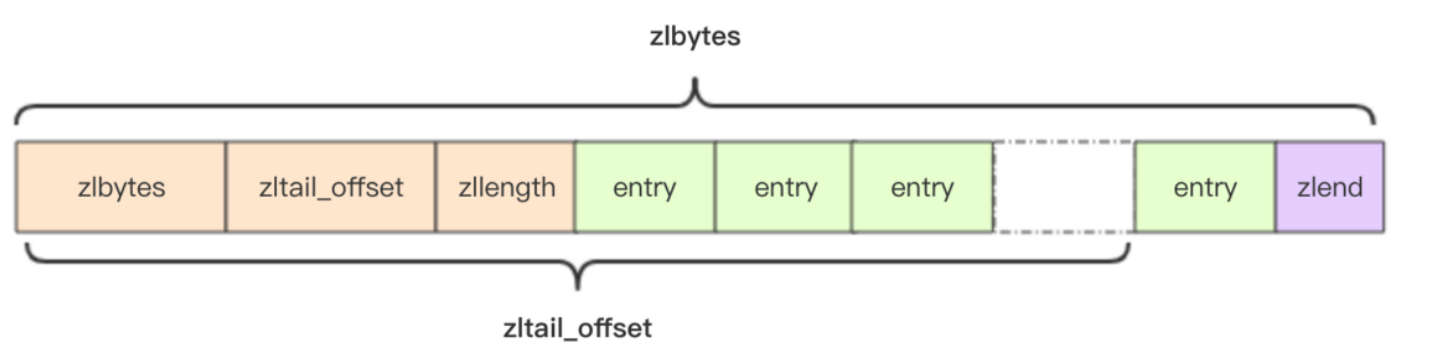
压缩列表ziplist
struct ziplist
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
struct entry {
int prevlen; // 前一个 entry 的字节长度
int encoding; // 元素类型编码
optional byte[] content; // 元素内容
}
encoding通过前缀位来区分内容。
content是可选的。
ziplist是紧凑存储,没有冗余空间,插入新元素需要realloc扩展内存。不适合存储大型字符串,也不适合存太多元素。
级联更新
前面提到每个 entry 都会有一个 prevlen 字段存储前一个 entry 的长度。如果内容小于254 字节,prevlen 用 1 字节存储,否则就是 5 字节。这意味着如果某个 entry 经过了修改 操作从 253 字节变成了 254 字节,那么它的下一个 entry 的 prevlen 字段就要更新,从 1 个字节扩展到 5 个字节;如果这个 entry 的长度本来也是 253 字节,那么后面 entry 的 prevlen 字段还得继续更新。 如果 ziplist 里面每个 entry 恰好都存储了 253 字节的内容,那么第一个 entry 内容的 修改就会导致后续所有 entry 的级联更新,这就是一个比较耗费计算资源的操作。
ziplist
- zset和hash容器元素较少时
- 连续内存空间,元素紧挨着,没有冗余空间
- 为了支持双向遍历,有一个ztail_offset
IntSet 小整数集合
struct intset
int32 encoding; // 决定整数位宽是 16 位、32 位还是 64 位
int32 length; // 元素个数
int
}
- 快速列表 quicklist
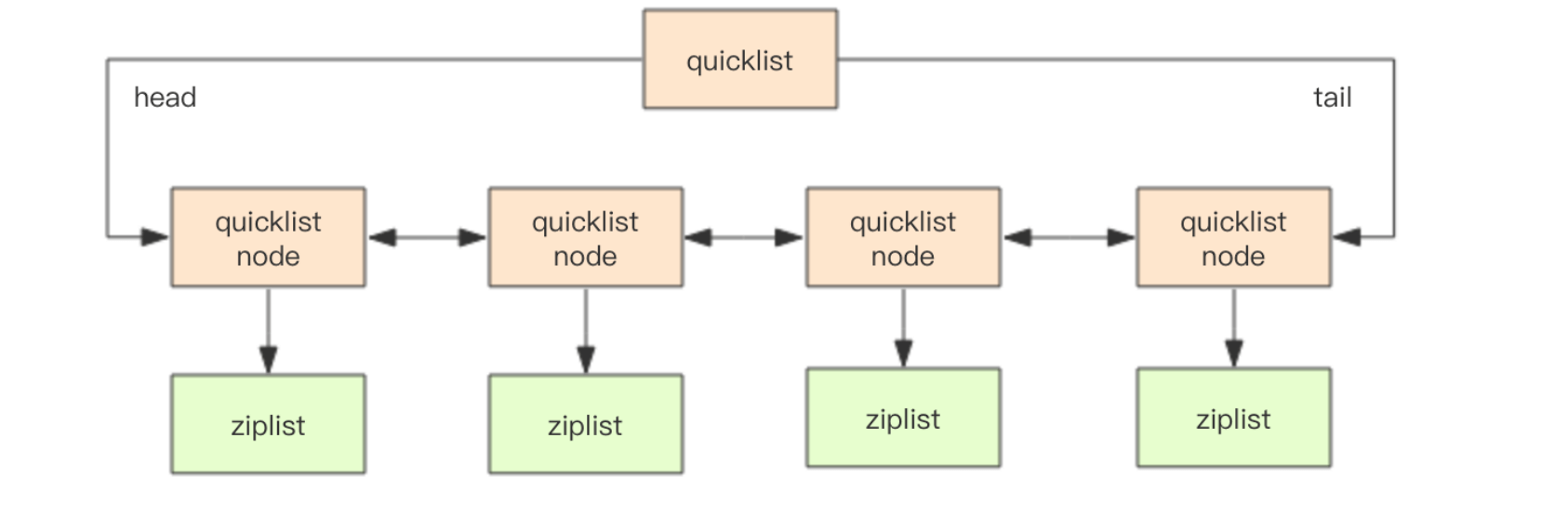
默认单个 ziplist 长度为 8k 字节,超出了这个字节数,就会新起一个ziplist。
默认压缩深度是0,也就是不压缩。
压缩深度为1表示首尾不压缩,这样可以支持快速的push/pop操作。
- 跳跃列表
结构
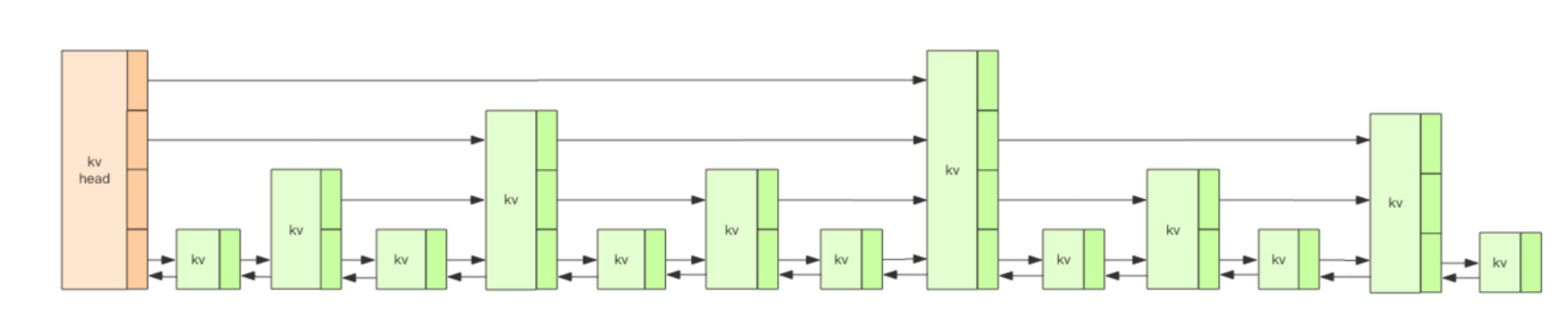
struct zsl {
zslnode header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map<string, zslnode> ht; // hash结构的所有键值对
}
struct zslnode {
string value;
double score;
zslnode[] forwards; // 多层连接指针
zslnode backward; // 回溯指针
}
晋升概率ZSKIPLIST_P = 25%
插入过程:首先在搜索合适插入点的过程中将「搜索路径」摸出来了,然后就可以开始创建新节点了,创建的时候需要给这个节点随机分配一个层数,再将搜索路径上的节点和这个新节点通过前向后向指针串起来。如果分配的新节点的高度高于当前跳跃列表的最大高度,就需要更新一下跳跃列表的最大高度。
修改过程:一个简单的策略就是先删除这个元素,再插入这个元素,需要经过两次路径搜索。
假设这个新的 score 值不会带来排序位置上的改变,那么就不需要调整位置,直接修改元素的 score 值就可以了。
如果 score 值都一样呢?
zset 的排序元素不只看 score 值,如果 score 值相同还需要再比较 value 值。
struct zslforward {
zslnode* item;
long span; // 跨度
}
rank计算方法,将搜索路径上的所有节点的span加起来。
- 紧凑列表 listpack
struct listpack
int32 total_bytes; // 占用的总字节数
int16 size; // 元素个数
T[] entries; // 紧凑排列的元素列表
int8 end; // 同 zlend 一样,恒为 0xFF
}
ziplist的改进,更节省,更精简。设计目的是取代ziplist。由于ziplist使用太广泛,所以替换复杂度很高。目前只在Stream中用。
struct lpentry {
int encoding;
optional byte[] content;
int length; // 当前元素的长度
}
不需要存zltail_offset,因为可以直接算出来,用total_bytes和最后一个元素长度
- 基数树
跳过

若有收获,就点个赞吧
0 人点赞
