1、背景
MapReduce的局限性:
- 仅支持Map和Reduce两种操作
- 编程复杂度和学习及使用成本略高
- 处理效率低
- Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据
- 任务调度及启动开销大
在机械学习和图计算等方面支持有限,性能效率表现较差
速度快
- 内存计算下,Spark比Hadoop快100倍
- 易用性
- 80 多个高级运算符
- 跨语言:使用 Java,Scala,Python,R 和 SQL 快速编写应用程序
- 通用性
- Spark 提供了大量的库,包括 SQL、DataFrames、MLib、GraphX、 Spark Streaming。
- 开发者可以在同一个应用程序中无缝组合使用这些库
- 支持多种资源管理器
- Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理 器
生态组件丰富与成熟
- spark streaming:实时数据处理
- shark/sparkSQL:用 sql 语句操作 spark 引擎
- sparkR:用 R 语言操作 Spark
- mlib:机器学习算法库
- graphx:图计算组件
4、在生态圈中的位置
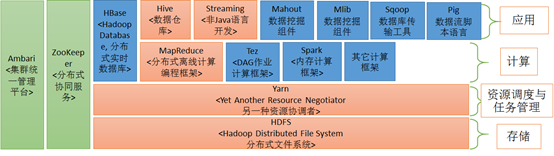
4.1、hadoop生态圈
4.2、spark生态圈

4.3、Spark Core
包含Spark的基本功能;尤其是定义RDD(弹性分布式数据集,resilient distributed dataset)的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的4.4、Spark Core
提供通过 Apache Hive 的 SQL 变体 Hive 查询语言 (HiveQL)与 Spark 进行交互的 API。每个数据库表被当做一 个 RDD,Spark SQL 查询被转换为 Spark 操作4.5、Spark Core
对实时数据流进行处理和控制。Spark Streaming 允许程序能够像普通 RDD 一样处理实时数据4.6、 MLib
一个常用机器学习算法库,算法被实现为对 RDD 的 Spark 操作。这个库包含可扩展的学习算法,比如分类、回归 等需要对大量数据集进行迭代的操作。4.7、 GraphX
控制图、并行图操作和计算的一组算法和工具的集 合。GraphX 扩展了 RDD API,包含控制图、创建子图、访问路 径上所有顶点的操作4.8、 SparkR
是一个提供从 R 中使用 Spark 的轻量级前端的 R 包。 在 Spark1.6 以后,SparkR 提供了分布式数据框架,它支持 selection,filtering,aggregation 等操作。也支持使用 MLib 分布式机器学习5、Spark Core
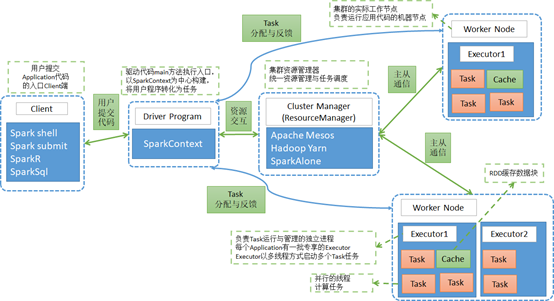
5.1、架构设计图
5.2、相关术语
RDD(Resilient Distributed DataSet)
- 弹性分布式数据集,是对数据集在spark存储和计算过程中的一种抽象
- Partition(分区)
- 计算是以partition为单位进行的,提供了一种划分数据的方式
- 算子
- 对任何函数进行某一项操作都可以认为是一个算子
- Transformation类算子
- 从一个RDD 转换生成另一个 RDD 的转换操作
- Action类算子
- 会触发 Spark 提交作业(Job),并将数据输出 Spark系统
- 窄依赖
- 一个父RDD的每个分区只被子RDD的一个分区使用
- 宽依赖
- 一个父RDD的每个分区要被子RDD 的多个分区使用
- Application
- 用户编写的Spark应用程序,包含了一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver
- 运行main函数并且创建SparkContext的程序
- ClusterManager
- 集群的资源管理器,在集群上获取资源的服务
- WorkerNode
- 集群中任何一个可以运行spark应用代码的节点
- Executor
- Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上
- Task
- 分配到executor上的基本工作单元,执行实际的计算任务
- Job(作业)
- 每个action的计算会生成一个job
Stage(阶段)
本地运行模式(local)
- 单台机器多线程来模拟spark分布式计算
- 伪分布式模式
- 单台机器多进程来模拟spark分布式计算
- standalone(client)
- 独立布署spark计算集群,driver运行在spark submit client端
- standalone(cluster)
- 独立布署spark计算集群,driver运行在spark worker node端
- spark on yarn(yarn-client)
- 以yarn集群为基础,driver运行在yarn client上
- spark on yarn(yarn-cluster)
- 以yarn集群为基础,driver运行在集群的am contianer中
spark on mesos/ec2
spark-shell
- spark命令行方式来操作spark作业
- spark-submit
- 通过程序脚本,提交相关的代码、依赖等来操作spark作业
- spark-sql
- 通过sql的方式操作spark作业
- spark-class
- 最底层的调用方式,其它调用方式多是最终转化到该方式中去提交
sparkR,sparkPython
通过其它非java、非scala语言直接操作spark作业的方式
5.5、spark-shell
# 启动sparkspark-shell --master local[*]# 直接构建一个rddvar listRdd = sc.parallelize(Seq(1,2,3,4,5,6))# 通过本地文件构建一个rddvar listRdd = sc.textfile("file:///home/spark/input.txt")# 通过HDFS文件构建一个rddvar listRdd = sc.textfile("hdfs:///home/spark/input.txt")# 进行相关算子操作listRdd.foreach(println)
5.6、Java实现spark版wordcount
5.6.1、POM配置
```xml <project xmlns=”http://maven.apache.org/POM/4.0.0“
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
homework com.codelx 1.0-SNAPSHOT 4.0.0 spark_wordcount_java 8 8 <id>nexus-aliyun</id><name>Nexus aliyun</name><url>http://maven.aliyun.com/nexus/content/groups/public</url>
org.apache.spark <artifactId>spark-core_2.11</artifactId><version>2.3.2</version><scope>provided</scope>
<groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>provided</scope>
spark_study maven-compiler-plugin 2.3.2 1.8 1.8 UTF-8 maven-assembly-plugin jar-withdependencies make-assembly package assembly
<a name="Zxmb7"></a>### 5.6.2、具体实现```javaimport org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import scala.Tuple2;import java.util.Arrays;import java.util.List;public class WordCount {public static void main(String[] args) {// 创建配置文件SparkConf sparkConf = new SparkConf();sparkConf.setAppName("spark_wordcount_java");// 创建上下文JavaSparkContext jsc = new JavaSparkContext(sparkConf);// 定义输入文件if (args[0] == null || args.length != 1) {System.err.println("传参有误 ,请检查!!!");System.exit(-1);}// 构建file rddJavaRDD<String> fileRdd = jsc.textFile(args[0]);// line rdd -> word rddJavaRDD<String> wordOneRdd = fileRdd.flatMap((FlatMapFunction<String, String>) line -> Arrays.asList(line.split("\\s+")).iterator());// word rdd -> (word,1) rddJavaPairRDD<String, Integer> wordRdd = wordOneRdd.mapToPair((PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1));// (word,1) rdd -> (word,freq) rddJavaPairRDD<String, Integer> javaPairRdd = wordRdd.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum);// 将(word,freq) rdd -> collectList<Tuple2<String, Integer>> list= javaPairRdd.collect();// 打印结果list.forEach(System.out::println);// 关闭上下文jsc.close();}}
5.7、Scala实现spark版wordcount
5.7.1、创建scala的maven项目
新增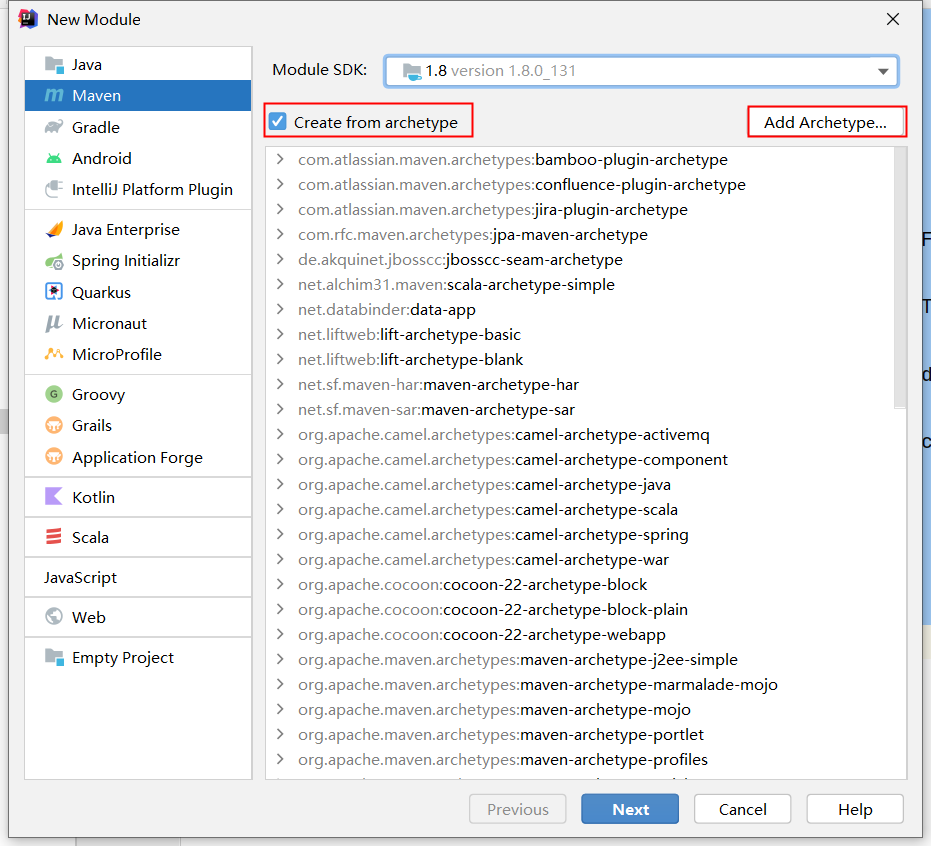
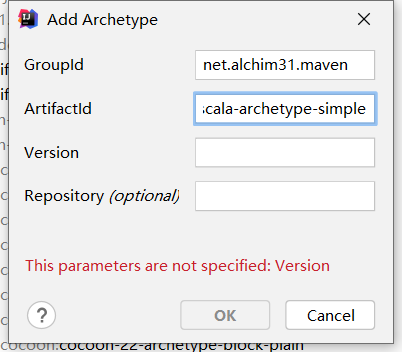
GroupId:net.alchim31.maven
ArtifactId: scala-archetype-simple
Version: 1.7
Repository:https://maven.aliyun.com/repository/central
点击ok后出现以下界面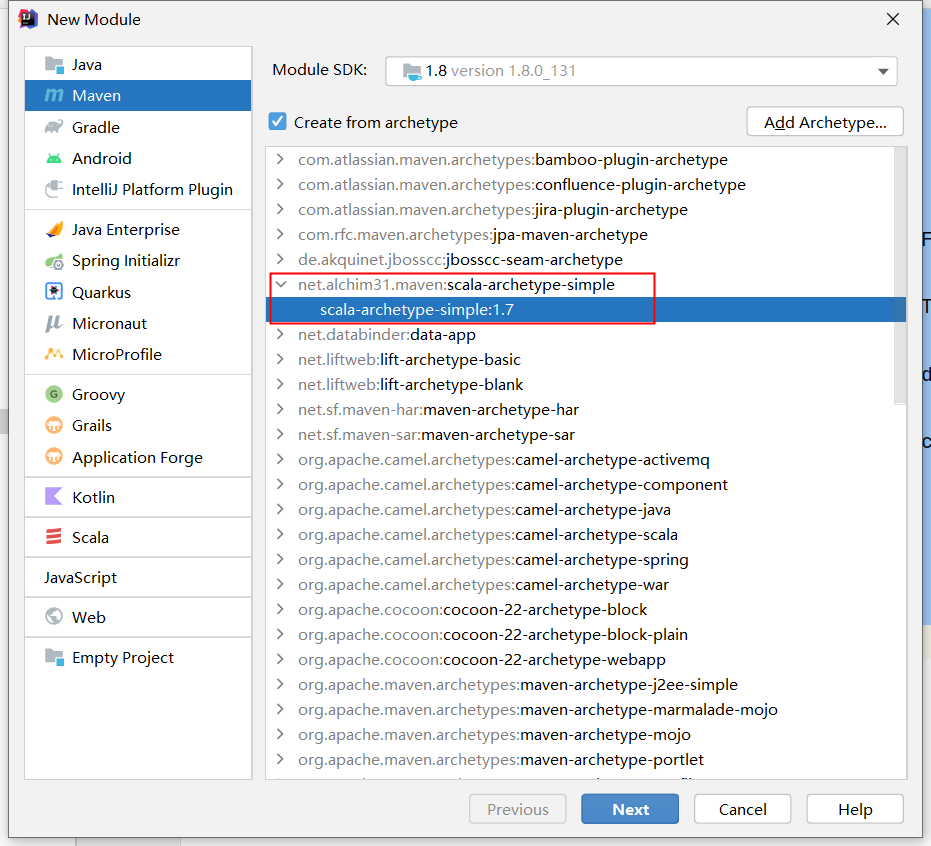
点击下一步填写相关信息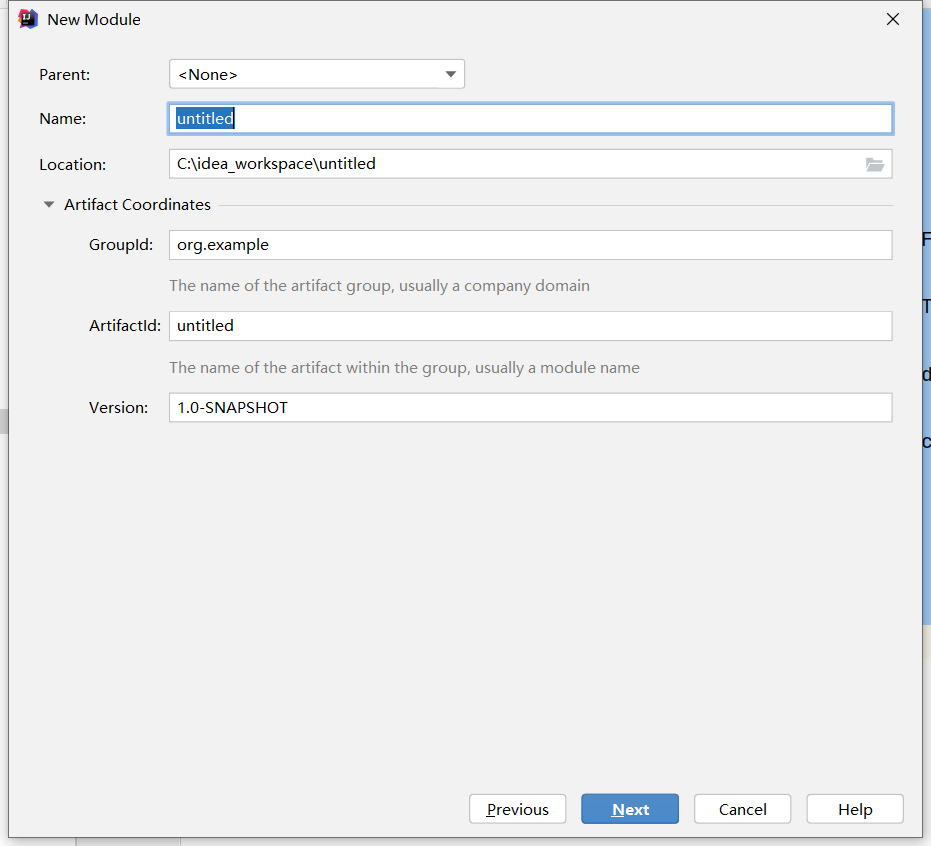
点击下一步,然后点击完成等待项目构建完成
修改POM文件信息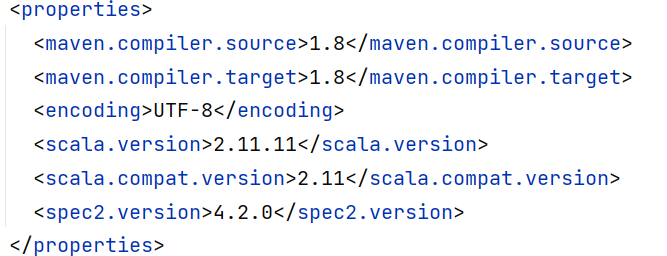
5.7.2 具体实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建配置文件
val sparkConf = new SparkConf()
sparkConf.setAppName("spark_wordcount_scala")
// sparkConf.setMaster("local[*]")
// 创建上下文
val sc = new SparkContext(sparkConf)
// 创建文件输入
var filePath = ""
if (args.length == 0 || args(0) == null) {
sc.stop()
println("请输入文件路径")
} else {
filePath = args(0)
}
// 创建rdd
var rdd = sc.textFile(filePath)
// Scala处理流程
var list = rdd.flatMap(_.split(" ")).map(item => (item, 1)).reduceByKey((a, b) => a + b).collect()
// 结果展示及关闭流
list.foreach(println)
sc.stop()
}
}
6、常用算子
6.1、 转换算子(Transformation)
6.1.1、Value型
- map
- 类比于 mapreduce 中的 map 操作,给定一个输入通过 map 函数映到成 一个新的元素输出
- flatMap
- 给定一个输入,将返回的所有结果打平成一个一维集合结构
- mapPartitions
- 以分区为单位进行计算处理,而 map 是以每个元素为单位进行计算处 理
- 当在 map 过程中需要频繁创建额外对象时,如文件输出流操作、jdbc 操作、Socket 操作等时,当用 mapPartitions 算子
- glom
- 以分区为单位,将每个分区的值形成一个数组
- union 算子
- 将两个 RDD 合并成一个 RDD,并不去重
- 会发生多分区合并成一个分区的情况
- groupBy 算子
- 输入分区与输出分区多对多型,聚合
- filter 算子
- 输出分区为输入分区子集型 ,过滤
- distinct 算子
- 输出分区为输入分区子集型,全局去重
cache 算子
mapValues 算子
- 输入分区与输出分区一对一
- 针对(Key,Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理
- combineByKey 算子
- createCombiner:对每个分区内的同组元素如何聚合,形成一个累加 器
- mergeValue:将前边的累加器与新遇到的值进行合并的方法
- mergeCombiners:每个分区都是独立处理,故同一个键可以有多个累 加器。如果有两个或者更多的分区都有对应同一个键的累加器,用方 法将各个分区的结果进行合并。
- reduceByKey 算子
- 按 key 聚合后对组进行归约处理,如求和、连接等操作
join 算子
foreach
- 循环遍历
- saveAsTextFile 算子
- 指定本地保存的目录 first.saveAsTextFile(“file:///home/spark/text”)
- 指定 hdfs 保存的目录,默认路径是 hdfs 系统中/user/当前用户路径下 first.saveAsTextFile(“spark_shell_output_1”)
- collect 算子
- 相当于 toArray 操作,将分布式 RDD 返回成为一个 scala array 数组 结果,实际是 Driver 所在的机器节点,再针对该结果操作
- collectAsMap 算子
- 相当于 toMap 操作,将分布式 RDD 的 kv 对形式返回成为一个的 scala map 集合,实际是 Driver 所在的机器节点,再针对该结果操作
- lookup 算子
- 对(Key,Value)型的 RDD 操作,返回指定 Key 对应的元素形成的 Seq。
- reduce 算子
- 先对两个元素进行 reduce 函数操作,然后将结果和迭代器取出的下一 个元素进行 reduce 函数操作,直到迭代器遍历完所有元素,得到最后 结果。
fold 算子
cartesian 算子
- 计算两个RDD的笛卡尔积
- subtract 算子
- 返回在RDD中出现,并且不在otherRDD中出现的元素,不去重
- sample 算子
- sample算子是用来抽样用的,其有3个参数
- withReplacement:表示抽出样本后是否在放回去,true表示会放回去,这也就意味着抽出的样本可能有重复
- fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
- seed:表示一个种子,根据这个seed随机抽取,一般情况下只用前两个参数就可以,这个参数一般用于调试,有时候不知道是程序出问题还是数据出了问题,就可以将这个参数设置为定值
- takeSample 算子
- 返回此RDD的固定大小的采样子集。返回Array[T]
- 注意:仅当预期结果数组较小时才应使用此方法,因为所有数据均已加载到驱动程序的内存中
- persist 算子
- MEMORY_ONLY 使用未序列化的Java对象格式,将数据保存在内存中。
- MEMORY_AND_DISK 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中
- MEMORY_ONLY_SER 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。
- MEMORY_AND_DISK_SER 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。
- DISK_ONLY 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。
- MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。
- cogroup 算子
- 相当于SQL中的全外关联full outer join,返回左右RDD中的记录,关联不上的为空
- leftOuterJoin 算子
- 左外连接
- rightOuterJoin 算子
- 右外连接
- saveAsObjectFile 算子
- 将元素序列化成对象,存储到文件中
- count 算子
- 计算个数
- top 算子
- top函数用于从RDD中,按照默认(降序)或者指定的排序规则,返回前num个元素。
aggregate 算子
先出现 MapReduce,后本着 sql on mr 的思路,产生了 Hive
- MapReduce 执行效率太慢,效率升级后产生了 Tez,再效率升级 后产生了 Spark
- Spark 为了方便操作,本着 sql on spark 的思路产生 Shark, 但 Shark 太多的借鉴和依赖 Hive,制约了 Spark 的 One Stack Rule Them All 既定方针,制约了 Spark 各个组件的相互集成
最后被 Spark 团队推翻和停更,推出了 sql on spark 新项目 SparkSql,使 sql on spark 的发展方向上,得到质的提升
7.2、简介
Spark SQL 是 Spark 处理数据的一个模块
- 专门用来处理结构化数据的模块,像 json,parquet,avro,csv,普 通表格数据等均可
与基础 RDD 的 API 不同,Spark SQL 中提供的接口将提供给更多关于结 构化数据和计算的信息,并针对这些信息,进行额外的处理优化
7.3、操作方式
7.3.1、SparkSql Shell
类似于 hive shell
//直接输入 spark-sql+自己想要添加的参数即可,与 spark-shell 相似 spark-sql [options] //如指定运行模式 spark-sql local[*] //如指定运行 spark webui 服务的端口,解决多人共用一个入口机时候的进入时候报 port bind exception 的问题 spark-sql --conf spark.ui.port=4075 //也可以用于似于 hive -e 的方式,直接直接一段 sparksql 代码 spark-sql –e “sparksql code”7.3.2、 DataFrames API
最早专为 sql on spark 设计的数据抽象,与 RDD 相似,增加了数据 结构 scheme 描述信息部分
- 写 spark 代码,面向 DF(DataFrams 缩写)编程,可以与其它 Spark 应 用代码无缝集成
- 比 RDD 更丰富的算子,更有利于提升执行效率、减少数据读取、执行 计划优化
```scala import org.apache.spark.sql.{DataFrame, SparkSession}
object TestDF { def main(args: Array[String]): Unit = { // 创建sql上下文 val ss = SparkSession .builder() .appName(“Test DF”) .master(“local[]”) .getOrCreate() // 创建df var df: DataFrame = ss.read.json(“C:\idea_workspace\homework\data\data.json”) df.select(“content”, “createTime”, “weiboUrl”) .orderBy(“createTime”) .show() // 也可以将 df 对象直接注册成一张临时表 df. createTempView (“weibo_doc”); // 然后直接写sql var resultDF =ss.sql(“select from weibo_doc”) // 数据持久化 resultDF.repartition(1).write.format(“parquet”).save(“F:\test _sbt\FirstSpark4Scala\save3”) } }
**DataFrame 数据持久化**
- parquet 数据格式,默认的输入和输出均为该格式
- spark 自带:天然集成,强力推荐的数据格式
**parquet 产生背景 **
- 面向分析型业务的列式存储格式
- 由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里 毕业成为 Apache 顶级项目
- Twitter 的日志结构是复杂的嵌套数据类型,需要设计一种列式存储格 式,既能支持关系型数据(简单数据类型),又能支持复杂的嵌套类 型的数据,同时能够适配多种数据处理框架
**parquet 的优点**
- 压缩数据,内部自带 gzip 压缩
- 不失真
- 减少 IO 吞吐量
- 高效的查询
- 多数据处理平台,均支持 parquet,包括 hive 等。
**常用命令 **<br />show、printSchema、select、filter、groupBy、count、orderBy<br />**其它操作类比于 sql 即可**
<a name="s77aX"></a>
### 7.3.3、 DataSets API
- 集成了 RDD 强类型和 DataFrames 结构化的优点,官方正强力打造的 新数据抽象类型
- 写 spark 代码,面向 DS 编程,可以与其它 Spark 应用代码无缝集 成
- 比 RDD 更丰富的算子,更有利于提升执行效率、减少数据读取、执行 计划优化
```scala
import org.apache.spark.sql.SparkSession
case class Student(name: String, age: Long, address: String)
/**
* 抽象数据类型 DataSet 测试类
*/
object TestSparkSqlDataSet {
def main(args: Array[String]): Unit = {
//1、构建 spark session
val sparkSession = SparkSession
.builder()
.appName("SparkSql-2.3.2-TestCase")
.master("local[*]")
.getOrCreate()
//引入自动隐式类型转换
import sparkSession.implicits._
// 从基础数据对象类型创建 DataSet
val primitiveDS = Seq(1, 2, 3).toDS()
val col = primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
col.foreach(println)
println("-----------------")
primitiveDS.show()
// 已为样例类 case class 创建完成编码类 Encoder
val caseClassDS = Seq(Student("脱口秀大会", 3, "北京")).toDS()
caseClassDS.show()
// 指定相应的文件导入形成样例类对应的 DataSet,通过 json 的 key 和 样例类的字段名称对应即可
val path = "C:\\idea_workspace\\homework\\data\\student_data.txt"
val peopleDS = sparkSession.read.json(path).as[Student]
peopleDS.select("name", "age", "address").show()
//关停会话上下文
sparkSession.stop()
}
}
7.3.4、 面向程序接口对接的操作
通过 jdbc、odbc 链接后,发送相关的 sparksql 请求,实现基于 sparksql 功能开发
7.3.5、Rdd转DF
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.Row
object TestRddToDataFrame {
def main(args: Array[String]): Unit = {
//1、构建 spark session
val sparkSession = SparkSession
.builder()
.appName("SparkSql-2.3.2-TestCase")
.master("local[*]")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import sparkSession.implicits._
//2、构建 scheme
val schema =
StructType(
"stdNo name classNo className".split(" ").map(fieldName =>
StructField(fieldName, StringType, true)))
//3、构建 rdd,linesRDD
val studentRDD =
sparkSession.sparkContext.textFile("F:\\test_sbt\\FirstSpark4Scala\\stu
dent_mysql.txt")
//4、将 linesRDD 转换成 Row rdd
val rowRDD = studentRDD.map(_.split("\\t")).map(p => Row(p(0),
p(1), p(2), p(3)))
//5、创建 df,由 row rdd + scheme
val studentDataFrame = sparkSession.createDataFrame(rowRDD, schema)
//6、df 算子操作
studentDataFrame.printSchema()
studentDataFrame.show()
//7、停掉相关会话
sparkSession.stop()
}
}
7.4、 RDD、DataFrame、DataSet对比分析
相同点
- 全都是 spark 平台下的分布式弹性数据集,为处理超大型数据提供便 利
- 三者都有惰性机制,在进行 Transform 操作时不会立即执行,在遇到 Action 操作时会正式提交作业执行。
- 均采用 spark 的内存运算和优化策略,内存使用和执行效率上均可以 得到保障。
- 均有 partition 的概念,便于分布式并行计算处理,达到分而治之。
- 均有许多共同的函数,如 map、filter、sort 等。
- 在进行三者的相关操作时候,个别特殊操作时必须引入一个相同的包 依赖。( 早期称为 import sqlContext.implicits.,最新版本称 为 import spark.implicits.)
- DF 和 DS 均可以通过模式匹配获取内部的变量类型和值。
DF 和 DS 产生于 SparkSql,天然支持 SparkSql
区别点
RDD
- 不支持 SparkSql 操作,均需进行转成 DF 或是 DS 才行。
- 类型是安全的,编译时候即可检查出类型错误。(强类型)
- 机器间通信、IO 操作均需要序列化、反序列化对象,性能开销大。
- DataFrame
- 有 scheme 的 RDD:比 RDD 增加了数据的描述信息。
- 比 RDD 的 API 更丰富,增加了针对结构化数据 API。
- 只有一个固定类型的 DataSet,即为 DataFrame=DataSet[Row]
- 序列化和反序列化时做了结构化优化,减少了不必要的结构化信息的 序列化,提高了执行效率。
- DataSet
- 强类型的 DataFrame,与 DF 有完全相同的成员函数。
- 每行的类型不固定,需要使用模式匹配 case class 后,获取实际的 类信息、字段类型、字段值。
- 访问对象数据时,比 DF 更加直接简单。
- 在序列化和反序列化时,引入了 Encoder 机制,达到按需序列化和反 序列化,不必像之前整个对象操作了,进一步提高了效率。
应用场景
- 使用 RDD 场景
- 数据为非结构化,如流媒体等数据
- 对数据集进行底层的转换、处理、控制
- 不需要列式处理,而是通过常规的对象.属性来使用数据。
- 对 DF、DS 带来的开发效率、执行效率提升不敏感时
- 使用 DF(必须)
- R 或是 python 语言开发者,使用 DF
- 使用 DS(必须)
- 在编译时就有高度的类型安全,想要有类型的 JVM 对象,用上 Catalyst 优化,并得益于 Tungsten 生成的高效代码
使用 DF、DS 场景
数据处理类型分类
- 静态数据
- 数据源是不变的、有限的、显式离散的
- 多适用于批量计算、离线计算
- 流数据
- 数据是变动的、无限的、连续的
- 多适用于实时计算,能在秒级、秒内处理完成
- sparkstreaming 是什么
- 一句话总结:微批处理的流式(数据)实时计算框架。
- 原理:是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短 到秒级时,即可用于处理实时数据流。
- 优点
- 可以和 spark core、sparksql 等无缝集成
- 支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、 ZeroMQ、Kinesis 以及 TCP sockets,然后可以使用诸如 map、 reduce、join 等高级函数进行复杂算法的处理,最后可以将处 理结果存储到 HDFS 文件系统,数据库等。
- 重要概念说明
- StreamingContext
- 类比于 SparkContext,SparkSqlContext
- 流计算框架中的中枢类,负责各种环境信息、分发调度等任 务。
- 数据源
- 简称:Source,意为 DataSource 的缩写
- 指流数据的来源是哪里,如文件,Socket 输入、Kafka 等。
- 离散流
- 英文称 Discretized Stream,简称 DStream,即为 sparkstreaming 微批处理当中的数据抽象单位。
- 是继 spark core 的 RDD、spark sql 的 DataFrame 和 DataSet 后又一基础的数据类型,是 spark streaming 特有的数据类 型。
- 输入离散流
- 英文简称:Input DStream
- 将 Spark Streaming 连接到一个外部 Source 数据源来读取数 据的统称
- 批数据
- 英文称 Batch Data
- 连续数据离散化的步骤:将流式实时连续的数据整体转化成以 时间片为单位进行分批,即将流式数据转化成时间片为单位数 据进行批数据处理,随着时间推移,这些处理结果即形成结果 数据流,即流处理引擎形成。
- 时间片或批处理时间间隔
- 英文称 batch interval
- 人为对流数据进行定量的标准,以时间片作为拆分流数据的依 据。
- 一个时间片的数据对应一个 RDD 实例。
- 窗口长度
- 英文称 window length
- 一个窗口覆盖的流数据的时间长度,必须是批处理时间间隔的 倍数。
- 滑动窗口时间间隔
- 滑动窗口:简称 Sliding window
- 前一个窗口到后一个窗口所经过的时间长度间隔。必须是批处 理时间间隔的倍数
- StreamingContext
- 静态数据
- 处理流程

- 内部工作流程
Spark Streaming 接收实时输入数据流并将数据分成批处理,然后由 SparkCore 引擎处理,以批量生成最终结果流
8.2、代码实现
POM依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.codelx</groupId>
<artifactId>2022_03_07</artifactId>
<version>1.0-SNAPSHOT</version>
<name>${project.artifactId}</name>
<description>My wonderfull scala app</description>
<inceptionYear>2018</inceptionYear>
<licenses>
<license>
<name>My License</name>
<url>http://....</url>
<distribution>repo</distribution>
</license>
</licenses>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.11</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<spec2.version>4.2.0</spec2.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.7</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.compat.version}</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<!-- Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.compat.version}</artifactId>
<version>3.0.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs2</groupId>
<artifactId>specs2-core_${scala.compat.version}</artifactId>
<version>${spec2.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs2</groupId>
<artifactId>specs2-junit_${scala.compat.version}</artifactId>
<version>${spec2.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.compat.version}</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 因为往往是scala和java在一起混合开发,故需要设置多个源文件目录,故需要maven新插件build-helper-maven-plugin来支持设置多个源文件夹,也可以设置多个资源路径 -->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<!-- 我们可以通过在这里添加多个source节点,来添加任意多个源文件夹 -->
<source>${basedir}/src/main/java</source>
<source>${basedir}/src/main/scala</source>
</sources>
</configuration>
</execution>
<execution>
<id>add-test-source</id>
<phase>generate-test-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>${basedir}/src/test/scala</source>
<source>${basedir}/src/test/java</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<!-- <archive> <manifest> <mainClass>com.tl.job017.hdfs.HdfsFileRead</mainClass>
</manifest> </archive> -->
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.21.0</version>
<configuration>
<!-- Tests will be run with scalatest-maven-plugin instead -->
<skipTests>true</skipTests>
</configuration>
</plugin>
<plugin>
<groupId>org.scalatest</groupId>
<artifactId>scalatest-maven-plugin</artifactId>
<version>2.0.0</version>
<configuration>
<reportsDirectory>${project.build.directory}/surefire-reports</reportsDirectory>
<junitxml>.</junitxml>
<filereports>TestSuiteReport.txt</filereports>
<!-- Comma separated list of JUnit test class names to execute -->
<jUnitClasses>samples.AppTest</jUnitClasses>
</configuration>
<executions>
<execution>
<id>test</id>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
具体实现
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NetworkWordCount {
def main(args: Array[String]): Unit = {
// 要初始化 Spark Streaming 程序,必须创建一个 StreamingContext 对象,
//它是所有 Spark Streaming 功能的主要入口点。
//一切都从 SparkConf 开始
val conf = new SparkConf().setMaster("local[*]")
.setAppName("NetworkWordCount")
//指定时间间隔的 ssc 初始化
val ssc = new StreamingContext(conf, Seconds(5))
//ssc 指定来自 TCP 源作为输入数据源,即链接一个指定主机的已打开的 TCP 端口,从该端口中读取文本数据,每行以”\n”作为每行的结尾。
val lines = ssc.socketTextStream("192.168.2.57", 9999)
//将 DStream 进行打平处理,实际是对其内部的离散的 rdd 进行打平处理
val words = lines.flatMap(_.split(" "))
// 将单列的 word 转化为双列的 kv 结构,用于后边的 wc 操作
val pairs = words.map(word => (word, 1))
//对 kv 的输出进行 wc 计算
val wordCounts = pairs.reduceByKey(_ + _)
//打印 wc 结果到控制台
wordCounts.print()
//正式开始计算
ssc.start()
//等待计算结束,一般流式计算没有异常或人为干预是一直保持运行状态的
ssc.awaitTermination()
}
}
8.3、常见问题
- 输入 DStream 和 Receivers
- 输入 DStreams :即为从数据流源接收的输入数据流的 DStream。
- 内置两类流媒体源
- 基本流数据源:包括本地或是 hdfs 文件系统、Socket 套接字 链接、Akka actor 等。
- 高级流数据源:包括 Kafka、Flume、Kinesis、ZeroMQ 等数据 源,可以通过引入第三方工具库来使用该数据源。
- 内置两类流媒体源
- Receivers:每个输入 DStream(除文件流之外)均与 Receiver 相对关 联,该对象负责从流源接收数据并将其存储在 Spark 的内存中进行处 理。
- 输入 DStreams :即为从数据流源接收的输入数据流的 DStream。
- 关于多路输入流的处理 o
- SparkStreaming 对多路输入流进行自然和谐的支持。
- 通过 ssc 可以同时创建多路输入流,并直接提供 api 进行各种的 join、leftOuterJoin、rightOuterJoin 等操作。
- DStreams 的输出操作
- print():在运行流应用程序的驱动程序节点上打印 DStream 中每批数 据的前十个元素。
- saveAsTextFiles:将此 DStream 的内容保存为文本文件
- saveAsObjectFiles:将此 DStream 的内容保存为 SequenceFiles 序列 化 Java 对象。
- saveAsHadoopFiles:将此 DStream 的内容保存为 Hadoop 文件。
- foreachRDD:最通用的输出运算符,它将函数 func 应用于从流生成的 每个 RDD。此函数应将每个 RDD 中的数据推送到外部系统,例如将 RDD 保存到文件,或通过网络将其写入数据库。请注意,函数 func 在运行 流应用程序的驱动程序 Driver 进程中执行。
- foreach 和 foreachPartion 运行在 Worker 节点。
- 关于 SparkStreaming 本地运行时线程数量的设置
- 在本地运行 Spark Streaming 程序时,不能使用“local”或“local [1]”作为主 URL。
- 该设置即只有一个线程将用于本地运行任务。如果正使用基于接收器 的输入 DStream,则必须使用单个线程来运行接收器,而无法留下用于 处理接收数据的线程。故本地运行时,始终使用“local [ n ]”作为 主 URL,其中 n >要运行的接收器数量
- 关于 SparkStreaming 在集群运行时 CPU 逻辑核心数设置
- 一个逻辑 CPU 的资源相当于可以开启一个线程的能力。
- 在集群上运行时,分配给 SparkStreaming 应用程序的核心数必须大于 接收器数。否则系统将只能接收数据,但无法处理数据

若有收获,就点个赞吧
0 人点赞
