- 每10秒的操作包括:
if ( last_ten_second_ios < 200 )
do buffer pool flush 100 dirty page #刷新100个脏页
do merge at most 5 insert buffer #合并最多5个插入缓冲
do log buffer flush to disk #刷新日志缓冲
do full purge #删除无用的Undo页。每次最多20页
if ( buf_get_modified_ratio_pct > 70% ) # 判断脏页比例,大于70%
do buffer pool flush 100 dirty page #刷新100个脏页
else
buffer pool flush 10 dirty page #刷新10个脏页
goto loop - 后台循环
background loop:
do full purge # 删除无用Undo页
do merge 20 insert buffer #合并20个插入缓冲
if not idle:
goto loop:
else: #空闲
goto flush loop
第一章 MySQL体系结构和存储引擎
- 数据库和实例的区别?
数据库指的是各种文件的集合。
实例表示操作数据库文件的进程,是位于用户与操作系统之间的一层数据管理软件。
- MySQL查看配置文件
mysql —help | grep my.cnf
以读取到的最后一个配置文件中的参数为准。
- MySQL数据库文件路径
在配置文件的datadir中。Linux默认是/usr/local/mysql/data,这只是一个链接,实际位置是/opt/mysql_data/
- 存储引擎是基于表的,而不是数据库
- InnoDB存储引擎
支持事务,行锁,外键,面向OLTP。
多版本并发控制MVCC,4个隔离级别,默认可重复读。
避免幻读,使用next-key-locking策略。
如果没有显式定义主键,自动生成6字节的ROWID作为主键。
IBD文件。
- MyISAM引擎
不支持事务,有表级锁,支持全文索引,面向OLAP。
缓存池只缓存索引文件。
MYD文件用来存数据文件,MYI存索引文件。
myisampack可以用来压缩数据文件,哈夫曼编码,压缩后只读。
- NDB
share nothing集群架构
全部放在内存,主键查找极快,线性扩展,高可用高性能。
缺点,连接操作在数据库层,需要巨大网络开销。
- Memory
又名Heap引擎,全部存在内存,重启或崩溃数据会消失。
存储临时数据的临时表。
默认哈希索引。
表锁,性能差,不支持TEXT和BLOB类型。
varchar按char处理,浪费内存。
- Archive
只支持插入和查询。
zlib算法压缩,压缩比1:10.
适合存归档数据,如日志。
行锁,事务不安全。
- Federated
不存数据,用于指向远程数据库服务器的表。
不支持异构数据库表。
- Maria
MyISAM后续版本,支持缓存数据和索引文件。
行锁
MVCC。
支持事务或者非事务。
支持BLOB(二进制大对象)。
- 为什么MySQL不支持全文索引?
MySQL的MyISAM,InnoDB和Sphinx引擎支持全文索引。
- MySQL支持的连接方式
TCP/IP, 命名管道、共享内存、UNIX域套接字。
第二章 InnoDB 存储引擎
- 概述
MySQL的第一个完整支持ACID事务的引擎,行锁,MVCC,外键,提供一致性非锁定读。
最有效利用CPU和内存。
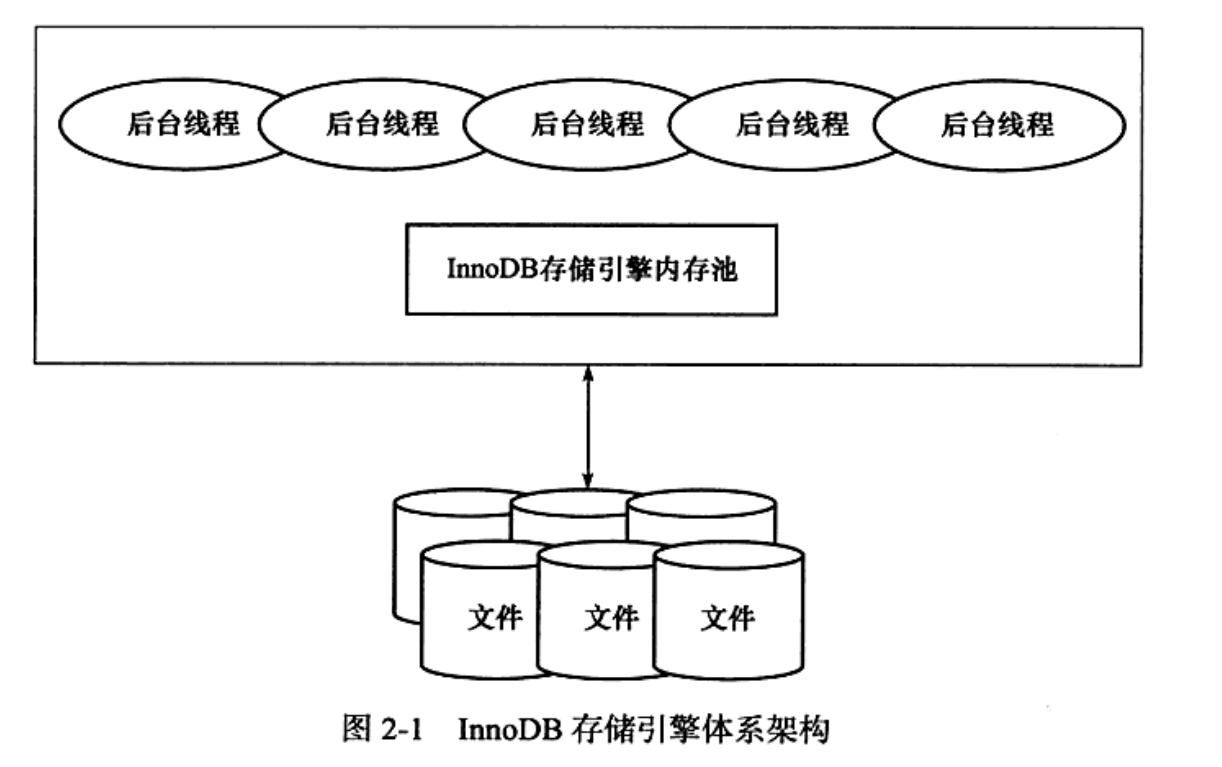
内存池:
维护所有进程需要访问的内部数据结构;
缓存磁盘数据;
重载日志缓冲。
后台线程:
负责刷新内存池的数据。
多线程模型。
- Master Thread
核心后台线程,负责将缓冲池数据异步刷新到磁盘,保证数据一致性,包括脏页的刷新,合并插入缓冲,UNDO页回收。
- IO Thread
异步,write,read,insert buffer,log IO thread。
读线程ID小于写线程。
- Purge Thread
用来回收不再需要的undolog。 事务被提交后,undolog可能不再需要。
- Page Cleaner Thread
负责脏页的刷新,减轻Master工作以及用户查询线程的阻塞。
- 内存
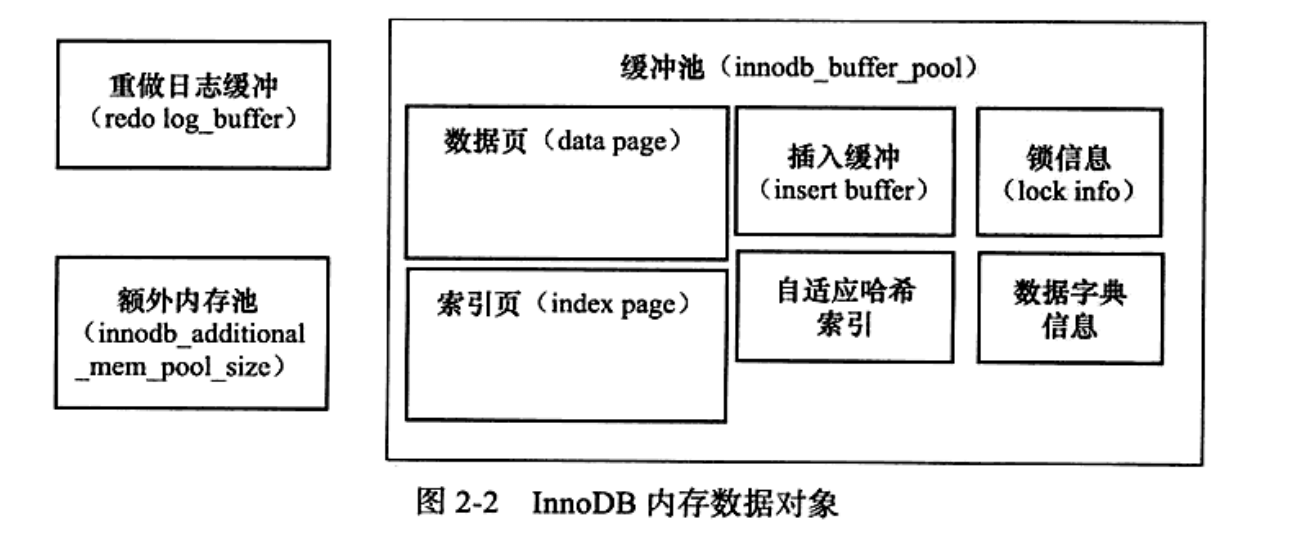
LRU算法管理。页大小16KB。
最开始所有的页都在Free列表。
若命中率小于95%,需要观察是否由于全表扫描引起的LRU列表被污染的问题。
在LRU列表中的页被修改后,叫脏页。 Checkpoint机制刷新回磁盘。
Flush列表就是脏页列表。
- 重做日志redo log缓冲
日志写在缓冲区,以一定频率刷新到重做日志。
默认8MB,每秒都会刷新。
由Master thread操作。
- 每秒刷新。
- 每个事务提交时,会将缓冲刷新到文件。
- 缓冲区空间小于1/2时刷新。
- 额外的内存池
内存堆。
内存不够时,从缓冲池申请。
申请很大缓冲池时,也应该增加这个值。
- Checkpoint(检查点)技术
如果每个页一变化就刷新,频率太高,开销大。
如果在将页的新版本刷新到磁盘时宕机,数据无法恢复。
为了解决这个问题,采用Write Ahead Log策略。提交事务时,先写重做日志,再修改页。宕机数据丢失的时候用重做日志恢复。
解决了以下问题:
- 缩短数据的恢复时间
- 缓冲池不够用时,将脏页刷新到磁盘
- 重做日志不可用时,刷新。
数据库宕机,只需要对重做日志进行恢复。
两种Checkpoint。
- Sharp, 默认方式,发生数据库关闭时将所有脏页都刷新回磁盘
- Fuzzy
- Master Thread 异步,定时刷新,不会阻塞用户查询
- FLUSH_LRU_LIST 用来保证LRU列表有100个空闲页可用
- Aysnc/Sync Flush 重做日志文件不可用时,强制刷新
- Dirty Page too much 脏页过多强制刷新,为了保证缓存池有足够可用的页
- Master Thread 工作方式
- InnoDB 1.0.x 版本之前
void master_thread (){
loop:
for(int i= 0; i<10; i++){
do thing once per second
sleep 1 second if necessary
}
do things once per ten seconds
goto loop;
}
每秒一次的操作包括:
- 日志缓冲刷新到磁盘,即使这个事务还没有提交(总是)
- 合并插入缓冲(可能)
- 至多刷新100个脏页到磁盘(可能)
- 如果当前没有用户活动,则切换到background loop(可能)。
void master_thread ( ) {
goto loop;
loop:
for (int i = 0; i<10; i++){
thread_sleep (1) // sleep 1 second
do log buffer flush to disk #刷新日志缓冲到磁盘
if ( last_one_second_ios < 5 ) 判断前一秒io次数,如果小于5次,说明IO压力小
do merge at most 5 insert buffer #合并最多5个插入缓冲
if ( buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct) #脏页比例是否超过最大脏页比例,阈值,默认90%
do buffer pool flush 100 dirty page 刷新100个脏页
if ( no user activity )
goto backgroud loop
}
每10秒的操作包括:
if ( last_ten_second_ios < 200 )
do buffer pool flush 100 dirty page #刷新100个脏页
do merge at most 5 insert buffer #合并最多5个插入缓冲
do log buffer flush to disk #刷新日志缓冲
do full purge #删除无用的Undo页。每次最多20页
if ( buf_get_modified_ratio_pct > 70% ) # 判断脏页比例,大于70%
do buffer pool flush 100 dirty page #刷新100个脏页
else
buffer pool flush 10 dirty page #刷新10个脏页
goto loop
后台循环
background loop:
do full purge # 删除无用Undo页
do merge 20 insert buffer #合并20个插入缓冲
if not idle:
goto loop:
else: #空闲
goto flush loop
flush loop:
do buffer pool flush 100 dirty page #刷新100个页直到符合条件
if ( buf_get_modified_ratio_pct>innodb_max_dirty_pages _pct )
goto flush loop
goto suspend loop
suspend loop:
waiting event
goto loop
}
每10秒的操作包括:
- 刷新100个脏页到磁盘(可能)
- 合并最多5个插入缓冲(总是)。
- 将日志缓冲刷新到磁盘
- 删除无用的Undo页
- 刷新100个或者10个脏页到磁盘。
- 1.2.x之前
跳过了
- 1.2.x
第三章 文件
- 参数文件
查看参数
SHOW VARIABLES
- 动态参数
可以在MySQL实例运行中修改。
- 静态参数
只读,不可修改。
两个关键字,global和session,表示参数的生命周期。
- 日志文件
- 错误日志 error log
记录MySQL启动、运行、关闭过程。
定位错误日志文件
SHOW VARIABLES LIKE ‘log_error’
- 二进制日志 binlog
- 慢查询日志 slow query log
- 查询日志 log
- socket文件
pid文件
MySQL表结构文件
存储引擎文件
跳过
第四章 表
第五章 索引与算法
索引不是越多越好。
InnoDB支持3种索引:
- B+树索引
- 全文索引
- 哈希索引,自适应
B+树索引并不能找到一个给定键值的具体行,只能找到该行所在的页,然后将页读入内存,再在内存中查找。
B+树是为磁盘或其他直接存取辅助设备设计的平衡二叉树
所有记录节点按顺序存在同一层叶子节点
扇出是5,也就是每个节点可以存4个键,5个孩子。
插入分三种情况:
Leaf Page表示叶节点,Index Page表示非页节点。
总结一句话,从下往上插,插完发现超了就继续拆分。
删除也分三种操作:

B+树索引分为聚集索引和辅助索引,区别是叶子节点存放的是否是一整行的信息。
- 聚集索引
叶子节点存放了整个表的行记录数据,这样的叶子节点又叫数据页。
因为数据页只能按照一棵B+树排序,所以一个表只能有一个聚集索引。
非叶节点存储的是键值和指针。
叶节点存数据。
聚集索引是逻辑连续的,物理不连续。这类似于链表。
聚集索引对主键的排序查找和范围查找非常快。
explain查询计划,rows是一个预估值。
- 辅助索引
叶子节点存的是一个书签
辅助索引可以找到指定主键。
然后利用主键在聚集索引树上查。
索引组织表和堆表
SHOW INDEX FROM 查看表的索引。
Cardinality 表示索引中唯一值的数目的估计值。 应该尽可能接近1,如果非常小,那么用户需要考虑是否删除此索引。
不是实时更新的。
在非高峰时间,使用ANALYZE TABLE的操作可以让优化器和索引更好地工作。
- Fast Index Creation (FIC)
5.5版本之前,MySQL创建索引的过程:
- 首先创建一张临时表,通过ALTER TABLE
- 把原表数据导入临时表
- 删除原表
- 修改临时表的表名
创建索引:
加一个S锁,不影响读。
删除索引:
更新内部视图,标记辅助索引空间可用,删除内部试图对该表的索引定义。
临时表的创建路径是tmpdir。
限定于辅助索引。
Online DDL
原理:在执行创建和删除操作时,将INSERT、UPDATE、DELETE这类DML操作日志写入缓存,索引创建完成以后重做应用到表上。
什么是时候添加B+树索引?
高选择性的字段。即可取值范围很广,几乎没有重复。反例,性别是低选择性。因为只有两个选项。
Cardinality怎么更新?
更新策略:
- 表中1/16的数据已发生过变化
- stat_modified_counter (发生变化的次数)> 2000000000
采样过程:
- 取得B+树种叶子节点数量A
- 随机取8个叶子节点,统计每个页中不同记录的数量P1,P2,…,P8
Cardinality = (P1+P2+…+P8)*A/8
OLTP和OLAP比较
- OLTP
- 查询操作只取一小部分数据,10条以下,很多时候取1条。
- 适合建索引
- OLAP
- 面向分析,为决策者提供支持
- 通常对时间字段索引,因为根据时间维度进行数据筛选。
- OLTP
联合索引
也是一棵B+树,不同的是键值的数量不是1.
- 覆盖索引 covering index
从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。
覆盖索引不包含整行记录的所有信息,大小远小于聚集索引,减少大量IO操作。
- 优化器选择不使用索引的情况
用户要选取的数据是整行信息,而OrderID索引不能覆盖到我们要查询的信息,因此在对OrderID索引查询到指定数据后,还需要一次书签访问来查找整行数据的信息。虽然OrderID索引中数据是顺序存放的,但是再一次进行书签查找的数据则是无序的,因此变为了磁盘上的离散读操作。如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。因为之前已经提到过,顺序读要远远快于离散读。
因此对于不能进行索引覆盖的情况,优化器选择辅助索引的情况是,通过辅助索引查找的数据是少量的。
- 索引提示 Index Hint
显式告诉优化器使用哪个索引。两种情况:
- 优化器错误选择索引。很少出现
- 可以选择的索引很多,选择执行计划的时间开销大于SQL语句本身。
USE INDEX是告诉优化器,FORCE INDEX是强制。
- Multi-Range Read 优化
为了减少磁盘的随机访问,并且将随机访问转化为顺序的数据访问,对IO-bound类型的查询性能提升大。
适用于range,ref,eq_ref类型的查询。
好处:
- MRR使数据访问变得较为顺序。
- 减少缓冲池中页被替换的次数
- 批量处理对键值的查询操作
工作方式:
- 将查询得到的辅助索引键值存放在一个缓存中,这时数据按辅助索引键值排序
- 将键值按RowID排序
- 根据RowID的顺序访问实际数据文件。
- Index Condition Pushdown (ICP) 优化
在取出索引的同时,判断是否可以进行WHERE条件的过滤,将部分WHERE过滤操作放在了存储引擎层。
支持range、ref、eq_ref、ref_or_null类型的查询。
- InnoDB存储引擎的Hash算法
拉链法。
哈希函数 h(k) = k mod m, m为略大于2倍缓冲池页数量的质数。
哈希索引只能用在等值查询,不能其他类型查询,如范围查询。
- 怎么将要查找的页转换成自然数?
表空间有一个space_id
K = space_id << 20 + space_id + offset
- 全文索引
倒排索引, full inverted index
pair是(DocumentId, Position), 如code出现在文档1的第6个单词。在innoDB叫ilist。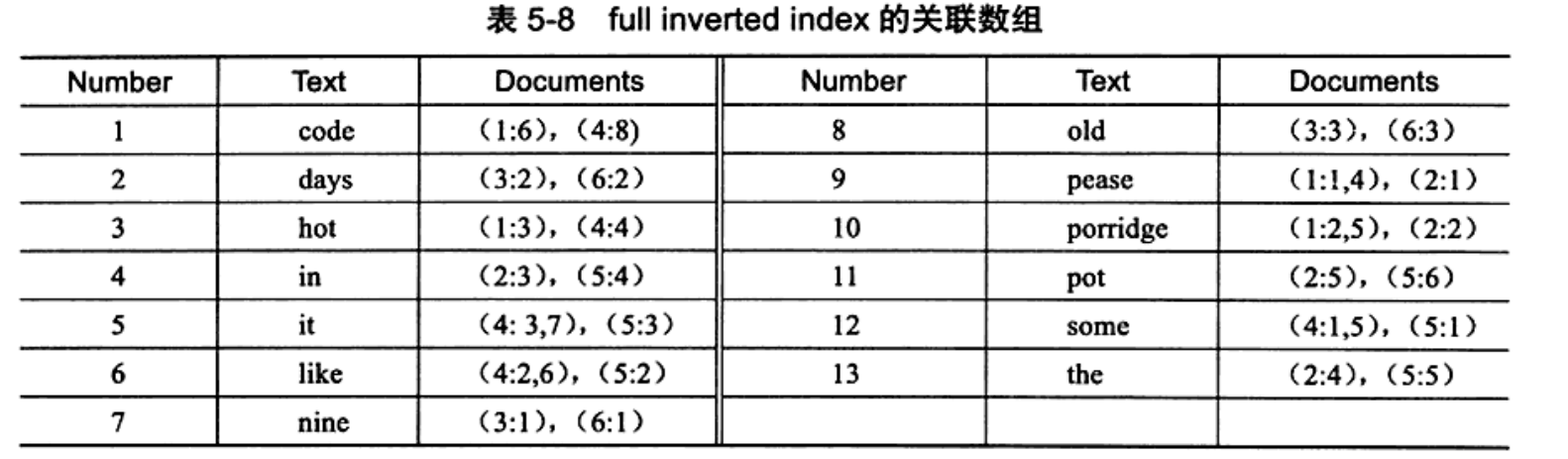
为了提高并行性能,6章辅助表,根据word的Latin编码进行分区。
辅助表存储在磁盘上。
- FTS Index Cache 全文检索索引缓存
- 红黑树结构,根据(word,ilist)排序
跳过了后面的
第六章 锁
第七章 事务
锁保证隔离性。
redo log 重做日志,保证事务的原子性和持久性。物理日志,记录的是页的物理修改操作,可以恢复提交事务修改的页操作。
undo log 保证事务一致性。回滚行记录到某个特定版本,逻辑日志,根据每行记录进行记录。
第八章 备份与恢复
第九章 性能调优
第十章 InnoDB存储引擎源代码的编译与调试

若有收获,就点个赞吧
0 人点赞
