1、概述
1.1、背景
- 内因
- Hadoop中的MR/HDFS/Hive等适合做批量处理,但只能顺序读取
外因
Hadoop Database的简称
- Hbase是一种数据模型
- 构建在HDFS上,分布式面向列的数据库
- 参考Google的bigtable数据库设计,拥有HDFS的分块存储、冗余、容错的优良特性
-
1.3、应用场景
高并发、简单条件、随机查询
- 不善长join类操作,新版本正在陆续支持与升级中
- 半结构化、非结构化数据存储
- 数据采集结果存储、海量数据实时查询等项目开发当中使用非常广泛。
国外的facebook、google、yahoo!,国内的互联网中大型公司、BAT内部均有广泛使用。
2、数据模型
2.1、重要概念
1、命名空间(namespace)
- 类比于关系型数据库中的不同的Database数据库。
- 利用命名空间,在多租户场景下可做到更好的资源和数据隔离。
- 2、表(table)
- 类比于rdb中的表
- 以”表”为单位组织数据,表由多行组成
- 3、行(row)
- 行由一个RowKey和多个列族组成,一个行有一个RowKey作为行的唯一标识。
- 4、列族(column family,简称CF)
- 每一行由若干列族组成,每个列族下可包含多个列。
- 列族是列共性的一些体现,如baseInfo列族和addressInfo列族,baseInfo列族可以包括name(名字),age(年龄),gender(性别)属性列,而addressInfo列族可以包括province(省份),city(市), email(邮箱)等属性列。
- 物理上,同一列族的数据存储在一起的。
- 5、列限定符(column qualifier)
- 列由列族和列限定符唯一指定,像如上的name、age即是baseInfo列族的列限定符。
- 6、单元格(cell)
- 单元格由RowKey、列族、列限定符唯一定位,单元格之中存放一个值(Value)和一个版本号。
7、时间戳(timestamp)
面向列(列族)定义、列(列族)存储的数据库,其数据库也称为空间namespace。
- 表的基本组成单元是行,每行有个唯一标识称为rowKey,表中数据按rowKey进行字典序排序存储。
- 一个表有多个列族以及每一个列族可以有任意数量的列,后续新增列的值连续地存储在磁盘上。
表中的每个单元格值都具有时间戳,来标识该单元格的最后插入或更新时间。
2.3、逻辑说明
表是行的集合
- 行是列族的集合
- 列族是列的集合
- 列是键值对的集合
2.4、数据表样例

3、架构设计
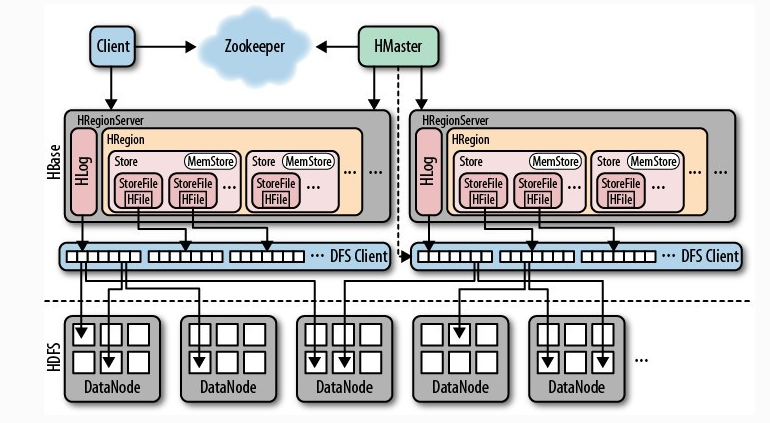
3.1、核心概念
- Client
- 发起读写请求的角色,面向Hbase Client编程
- Zookeeper
- 存储Hbase的元数据
- 负责HMaster的选择和主备切换
- 负责对HRegionServer进行监控
- 对RootRegion的管理,即对meta表所在数据存储的region的管理
- Region 管理,普通region的上下线等状态信息管理
- 分布式SplitWAL任务管理,即当HRegionServer出现宕机后,接收HMaster分配下来的分布式恢复的日志位置,通知到各个健康的HRegionServer来通过获取日志数据做replay操作恢复宕机的HRegionServer中的原数据
- HMaster
- 管理用户对Table的增删改查操作
- 管理HRegionServer,实现其负载均衡,调整Region分布
- 管理和分配Region:Region分裂后,负责新Region的分配;某一个RegionServer宕机之后,接收到ZooKeeper 的NodeDelete 通知然后开始该失效RegionServer上的Region的迁移
- HRegionServer
- 维护本地的Region,并处理客户端对这些Region读写的I/O请求
- 负责切分本地Region,当StoreFile大小超过阀值,则会触发Region的split操作,把当前Region切分成2个Region,然后老的Region会下线;新的2个Region会被HMaster分配到相对应的HRegionServer上
- HRegionServer内部管理着一系列HRegion对象,每一个HRegion对象对应着Table中的Region。
- HRegion由多个HStore组成,每一个HStore对应了Table中的一个ColumnFamily(列族)的存储。因此可以看出每一个列族其实就是一个集中的存储单元,因此最好将具备共同I/O特性的列放在一个列族里,这样可以保证读写的高效。
- HRegion
- Table在行(水平)的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
- Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值时就会分成两个新的region。
- 每个region由以下信息标识:< 表名,startRowkey,创建时间>
- HStore
- HStore是HBase存储的核心,主要由2部分组成:MemStore和StoreFile。
- MemStore就是 SortedMemory Buffer,用户写入的数据首先会放在这个内存缓存中,当缓冲区满了以后,flush 到StoreFile(底层是HFile)中,当StoreFile文件数达到阀值会触发Compact操作,将多个StoreFile进行合并,合并成一个大的StoreFile。
- 合并过程中会进行版本的合并和数据删除,因此所有的更新和删除操作(标记删除)都是在compact阶段完成的,这使得用户的写操作只要写入内存就可以立即返回,保证HBase I/O高性能。
- 当合并之后的StoreFile超过阀值,则会触发HRegion的split操作,将一个HRegion分成2个HRegion,老的HRegion会被下线,新的会被HMaster分配到对应的HRegionServer上,可能是当前HRegionServer也有可能是其他HRegionServer上。
- MemStore
- MemStore是放在内存里的,保存修改的数据即keyValues。
- 当MemStore的大小达到一个阀值(默认128MB)时,memStore会被flush到文件,即生成一个快照。
- 有一个独立线程来负责MemStore的flush操作。
- StoreFile
- memStore内存中的数据写到文件后就是StoreFile,
- StoreFile底层是以HFile的格式保存。
- 当StoreFile文件的数量增长到一定阈值后,系统会进行合并(minor compaction、major compaction),在合并过程中会进行版本合并和删除工作(major),形成更大的storefile。
- HFile
- 当MemStore累积足够的数据时,整个已排序的KeyValue集将被写入HDFS中的新HFile,其为顺序写入,故速度非常快,因为它避免了移动磁盘驱动器磁头。
- key-value格式的数据存储文件,是一个二进制的文件。
- StoreFile就是针对HFile进行了一个轻量级的封装。
- Minor Compaction
- HBase会自动选择一些较小的StoreFile,并将它们重写成更少且更大的StoreFiles,该过程称为Minor Compaction。
- 通过将较小的文件重写为较少但较大的文件来减少存储文件的数量,执行合并排序。
- Major Compaction
- Major compaction将region所有的StoreFile合并,并重写到一个StoreFile中,每个列族对应这样的一个StoreFile。
- 在此过程中,删除已删除或过期的Cell,会提升了读取性能,由于Major compaction重写了所有HFile文件,因此在此过程中可能会发生大量磁盘I/O和网络流量。这被称为写入放大。
- Major compaction执行计划可以自动运行。由于写入放大,通常计划在周末或晚上等集群负载低的时候进行Major compaction。
- WAL机制
- WriteAhead Log的简称,即先写日志的意思
- 解决的是hbase写入过程中,当写入MemoryStore后,HRegionServer宕机或是其它异常情况下数据无法持久化的问题。
- 解决方法(WAL的运行原理)
- 写入时候先写日志即WAL,再写MemoryStore,当MemoryStore写入成功后,客户端写入方则会得到确定写成功的消息。
- 此种情况下,若出现MemoryStore无法持久化成功的情况,可以通过replay WAL log的方式进行恢复。
HLog
Client访问ZooKeeper获取RootRegion的位置信息
- 访问RootRegion的元数据请求region所在的region server,根据namespace、表名和rowkey根据meta表的数据找到写入数据对应的region信息,找到小于rowkey并且最接近rowkey的startkey对应的region,即为目标region信息
- 向region对应的region server发起写入请求
- 考虑到数据丢失的风险,所以先写入WAL(Wirte Ahead Log)
- 将更新写入到memstore中,若增加大小达到Flush Size阈值,则触发flush memstore,把数据写出到hdfs中,生成一个storefile
- 如果storefile数量增长到一定的阈值后,触发compact 合并,将多个storefile合并成一个
如果单个storefile的大小超过一定的阈值后,触发split操作,把当前region拆分成两个,新拆分的两个region会被Hbase Master分配到对应的两个region server上
5、读流程
Client访问ZooKeeper获取RootRegion的位置信息
- 访问RootRegion的元数据请求region所在的region server,根据namespace、表名和rowkey根据meta表的数据找到写入数据对应的region信息,找到小于rowkey并且最接近rowkey的startkey对应的region,即为目标region信息
- 向region对应的region server发起读取请求
- 先从memstore中查找数据,如果找到则返回
- 再从BlockCache中查找数据,如果找到则返回
再从StoreFile中查找数据,如果找到则返回,如果没有找到则返回null
如果是从StoreFile中读取到的数据,则要写入BlockCache后再返回给客户端
6、shell操作
6.1、系统操作(General)
# 进入集群环境hbase shell# 查看hbase集群状态status# 查看hbase的版本信息version# 当前操作hbase的用户是哪个whoami
6.1、DDL操作
# 列出所有表list# 创建表(create)create "codelx","base_info","address_info"# 禁用一张表disable 'codelx'# 表是否被禁用is_disabled 'codelx'# 启用一张表enable 'codelx'# 表是否被启用is_enabled 'codelx'# 查看表的描述describe 'codelx'# 加入一个新的列族(alter)alter'codelx','private_info'# 验证表是否存在exists 'codelx'# 删除表,表需先禁用,然后才能删除disable 'codelx'drop 'codelx'# 禁用多个表disable_all# 删除多个表,表需先禁用,然后才能删除drop_all
6.1、DML操作
# 插入数据put 'codelx','r1','base_info:username','zhangsan'# scan遍历全表scan 'codelx'# scan范围查询scan 'codelx', { LIMIT=> 2,STARTROW => 'r1',ENDROW=>'r2'}# get按rowKey查询get "codelx","r1"# 获取行中指定的列数据get 'codelx','r1','base_info:username'# 删除指定条件的列数据delete 'codelx','r1','base_info:username'# 清空表Truncate(只是清空数据)truncate 'codelx'# 查看当前空间(数据库)下的所有表list_namespace_tables'default'# 查看表的相关列族的版本号数量设置describe 'codelx'# 修改列族的版本号个数alter 'codelx',NAME=>'baseInfo',VERSIONS=>2# 查看表数据的指定版本个数(有效的版本号,若已删除版本但处于标记状态,并未真正删除数据的不属于有效的版本数据)scan 'codelx',{VERSIONS => 4}# 查看表数据的指定所有版本对应的数据(包括全部版本的实际还存在的数据, 即包括加了删除标记但未正式删除的)scan 'codelx',{RAW=>true,VERSIONS => 4}
6.1、Namespace操作
# 创建一个命名空间create_namespace 'codelx'# 更新命名空间alter_namespace 'codelx', {METHOD => 'set','PROPERTY_NAME' =>'PROPERTY_VALUE'}# 查看命令空间描述信息describe_namespace 'codelx'# 查看所有命名空间list_namespace# 在指定的命名空间下创建表create 'codelx:Student','base_info'# 删除命名空间drop_namespace 'codelx'
7、Java操作
7.1、添加依赖
<dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.1.2</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.10</version></dependency></dependencies><!-- all in one 打包 --><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>assembly</goal></goals></execution></executions></plugin></plugins></build>
7.2、编写文件IO工具类
```java import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List;
public class FileUtils {
public static List
<a name="xwl64"></a>
## 7.3、编写实体类
```java
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author simple
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
//姓名
private String name;
//年龄
private String age;
//性别
private String gender;
//省份
private String province;
//城市
private String city;
}
7.4、编写输出结果转换为对象工具类
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellScanner;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.lang.reflect.Field;
/**
* @author simple
*/
public class ObjectAssignment {
/**
* 输出结果转对象
*
* @param clazz 对象的类
* @param result 输出结果
* @return 封装的对象
*/
public static <T> T resultToObject(Class<T> clazz, Result result) throws InstantiationException, IllegalAccessException, IOException, NoSuchFieldException {
// 实例化对象
T temp = clazz.newInstance();
// 使用cell获取result里面的数据
CellScanner cellScanner = result.cellScanner();
while (cellScanner.advance()) {
Cell cell = cellScanner.current();
// 使用 CellUtil工具类,从cell中把属性名获取出来
String qualify = Bytes.toString(CellUtil.cloneQualifier(cell));
// 获取对应的属性
Field field = clazz.getDeclaredField(qualify);
// 根据不同的属性类型赋值
Object value = null;
if ("class java.lang.Integer".equals(field.getGenericType().toString())) {
value= Bytes.toInt(CellUtil.cloneValue(cell));
} else if ("class java.lang.String".equals(field.getGenericType().toString())) {
value= Bytes.toString(CellUtil.cloneValue(cell));
}
// 获取所有权限
field.setAccessible(true);
field.set(temp,value);
}
return temp;
}
}
7.5、编写HBase相关操作类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* @author simple
*/
public class HbaseUtils {
/**
* 连接对象
*/
public Connection connection;
/**
* 配置对象
*/
public Configuration configuration = HBaseConfiguration.create();
public HbaseUtils() throws IOException {
configuration.set("hbase.zookeeper.quorum",
"cluster1.hadoop");
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("zookeeper.znode.parent", "/hbase-unsecure");
// 对connection初始化
connection = ConnectionFactory.createConnection(configuration);
}
/**
* 创建表
*
* @param tableName 表名
* @param cfs 列族名
*/
public void createTable(String tableName, String... cfs) throws IOException {
// 管理器对象
Admin admin = connection.getAdmin();
// 创建表对象
TableName tn = TableName.valueOf(tableName);
// 创建表信息对象
HTableDescriptor hTableDescriptor = new HTableDescriptor(tn);
// 判断表是否存在
if (admin.tableExists(tn)) {
System.out.println("表" + tableName + "已存在");
return;
}
// 添加表列族信息
Arrays.stream(cfs).forEach(x -> {
// 创建表列族对象
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(x);
// 添加到表信息中
hTableDescriptor.addFamily(hColumnDescriptor);
});
// 创建表
admin.createTable(hTableDescriptor);
System.out.println("表" + tableName + "创建成功");
}
/**
* 删除表
*
* @param tableName 表名
*/
public void deleteTable(String tableName) throws IOException {
// 管理器对象
Admin admin = connection.getAdmin();
// 创建表对象
TableName tn = TableName.valueOf(tableName);
// 判断表是否存在
if (!admin.tableExists(tn)) {
System.out.println("表" + tableName + "不存在");
return;
}
// 先禁用表
admin.disableTable(tn);
// 删除表
admin.deleteTable(tn);
System.out.println("表" + tableName + "删除成功");
}
/**
* 插入数据
*
* @param tableName 表名
*/
public void putData(String tableName, String path) throws IOException {
// 创建表名对象
TableName tn = TableName.valueOf(tableName);
// 创建表对象
Table table = connection.getTable(tn);
// 创建put集合
List<Put> puts = new ArrayList<>();
// 调用文件IO工具类
List<String[]> lists = FileUtils.fileInput(path);
lists.forEach(item -> {
Put put = new Put(Bytes.toBytes(item[0]));
put.addColumn(Bytes.toBytes("baseInfo"), Bytes.toBytes("name"),
Bytes.toBytes(item[1]));
put.addColumn(Bytes.toBytes("baseInfo"), Bytes.toBytes("age"),
Bytes.toBytes(item[2]));
put.addColumn(Bytes.toBytes("baseInfo"), Bytes.toBytes("gender"),
Bytes.toBytes(item[3]));
put.addColumn(Bytes.toBytes("addressInfo"), Bytes.toBytes("province"),
Bytes.toBytes(item[4]));
put.addColumn(Bytes.toBytes("addressInfo"), Bytes.toBytes("city"),
Bytes.toBytes(item[5]));
puts.add(put);
});
// 向表中插入数据
table.put(puts);
System.out.println("表插入数据成功!");
}
/**
* get方式查询数据
*
* @param tableName 表名
*/
public void getData(String tableName, String path) throws Exception {
// 创建表名对象
TableName tn = TableName.valueOf(tableName);
// 创建表对象
Table table = connection.getTable(tn);
// 创建get集合
List<Get> gets = new ArrayList<>();
List<String[]> lists = FileUtils.fileInput(path);
lists.forEach(item -> {
Get get = new Get(Bytes.toBytes(item[0]));
gets.add(get);
});
// 实际查询数据
Result[] results = table.get(gets);
// 对结果进行处理
for (Result result : results) {
System.out.println("===============================");
User user = ObjectAssignment.resultToObject(User.class, result);
System.out.println(user);
System.out.println("===============================");
}
}
/**
* scan方式查询数据
*
* @param tableName 表名
*/
public void scanData(String tableName, String family, String qualify, String queryCondition) throws Exception {
// 创建表名对象
TableName tn = TableName.valueOf(tableName);
// 创建表对象
Table table = connection.getTable(tn);
// 创建Scan对象
Scan scan = new Scan();
// 编写过滤器规则
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(family), Bytes.toBytes(qualify),
CompareFilter.CompareOp.EQUAL, Bytes.toBytes(queryCondition));
// 加载规则
scan.setFilter(filter);
// 接受结果
ResultScanner results = table.getScanner(scan);
System.out.println("***********************************");
for (Result result : results) {
User user = ObjectAssignment.resultToObject(User.class, result);
System.out.println(user);
}
System.out.println("***********************************");
}
/**
* 关闭连接
*
* @throws Exception 操作异常
*/
public void cleanUp() throws Exception {
connection.close();
}
// 测试相关功能方法
public static void main(String[] args) throws Exception {
HbaseUtils hbaseUtils = new HbaseUtils();
String path = "/home/job018/lixiang/hbase/data.txt";
String tableName = "codelx_java";
hbaseUtils.deleteTable(tableName);
hbaseUtils.createTable(tableName, "baseInfo", "addressInfo");
hbaseUtils.putData(tableName, path);
hbaseUtils.getData(tableName, path);
hbaseUtils.scanData(tableName,"baseInfo","name", "张一");
hbaseUtils.cleanUp();
}
}
8、经典问题分析
8.1、元数据管理问题
- hbase0.98版本及之前
- HBase的用-ROOT-表来记录.META.的Region信息,就和.META.记录用户表的Region信息一模一样
- -ROOT-表永远不会被分割,只会有一个Region
- Client端就需要先去访问-ROOT-表获取meta表的region信息,故首先要知道存储-ROOT-表的region的RegionServer的地址
- 客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。
- 如果客户端根据缓存信息还访问不到数据,则询问相关.META.表的Region服务器,试图获取数据的位置,如果还是失败,则询问-ROOT-表相关的.META.表在哪里。
- 最后,如果前面的信息全部失效,则通过ZooKeeper重新定位Region的信息。所以如果客户端上的缓存全部是失效,则需要进行6次网络来回,才能定位到正确的Region。
hbase0.98版本之后
背景
- HBase是三维有序存储,即rowkey(行键)、column key(column family和qualifier)、TimeStamp(时间戳-版本号)这个三个维度可以对HBase中的数据进行快速定位。
- rowkey设计必要性-避免热点问题
- 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。
- 大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,可能导致主机无法服务其他region的请求。
- 设计技巧
- 长度要越短越好,不要太长
- 数据持久化文件HFile中是按照KeyValue存储的,rowkey为其key,其它的值为其value,rowkey太长,会极大影响HFile的存储效率
- MemStore会缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统将不能缓存更多的数据,从而降低检索效率。
- rowkey散列原则
- rowkey是hbase数据的排序、划分region的主要依据,如果海量数据环境中,rowkey设计生成的值过于稠密,则会导致数据的集中于某个region上的存储,从而使对应的regionserver的负载过高。
- 很多人经常时间戳作为rowkey来设计,如果rowkey按照时间戳的方式递增,会经常导致大部分甚至所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别RegionServer上,造成热点问题,会降低查询效率
- 具体做法
- 第一种选择是可以将时间戳进行倒序后作为rowkey,即常见的rowkey串反转的作法。比较简单,但是失去了rowkey的可读性、有序性的意义。
- 建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率,即常见的加盐做法,可以有效避免热点问题。
- rowkey唯一原则
- rowkey是一行数据的唯一标识,必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的。
- 在设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,即将最近可能会被访问的数据放到一块。
- 这样更方便利用数据块集中加载、数据缓存加速等提升查询效率。
- 长度要越短越好,不要太长

若有收获,就点个赞吧
0 人点赞
