1、起源
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一 。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法 。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已成为Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司 。
2、Hadoop核心组件
核心组件包括 Hadoop 的基础组件 HDFS、MapReduce 和 Yarn,以及其他常用组件如:HBase、Hive、 Hadoop Streaming、Zookeeper 等。 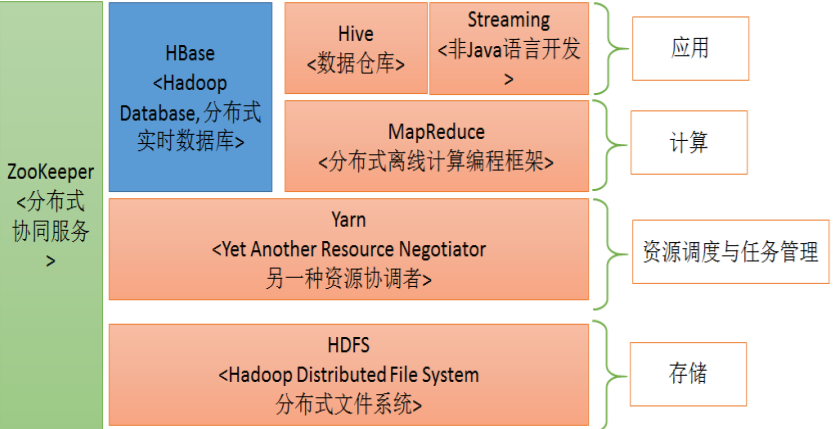
2.1 HDFS
2.2 Yarn
提供资源调度与任务管理功能
- 资源调度:根据申请的计算任务,合理分配集群中的计算节点(计算机)。
- 任务管理:任务在执行过程中,负责过程监控、状态反馈、任务再调度等工作。
2.3 MapReduce
分布式并行编程模型和计算框架。解决分布式编程门槛高的问题,基于其框架对 分布式计算的抽象 map 和 reduce,可以轻松实现分布式计算程序。2.4 Hive
提供数据摘要和查询的数据仓库。解决数据仓库构建问题,基于 Hadoop 平台的存储 与计算,与传统 SQL 相结合,让熟悉 SQL 的编程人员轻松向 Hadoop 平台迁移。2.5 Streaming
解决非 Java 开发人员使用 Hadoop 平台的语言问题,使各种语言如 C++、python、 shell 等均可以无障碍使用 Hadoop 平台。2.6 Hbase
基于列式存储模型的分布式数据库。解决某些场景下,需要 Hadoop 平台数据及时响应的问题。2.7 Zookeeper
分布式协同服务。主要解决分布式下数据管理问题:统一命名、状态同步、集群 管理、配置同步等。3、Hadoop生态圈

4、 Ambari 平台环境介绍
Apache Ambari 是一种基于 Web 的工具,支持 Apache Hadoop 集群的供应、管理和监控。 Ambari 已支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、 Sqoop 和 Hcatalog 等。
同类产品为 Cloudera Manager 的 CDH。
优点:
Web 安装图形界面操作便捷
Hadoop 家族个组件支持全面
社区资源比较丰富
缺点:
Bug 较多:安装过程中,莫名其妙的出现错误。系统运维过程中偶尔出错。以上两种情况 重启就正常。
安装速度与网络质量关系较大,往往时间较长。
在合理避免大坑的情况下,3 小时内可以搭建一个基本版的集群。

若有收获,就点个赞吧
0 人点赞
