1、产生背景
- 随着互联网技术的发展,人们对实时流处理的需求增加
-
2、相关技术
在flink之前也出现了很多流数据处理引擎,包括storm/jstorm、 sparkstreaming等知名流⾏框架,但各⾃均有较明显的不⾜,导致没有达到理想的流处理引擎的标准要求
优秀流处理引擎标准要求
- 低延迟、⾼吞吐量、容错性、窗⼝时间语义化、编程效率⾼与 运⾏效果好的⽤户体验等主要⽅⾯。
- storm
- 优点:低延迟
- 缺点:其他要求都差一些
sparkstreaming
概念
- 用Java和Scala编写的框架和分布式处理引擎
- 用于对有界数据流(离线数据,也称批处理数据)和无界数据流(实时数据)进行有状态计算
- 特点
- 在所有常见集群中运行,以内存速度和任何规模执行计算
- 能够达到实时流处理引擎的全部标准要求
- 应用场景
- 要求严格的实时流处理场景
代码实现Source->Tansform->Sink
设计图
- 术语解释
- 物理部署层-deploy层
- 解决flink部署模式问题
- 支持多种部署模式本地部署、集群部署(Standalone/Yarn/Mesos)、云(GCE/EC2)以及kubernetes
- Runtime核⼼层
- 核心实现层,对上层接口提供基础服务
- ⽀持分布式Stream作业的执⾏、JobGraph到ExecutionGraph的映射转换以及任务调度等。
- 将DataStream和DataSet转成统⼀的可执⾏的TaskOperator,达到在流式计算引擎下同时处理批量计算和流式计算的⽬的。
- API & Libraries层
- 负责更好的开发⽤户体验,包括易⽤性、开发效率、执 ⾏效率、状态管理等⽅⾯
- 流计算应⽤的DataStream API
- 批处理应⽤的DataSet API
- 统⼀的API,⽅便⽤于直接操作状态和时间等底层数据
- 提供了丰富的数据处理⾼级API,例如Map、FllatMap操作等,并提供了⽐较低级的Process Function API
- 物理部署层-deploy层
- 运行模式
- 本地运行模式-local
- standalone模式-独⽴Flink集群
- 集群运行模式
- per-job模式
- 资源隔离性强,但是集群生命周期与提交的作业有关
- session模式
- 资源隔离性弱,但是集群生命周期与提交的作业无关
- application模式
- per-job和session的折中模式
- per-job模式
- 运行流程
- 运⾏时核⼼⻆⾊的⼯作流程
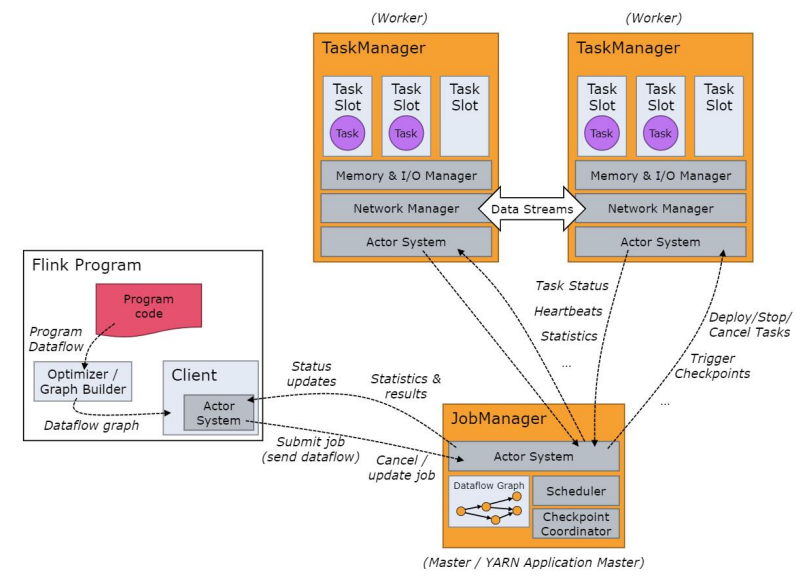
- actor system
- 各个⻆⾊组件互相通信的消息传递系统中间件。
- 唯⼀的缺点是不能实现真正意义上的并⾏
- 纯消息通信,实时性和粒度控制上会略弱于共享内 存的⽅式
- TaskManager
- (也称为 worker)执⾏作业流的task,并且缓存和交换数据流。
- 必须始终⾄少有⼀个 TaskManager。
- JobManager
- JobManager 具有许多与协调 Flink 应⽤程序的分布 式执⾏有关的职责,由三个组件组成
- Dispatcher
- Dispatcher 提供了⼀个 REST 接⼝,⽤来提交 Flink 应⽤程序执⾏,并为每个提交的作业启动 ⼀个新的 JobMaster。它还运⾏ Flink WebUI ⽤ 来提供作业执⾏信息。
- ResourceManager
- ResourceManager 负责 Flink 集群中的资源提 供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的最⼩单位
- JobMaster
- JobMaster 负责管理单个JobGraph的执⾏。
- 始终⾄少有⼀个 JobManager。
- Yarn模式提交任务的⼯作流程
- 运⾏时核⼼⻆⾊的⼯作流程



若有收获,就点个赞吧
0 人点赞
