1、概念
传统的本地文件系统(单机式),在数据量增长过快、数据备份、数据安全性、操作使用便捷性上 存在严重不足。 为了改进这些缺点, 由 Google GFS 的开源 Java 实现的Hadoop分布式文件系统(HDFS)就诞生了。
2、组件角色
2.1 Name Node(NN)
HDFS 元数据管理者,管理 NameSpace(文件系统命名空间),记录文件是如何分割成数据块以 及他们分别存储在集群中的哪些数据节点上。
NameSpace 或其本身属性的任何更改都由 NameNode 记录,维护整个文件系统的文件和目录。
2.2 DataNode(DN)
DataNode 是文件系统的工作节点。根据客户端或者 NameNode 发送的管理指令,负责 HDFS 的数据块的读写和检索操作。
通过心跳机制定期向 NameNode 发送他们的存储块的列表。
2.3 Client
客户端 Client 代表用户与 NameNode 或者 DataNode 交互来访问整个文件系统的对象。
开发人员面向 Client API 来编程实现,对 NameNode、DataNode 来说透明无感。
3、HDFS架构设计
3.1、基本架构
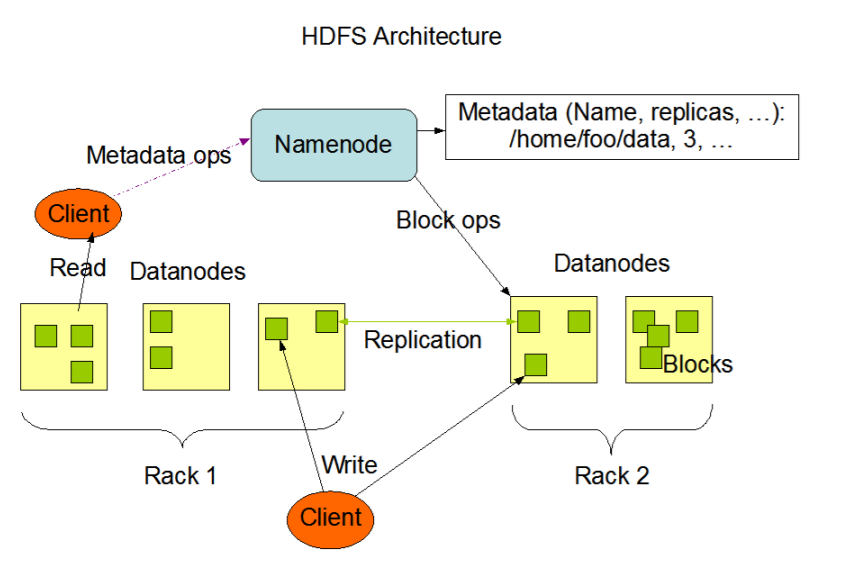
HDFS是主从架构设计(Master/slave),HDFS集群中有一个NameNode和一些DataNodes
3.2、读文件流程

详细步骤:
- Client通过RPC向NameNode发送数据请求,NameNode检查是否有权限及目标文件是否重名,不满足则报错,否则寻找数据对应的数据块的位置信息
- NameNode返回文件对应的数据块元数据信息,如所属机器、数据块的block_id、数据块的先后顺序
由Client与DataNode直接通信,读取各个block数据块的信息。过程为并行读取,由客户端合并数据
3.3、写文件流程
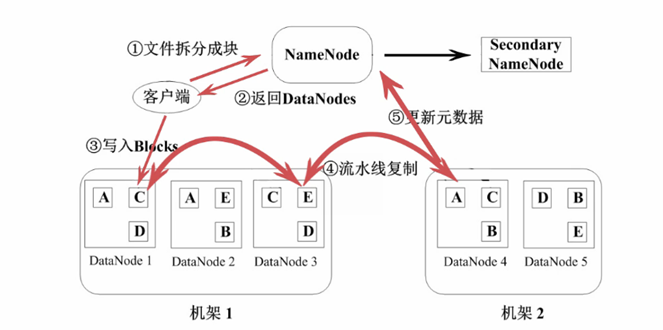
详细步骤:第一步
- Client向NameNode发送写数据请求后,寻找可以写入的数据块block信息的机器位置。
- 若文件过大,写入可能会分成很多block数据块,实际上是通过一个block一个block的申请。
- 若副本为3,则每次请求后返回一个block的对应的3个副本的block的存放位置。
- 第二步
- Client获取到对应的block数据块所处的DataNode节点位置后,Client开始写操作。
- Client先写入第一个DataNode,以数据包package的方式逐个发送和接收。如64K大小的package包大小来发送和接收。
- 存在多个副本时,package包的写入是依次进行的。写入到第一个DataNode后,第一个向第二个DataNode传输。第二个写完后,由第二个向第三个DataNode传输package。以此类推。
- 写完一个block数据块后,如果还有则反复进行第一步和第二步。
- 第三步
- 冗余备份
- 数据存储在这些HDFS中的节点上,为了防止因为某个节点宕机而导致数据丢失,HDFS对数据进行冗余备份,至于具体冗余多少个副本,在dfs.replication中配置。
- 跨机架副本存放
- 仅仅对数据进行冗余备份还不够,假设所有的备份都在一个节点上,那么该节点宕机后,数据一样会丢失,因此HDFS要有一个好的副本存放策略,该策略还在开发中。目前使用的是,以dfs.replication=3为例,在同一机架的两个节点上各备份一个副本,然后在另一个机架的某个节点上再放一个副本。前者防止该机架的某个节点宕机,后者防止某个机架宕机。
- 心跳检测
- DataNode节点定时向NameNode节点发送心跳包,以确保DataNode没有宕机。如果宕机,会采取相应措施,比如数据副本的备份。
- 数据完整性检测
- NameNode在创建HDFS文件时,会计算每个数据的校验和并储存起来。当客户端从DataNode获取数据时,他会将获取的数据的校验和与之前储存的校验和进行对比。
- 安全模式
- HDFS启动时,会进入安全模式,此时不允许写操作。这时,NameNode会收到所有DataNode节点的数据块报告,在确认安全之后,系统自动退出安全模式。
- 核心文件备份
- HDFS的核心文件是映像文件(image file)和事务日志(edit log),如果这些文件损坏,将会导致HDFS不可用。系统支持对这两个文件的备份,以确保NameNode宕机后的恢复。
空间回收
hdfs dfs
- 查看所有命令
- hdfs dfs -ls /
- 查看某目录下的文件列表
- hdfs dfs -cat /tmp/index.html
- 查看某文本文件的内容
- hdfs dfs –mkdir /home/codelx
- 创建目录
- hdfs dfs –rm -r /home/codelx
- 删除目录
- hdfs dfs -copyToLocal /home/codelx/index.html
- 从hdfs下载文件
- 等同于hdfs dfs -get
- hdfs dfs -copyFromLocal index.html /home/codelx
- 从本地上传文件到hdfs
- 等同于hdfs dfs -put
- hdfs dfs -text /home/codelx/index.html.gz | more
- 查看压缩文件的文件内容
- hdfs dfs -du -h /home/codelx
- 查看文件大小
- hdfs dfs -touchz /home/codelx/HelloWorld.txt
- 创建文件
- hdfs dfs -usage cp
- 查看命令帮助信息
- hdfs dfs -mv /home/codelx/HelloWorld.txt /home/codelx/tmp1
- 移动文件
- hdfs dfs -cp /home/codelx/HelloWorld.txt /home/codelx/tmp1
- 复制文件,路径相同时为重命名
- hdfs dfs -lsr /home/codelx/
- 循环展示该目录下的所有文件

集群管理员的常用命令:
- hdfs dfsadmin -help
- 查看管理命令的帮助信息
- hdfs dfsadmin -report
- 报告文件系统的基本信息和统计信息
- hdfs dfsadmin -setQuota 10 /home/codelx/
- 设置目录配额,目录配额是一个长整型数,限定指定目录下的名字个数
- hdfs dfsadmin -safemode get
- 返回安全模式是否开启的信息,返回Safe mode is OFF/OPEN
- hdfs dfsadmin -safemode enter
- 进入安全模式
- hdfs dfsadmin -safemode leave
- 强制NameNode退出安全模式
- hdfs dfsadmin -safemode wait
- 等待,一直到安全模式结束
6、Java操作
6.1、添加POM依赖
<properties><!-- 设置项目编码为 UTF-8 --><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><!-- 首先配置仓库的服务器位置,首选阿里云,也可以配置镜像方式,效果雷同 --><repositories><repository><id>nexus-aliyun</id><name>Nexus aliyun</name><url>http://maven.aliyun.com/nexus/content/groups/public</url></repository></repositories><dependencies><!-- 引入hadoop-cli-2.7.4依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version><scope>provided</scope></dependency></dependencies><build><finalName>TlHadoopCore</finalName><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>com.tl.job009.hdfs.HdfsFileRead</mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>assembly</goal></goals></execution></executions></plugin></plugins></build>
6.2、具体实现
```java import java.io.ByteArrayOutputStream; import java.nio.charset.StandardCharsets;
- 等待,一直到安全模式结束
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;
/**
@author simple / public class TestHDFS { /*
加载配置文件到内存对象 */ static Configuration hadoopConf = new Configuration();
/**
从HDFS上读取文件 */ public static String readFromFile(String srcFile) throws Exception { //文件路径的空判断 if (srcFile == null || srcFile.trim().length() == 0) {
throw new Exception("所要读取的源文件" + srcFile + ",不存在,请检查!");
} //将文件内容转换成字节数组 byte[] byteArray = readFromFileToByteArray(srcFile); if (byteArray.length == 0) {
return null;
} //将utf-8编码的字节数组通过utf-8再进行解码 return new String(byteArray, StandardCharsets.UTF_8); }
/**
- hdfs 文件操作工具类,从任意的hdfs filepath中读取文本内容
- @param srcFile 文件路径
- @return 结果字节数组
@throws Exception 空字符串异常 */ public static byte[] readFromFileToByteArray(String srcFile)
throws Exception {
if (srcFile == null || srcFile.trim().length() == 0) {
throw new Exception("所要读取的源文件" + srcFile + ",不存在,请检查!");
} //获取hadoopConf对应的hdfs集群的对象引用 FileSystem fs = FileSystem.get(hadoopConf); //将给定的srcFile构建成一个hdfs的路径对象Path Path hdfsPath = new Path(srcFile); FSDataInputStream hdfsInStream = fs.open(hdfsPath);
//初始化一块字节数组缓冲区,大小为65536。缓存每次从流中读取出来的字节数组 byte[] byteArray = new byte[65536]; //初始化字节数输出流, 存放最后的所有字节数组 ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 实际读过来多少 int readLen = 0; //只要还有流数据能读出来,就一直读下去 while ((readLen = hdfsInStream.read(byteArray)) > 0) {
bos.write(byteArray, 0, readLen);//byteArray = new byte[65536];
} //读取完成,将hdfs输入流关闭 hdfsInStream.close(); //将之前写到字节输出流中的字节,转换成一个整体的字节数组 byte[] resultByteArray = bos.toByteArray(); bos.close(); return resultByteArray; }
public static void main(String[] args) throws Exception { //定义要读入的hdfs的文件路径 String hdfsFilePath = “C:\idea_workspace\homework\data\input.txt”; //将文件从hdfs读取下来,转化成字符串 String result = readFromFile(hdfsFilePath); //根据题意,将字符串通过命令行输出 System.out.println(result); } } ```
7、经典问题
- HDFS为何要将文件分成block块存储?
- 减少底层操作系统的IO读取时的寻址时间
- 方便更高效的流式读取,提高吞吐量
- HDFS block块的默认大小时多少?
- dfs.blocksize为Hadoop定义block块大小的设置参数,在hdfs-site.xml中
- 版本不一样,默认值不同。Hadoop2.2.x及以后版本均为128M
- HDFS block块的大小是否可以更改?
- 可以修改
- 参数修改对以前的文件不起作用,对以后的文件起作用
- 也可针对上传文件临时修改,指定-D dfs.blocksize即可
- 一个block块文件是否可以存储多个文件数据?
- 一个block块文件不会跨文件存储
- 一个block块文件最多只会存储一个文件对应的数据
- 如果一个文件的大小,小于一个blocksize,那么它实际占用多大空间?
- 实际文件多大则占多大空间,但是占了一个block块的元数据空间大小
- 小文件越多,Hadoop NameNode的压力越大。故Hadoop的优势在于处理大文件数据,GB、TB甚至PB等。
- HDFS block越大越好?还是越小越好?
- 越大则分块越少,则NameNode压力将减小,但并行的IO和处理能力降低
- 越小则分块越多,则NameNode处理压力越大,但因为寻址时间太久,不利于提高吞吐量
- 适中即可,一般采用官方的128M即可

若有收获,就点个赞吧
0 人点赞
